VC R-CNN | 无监督的视觉常识特征学习(附源码)
计算机视觉研究院专栏
作者:Edison_G
最近CVPR不是在线直播,我关注了下,发现一篇很有意思的paper。让我想到在研究生有做过类似的算法——因果关系。今天我们看看这位作者是怎么处理的。
作者提出了一种新的无监督特征表示学习方法,即Visual Commonsense R-CNN(VC R-CNN),作为一种改进的视觉区域编码器,用于Captioning和VQA等高级任务。给定图像中检测到的一组目标区域(例如,使用FasterR-CNN),就像任何其他无监督的特征学习方法(例如Word2vec)一样,VC R-CNN的proxy训练目标是预测区域的上下文对象。
然而,它们从根本上是不同的:VC R-CNN的预测是通过因果干预:P(Y|do(X)),而另一些则是通过传统的likelihood:P(Y|X)。这也是为什么VC R-CNN可以学习“态势感知”知识的核心原因,就像椅子可以用来坐一样——而不仅仅是我们的“常识“,如果观察到桌子就很可能椅子也存在。

1.背景
首先先解释下论文为什么叫Visual Commonsense R-CNN(VC R-CNN)。其实在这篇论文idea构想的初期,作者查阅很多关于Commonsense常识的定义。结果发现从古至今,哲学界对这个概念一直呈现的是百家争鸣的现象,一直没有过一个准确的大家都认同的定义。而反观学术界,近几年来我们一直希望机器都够掌握人一样的常识用来处理问题,很多研究者也做了很多努力:比如从文本中挖掘常识[Yatskar, M., Ordonez, V., & Farhadi, A. (2016, June). Stating the obvious: Extracting visual common sense knowledge. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies]、构建数据库(Konwledge Base)当作常识[Wu, Q., Wang, P., Shen, C., Dick, A., & Van Den Hengel, A. (2016). Ask me anything: Free-form visual question answering based on knowledge from external sources. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition]等等。但是我们忽略了,很多常识可能根本无法通过文本或者数据库进行记录!

比如,会有人专门将“人是用腿走路的”“窗子在墙上”记录在课本里吗?但是这些都是常识呀。我们通过有限的文本或者数据库记录下的应该是“知识”或者“结构化的易于表达的常识”,但实际上,人类的,特别是视觉方面的常识要远远超过这一部分。
另一方面,不知道大家有没有思考过,为什么在NLP领域出现了很成功的word embedding方法,比如word2vec以及最近很火的BERT。但是在视觉领域,类Context Prediction任务却没有取得突破性的进展呢?

在这里我们希望通过常识这个角度来分析Vision和NLP的差别。在文本数据中,其实常识信息是被广泛而直接的记录在文本的context里面的,比如“鸟会飞”(大家想想,其实上一段的文本挖掘常识,构建数据库,他们的本质不就是文本嘛?)。但是在Vision下是完全不同的,我拍了一张人和椅子的照片,你从照片中只能看到人和椅子出现在了一起,但是其中没有“人可以坐在椅子上”这种信息,或者说仅仅通过在图片中预测context你压根无法学到视觉常识。这些都在迫使我们思考,我们有没有办法在现有标注条件下去学习常识呢?
最后我们想到了因果理论,我们能不能通过因果理论将CV中的视觉常识往前推进一点点呢?作者提到过,因果理论就是用来发现现象背后的不变规律的,是一种鲁棒的预测。这与常识本身不就很相似吗,我们人类也是从生活中不断总结积累这些不变的、鲁棒的经验或者因果规律,并把他们叫做常识。比如,看见凳子知道可以坐,看见pizza知道可以吃。
作者提出了一种新的Ghost模块,用于从简单的操作中获取更多的特征映射。基于一组内在特征映射,应用一系列简单的线性变换来生成许多Ghost特征映射,这些映射可以充分揭示内在特征的信息。提出的Ghost模块可以作为一个即插即用的组件来升级现有的卷积神经网络。Ghost瓶颈被设计成stack Ghost modules,然后可以很容易地建立轻量级的GhostNet。
2.引入主题
由于缺乏常识,不难发现机器所犯的“认知错误”。如下图所示,通过只使用视觉特征,例如当前流行的Up-Down的Faster R-CNN,机器通常无法描述确切的视觉关系(Captioning示例),或者,即使预测是正确的,潜在的视觉注意力也是不合理的(VQA示例)。

以前的工作将这归咎于数据集偏见,而没有进一步的理由,例如上图中的大概念共现差距;但在这里,我们通过欣赏“视觉”和“常识”特征之间的差异来仔细研究它。 由于“视觉”只告诉“什么”或“哪里”,它只是一个比其对应的英语单词更描述性的符号;当存在偏值时,例如,有更多的人而不是腿区域与“滑雪”一词共现,视觉注意力因此更有可能集中在人的区域。另一方面,如果我们可以使用“常识”特征,“滑雪”的动作可以集中在腿部区域,因为常识是:我们用腿滑雪。
我们当然不是第一个相信视觉特征应该包括更多常识性的知识,而不仅仅是视觉表象。 目前,有一种趋势是从大规模视觉语言语料库中获得弱监督学习特征。然而,尽管注释成本和含噪声的多模态对之间面临着重大挑战,但由于报告偏值,常识并不总是记录在文本中,例如,大多数人可能会说“人们在路上行走”,但很少有人会指出“人们用腿走路”。事实上,我们人类自然通过探索物理世界以无监督的方式学习常识,我们希望机器也能以这种方式模仿。
3.进入主题(VC R-CNN Framework)
然后让我们回到第二层级,干预。作者有详细介绍因果理论中的干预,有的同学可能会问了:那这一套Intervention理论该如何用到真实的CV世界中呢?首先让我们用一个toy experiment来引入,我们利用MSCOCO数据集(train2014)中已有的标注信息,简单计算出来Association(用因果之梯第一层级计算)和Intervention(用因果之梯第二层级计算) 之间的区别 。其实就是下面的两个公式:

其中 X, Y, z分别代表了图片中的目标标签,同时这里我们用物体出现的频率来代替概率,比如 就是用“含有Sink和Hair drier两者的图片数”比上“只含有Hair drier的图片数”计算得到的。我们画出两者计算结果差异的对比图(只标明了20类):
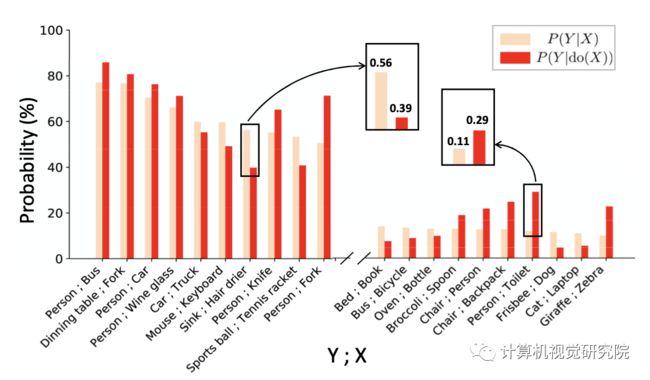
那这样的数值差距反映了什么呢,这里我们就挑选其中两个来举例(Sink, Hair drier以及Person, Toilet)来简单说明。

上面两个图例是作者随意从MSCOCO里找的例子。比如对于上图例,想要探寻在已知吹风机的情况下,去预测水池的可能性大小。因为在数据中有太多比如左图的例子了(也就是说在MSCOCO的大部分数据中,吹风机都是和水池共生在一起的),这就导致只用association计算出的数值比较高: 。而当我们按照confounder z进行分层分情况讨论,我们就会去看在z的条件下吹风机和水池之间实际的因果效应。这个过程中也可以被理解为,我们把场景因素考虑在内,对不同的场景进行分层(因为场景就是由object组成的),得到实际的因果效应,比单纯Association计算的数值要低: 。

同样的对于上图例,比如我们想去探寻“马桶”和“人”之间可能存在的因果效应。如果我直接整体的从数据集里进行Toilet和Person之间的共生统计(第一层级Association),因为数据集中人和马桶一起出现的样本其实不多,同时存在比较多马桶和其他东西共存的图片。比如右图在马桶旁边没有出现人,就会导致由马桶 -> 人计算出来的概率偏低一点。这时候如果想要做出更鲁棒的预测,我们就需要考虑混杂因子confounder, 比如瓶子、水池、杯子等等。按照confounder进行分层计算,最后再加权求和。
根据作者举得简单的例子的启发,我们可以把intervention的应用场景搬到了object detection任务中,并为intervention设计了一个proxy task:给定RoI X的feature去预测RoI Y的类别。我们知道周围的视觉世界是由很多物体组成的,其中也包括很多潜在的混杂因子,如果直接预测周围物体Y就不可避免的会被上文提到的混杂因子confounder所影响。根据我们刚刚介绍的“do算子”的理论,解决的办法也不难,只要能找到confounder然后对他们使用backdoor理论进行控制即可。那在我们这一套proxy task里面,混杂因子是什么呢?很明显,就像我举的例子里面说的,也一定是object。直觉上来说我们直接把整个数据集上的object RoI特征在每个类别上取平均,当作这个类别的表示,进而构建出一个类别数x1024的confounder字典作为Z(比如MSCOCO有80类,就是80x1024),它包含着所有可能的混杂因子。注意!这里的预测和以前object detection做的预测其实是有一定区别的,在这里我们强调加入causal intervention的预测是更加鲁棒的预测,我们希望能更加准确的度量X与周围物体之间的因果关系。

通过将图片中的上下两路进行对比我们可以看到,可以简单的把CV中的intervention(do calculus)理解为是一种“borrow&put”:
我们把confounder dictionary Z中的物体z“borrow”到当前图片中,注意这里的物体z不需要是当前图片中存在的,所以是一种global层面的定义;
然后把借来的z“put”到X, Y周围和X, Y对比,例如上图中的把 sink、handbag、chair等等移到 toilet 和 person 周围进行backdoor的计算。

最后我们把整个intervention整合成一路context predictor,同时为了不让网络忘掉识别RoI本身类别的能力,我们在context predictor的基础上又保留了原先的自身类别预测——self predictor。最后基于Faster R-CNN构造了VC R-CNN的框架,框架图如下:
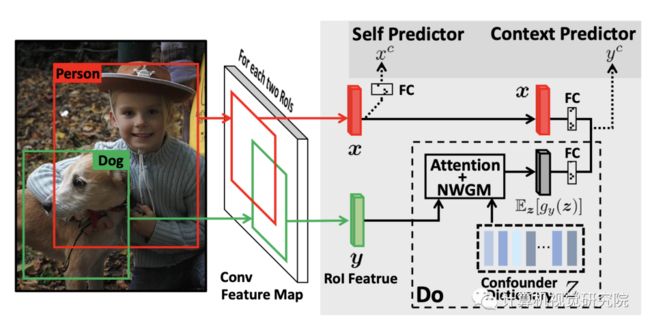
注意:作者提出的VC R-CNN的实现和原先的Faster R-CNN相比,去除了RPN网络(Region Proposal Network),不再训练网络propose边界框,而是直接将数据集ground-truth的bounding box坐标输入到其中,直接提取region的特征。而在训练完成后的feature提取阶段,相对应的,只要给定图片和bounding box坐标,都可以获得对应的VC特征。就这样,我们利用bottomup特征已有的边界框坐标提取VC特征后,将其并在先前的bottomup特征上作为新的特征。我们在传统的 Vision&Language 三大任务上挑选了经典model和SOTA model进行了测试,发现在各个任务上都取得了明显的提升,尤其是在image captioning上的提升尤其大。同时为了验证性能的提升不是由于参数增多带来的,我们还在原有特征上并上了ablative的特征(单独object特征,用correlation计算的特征),具体可以参考我们的论文的实验部分。
另一方面,我们也试图从t-SNE降维可视化的角度对我们的VC Feature进行实验。
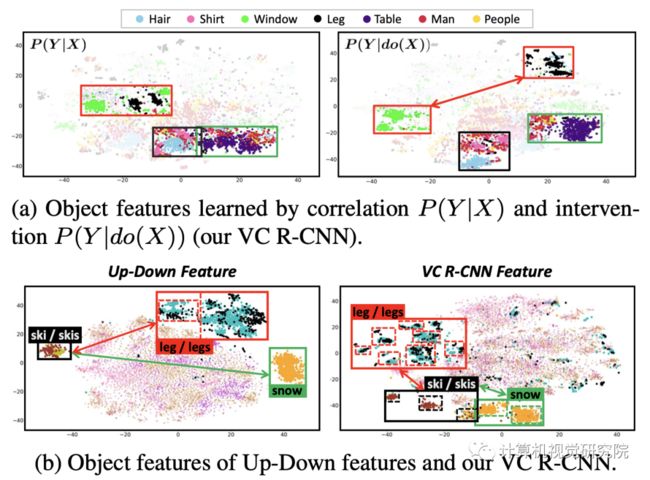
这个特征是作者选的5000个MSCOCO图,用t-SNE降维得到的,没有做过任何挑选,所以我觉得反映出来是具有一定普遍性的。我们可以发现,在每一种类别内部VC特征(右下)很明显的聚成一小块一小块,而不是像up-down直接聚成一大块。
这个很好理解,因为在前面的章节我们提到过,VC R-CNN在做intervention的时候可以理解为对周围的物体场景进行了分情况讨论,因此对于同一个object的区域,VC Feature具有更好的多面性(vary from context to context)。另外,在不同类别之间,VC更能显示出语义的相关性,比如对于ski和snow,leg,提出的VC明显在特征空间中相距的更近。
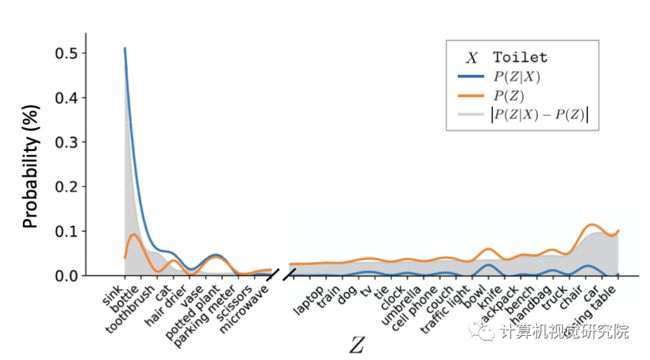
最后,作者想从一个high-level的角度来解释学到的VC Feature究竟是什么?VC R-CNN设计了一个预测周围物体的proxy task,通过这个task学习到的VC Feature就作为了干预武器的化身。这个化身能够让context prediction更鲁棒。相应的,是常识(比如,看见椅子想到人 不是因为数据中椅子和人的大量共生,而是由于人可以坐椅子),让我们在预测周围事物的时候更鲁棒。所以,我们类比这个feature为视觉常识。
最后来简单谈谈VC R-CNN的优点。
一方面,VC R-CNN从因果干预的角度出发,在一定程度上弥补了现如今很多特征及方法只依赖correlation、context所带来bias的缺陷。就比如CVPR2018提出的被 Vision & Language 领域广泛使用的Bottom-up特征,虽然没有去强行使用物体之间的context信息,但是忽略bias就还是有可能会引入bias,就比如体现在下游任务中attention不准的问题(说对了但是attention出错了)。面对这种bias,除了我们在model结构设计方面加以注意,又是否能从特征这一源头来辅助解决呢,这就是我们提出VC的很大motivation之一;
另一方面也解决了我在接触 Vision & Language 任务之后的一个疑惑,即大家广泛使用的bottom-up特征效果挺好,但是也只是encode了图片局部object的类别和属性信息,完全没有物体与物体互相之间的关系信息。那我们是否可以从这个角度对原有的bottom-up特征进行补充和完善呢?答案是显然的。而且VC R-CNN也不局限于某一个特征或者某一个数据集,配合上如今已经很方便的目标检测框架,使用者可以在任意数据集上进行训练,然后作为任意原始特征的补充。只要给定图片和bounding box坐标就可以进行VC Feature的提取。
还有一些具体使用层面的优点我就不一一列举了,比如使用方便、框架可以用于任何数据集等等。
4.实验

The image captioning performances of representative two models with ablative features on Karpathy split. The metrics: B4, M, R and C denote BLEU@4, METEOR, ROUGE-L and CIDEr- D respectively. The grey row highlight our features in each model. AoANet† indicates the AoANet without the refine encoder. Note that the Origin and Obj share the same results in MS-COCO and Open Images since they does not contain our new trained features

给出RoI特征x(红色框)和y(绿色框)的前3个混淆的可视化,而数字表示注意力权重。我们可以看到,模型可以识别合理的混杂因素z,例如公共上下文(黄色框)。

Experimental results on VCR with various visual features. ViLBERT† [41:Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In NIPS, 2019] denotes ViLBERT without pretraining process.

与使用Obj特征(左)相比,使用VC特征(右)的定性示例。图像中的方框表示注意力区域标签名称和注意权重的。三行分别表示Image Captioning、VQA和VCR任务。
5.总结
说了这么多,其实VC R-CNN也是作者把因果理论应用到general的CV问题中迈出的一步大胆的尝试。同时因为作者有限的个人精力以及self-supervised feature learning问题工作量大的特性,作者也没有办法把所有的model都拿过来尝试,不断往上刷分。在这里也希望各位同样深耕Vision&Language的同学,如果对作者的工作有兴趣可以尝试一下作者提出的Feature,如果有需要在其他训练集上训练VC Feature的也可以直接参考作者的代码,现在这个时代的目标检测框架已经非常友好,可以很方便的支持自定义数据集。
在此非常感谢作何的贡献,感谢!
作者论文:https://arxiv.org/abs/2002.12204
✄------------------------------------------------
如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注我们
公众号 : 计算机视觉战队
扫码回复:VC,获取下载链接