机器学习算法(一):决策树非递归实现方法及汽车购买推荐实例(上)
前言
本文将在决策树的算法基础上实现ID3,C45, CART决策树。
有关决策树的实例,网上已经有很多实例,但多是递归的实现形式。
递归的一个好处就是代码易于理解,坏处就是当数据量过大时及overfitting时
可能造成栈溢出,非递归的实现可以深入的去理解决策过程的数据分配,同时可以提高程序效率。基于此, 本文决策树的采用非递归实现, 主要包含如下内容:
1. ID3,C45, CART决策树的非递归实现
2. 决策树的非递归绘制
3. 实现离散及连续特征的混合决策树
4. 一个汽车购买推荐实例
本文由于篇幅问题分上下两文, 上文主要阐述1,2部门, 下文讲3,4 部分
决策树相关实现代码及数据已经放在github上, github链接如下:
https://github.com/JashonHuang/DecisionTree
决策树Common接口
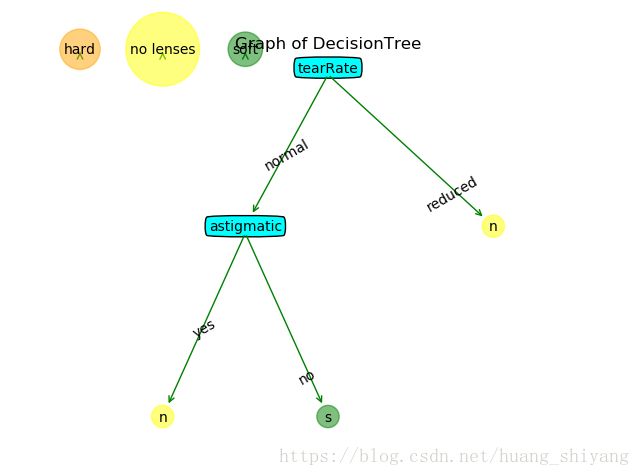
首先 , 我们用python dict来表示一棵决策树,如上图决策树可表示为
{'tearRate': {'reduced': 'no lenses', 'normal': {'astigmatic': {'yes': 'no lenses', 'no': 'soft'}}}}无论是ID3, C45还是CART, 都是DecisionTree, 它们拥有一些共同的接口函数,只是树的set up存在一些细节差异,因此
初始可以定义decisiontree, 其他类型的决策树继承该树, 如下定义:
class DecisionTree(object):
def __init__(self, data_set=list(), labels=list(), file_path=None, ops=(1, 0.001), encoding="utf-8"):
self.data_set = data_set
self.labels = labels
self.tree = dict()
# self._vec_nums = None
self._attr_nums = None
self.binary = False
self.err_cnt = 0.0
self.err_rate = 0.0
self.ops = ops
if file_path is not None:
self.load_data(file_path, encoding)
self.data_nums = len(self.data_set)
self.class_list = list(set([vec[-1] for vec in self.data_set]))在实现决策树算法前, 需要实现求树深度, 叶子数,及可视化, 这些都可以做为decisiontree的接口函数。
实现上述过程,一种方法是当然是通过递归实现, 另一种即本文主要探讨的非递归实现方法。其实这是很容易解决的, 利用层次遍历的思想, 就可容易地计算决策树的深度及叶子数。有关细节可参考如下二叉树的非递归实现这一文。
https://blog.csdn.net/huang_shiyang/article/details/79981332
这里仅是将二叉树扩展成一般树, 代码实现如下:
def get_depth(self):
if self.tree == {}:
return 0
tree_queue = [self.tree]
depth = 0
while len(tree_queue):
queue_len = len(tree_queue)
while queue_len:
queue_len = queue_len - 1
p_tree = tree_queue.pop(0)
node_label = list(p_tree.keys())[0]
for key in p_tree[node_label].keys():
if type(p_tree[node_label][key]).__name__ == "dict":
tree_queue.append(p_tree[node_label][key])
depth += 1
return depth + 1 # leaf node will not attend in queue , so the depth must plus 1
def get_leaf_nums(self):
if self.tree == {}:
return 0
tree_queue = [self.tree]
leaf_nums = 0
while len(tree_queue):
queue_len = len(tree_queue)
while queue_len:
queue_len = queue_len - 1
p_tree = tree_queue.pop(0)
node_label = list(p_tree.keys())[0]
for key in p_tree[node_label].keys():
if type(p_tree[node_label][key]).__name__ == "dict":
tree_queue.append(p_tree[node_label][key])
else:
leaf_nums += 1
return leaf_nums接下来, 对树的可视化, 如何画一颗决策树,也是用广度搜索优先的方法, 对于每个节点的位置如何放置,每个人会有不同的想法,重点是画得好看。 关于本文的决策树绘图代码如下, 重点如何实现, 后续再单独写一篇文章。这不是本文重点,所以此文带过。 有兴趣的同学也可以阅读下github源码。
def view_in_graph(self):
if self.tree == {}:
print("nothing to plot, back !")
return
height = self.get_depth()
width = self.get_leaf_nums()
tree_wh = {"height": height, "width": width}
tree_queue = [self.tree]
depth_level = 0
ax = nplt.draw_init(1)
class_num = len(self.class_list)
for ix in range(class_num):
coord_lgd = (ix/(2*class_num), 1)
nplt.plot_node(ax, self.class_list[ix], coord_lgd, coord_lgd, ix + 1) # leaf node legend
# init parent_point = (0.5, 0.95)
parent_point = (0.5, 0.95)
point_queue = [parent_point]
arrow_txt_queue = ['']
while len(tree_queue):
queue_len = len(tree_queue)
x_offset = -1.0 / (2 * tree_wh["width"])
while queue_len:
queue_len = queue_len - 1
p_tree = tree_queue.pop(0)
parent_point = point_queue.pop(0)
arrow_txt = arrow_txt_queue.pop(0)
leafn = get_leaf_ext(p_tree)
center_point = nplt.get_coord(x_offset, depth_level, leafn, tree_wh)
# print(center_point)
if leafn == 0: # 当前层的空点,其上层父节点是叶子节点, 将x_offset 偏移一个节点:
x_offset += 1 / tree_wh["width"]
if depth_level < tree_wh["height"]:
arrow_txt_queue.append('')
point_queue.append(center_point)
tree_queue.append({})
continue
if leafn == 1: # 当前层的叶节点,画叶节点, 将x_offset 偏移一个节点
node_style = self.class_list.index(str(p_tree)) + 1
# nplt.plot_node(ax, str(p_tree), center_point, parent_point, node_style)
nplt.plot_node(ax, str(p_tree)[0], center_point, parent_point, node_style)
nplt.plot_text(ax, center_point, parent_point, arrow_txt)
x_offset += 1 / tree_wh["width"]
if depth_level < tree_wh["height"] - 1:
arrow_txt_queue.append('')
point_queue.append(center_point)
tree_queue.append({})
continue
# 当前层的子树, 继续子节点/子树入队, 并画节点
node_label = list(p_tree.keys())[0]
nplt.plot_node(ax, node_label, center_point, parent_point, 0)
nplt.plot_text(ax, center_point, parent_point, arrow_txt)
x_offset += leafn / tree_wh["width"]
arrow_txt_queue2 = []
point_queue2 = []
tree_queue2 = []
for key in p_tree[node_label].keys(): # 让子树结构先进队再进子结点
if type(p_tree[node_label][key]).__name__ == "dict":
arrow_txt_queue.append(key)
point_queue.append(center_point)
tree_queue.append(p_tree[node_label][key])
else:
arrow_txt_queue2.append(key)
point_queue2.append(center_point)
tree_queue2.append(p_tree[node_label][key])
arrow_txt_queue.extend(arrow_txt_queue2)
point_queue.extend(point_queue2)
tree_queue.extend(tree_queue2)
depth_level += 1
nplt.show()ID3决策树
有关ID3决策树, 原理可见, 本文仅作简单陈述。
ID3原理
熵(Entropy)
在信息论中, 熵是表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其概率分布为
则随机变量的熵定义为
另外, 0log0=0 0 log 0 = 0 ,当对数的底为2时,熵的单位为bit;为e时,单位为nat。
从定义上可以看到:熵越大,随机变量的不确定性就越大,即则数据混合的种类越高,其蕴含的含义是一个变量可能的变化越多。对于一个只有一种类别的变量,其熵是最小的, 这也符合我们的认知。
条件熵(Conditional Entropy)
设有随机变量(X,Y),其联合概率分布为
条件熵 H(Y|X) H ( Y | X ) 表示在已知随机变量X的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵 H(Y|X) H ( Y | X ) ,定义为X给定条件下Y的条件概率分布的熵对X的数学期望, 有
信息增益(Information Gain)
假设现在有一个数据集 D D , 其有 m m 个特征, 在第i个特征下有 l l 个特征值,在每个特征值下,可以将数据拆分成
Di1,Di2,Di3,...,Dil D i 1 , D i 2 , D i 3 , . . . , D i l 对应数据占比是
其中 |D| | D | 表示D的样本数,那么第i个特征A 的条件熵可以表示为
定义信息增益:
显然信息增益比越大, 表示在该特征下, 数据能够更好地被分类。
因此ID3算法可以理解为, 对数据D选取最佳特征,使得数据按特征值(去掉特征所在列)切分后, 信息增益最大,得到子数据据, 对每个子数据集递归作同样的分析, 直到无特征可分或者类别统一停止该路决策过程。 非递归的实现方法就是,将最优特征对D拆分数据集,产生决策分支,如某一分支达到决策停止条件及产生决策结果,即生成节点,否则将对应数据集入队,同时决策树该节点指向空树,其进一步的决策分析由入队的子数据集进行产生决策。 循环直至队数据集为空(达到决策停止条件)
代码实现如下:
def set_up(self):
"""set up an ID3 DecisionTree in non-recursion way """
tree_queue = [self.tree]
data_queue = [self.data_set]
labels_queue = [self.labels.copy()] # use copy method , avoid being changed during deciding process
while len(tree_queue):
queue_len = len(tree_queue)
while queue_len:
queue_len = queue_len - 1
p_tree = tree_queue.pop(0)
data_set = data_queue.pop(0)
labels = labels_queue.pop(0)
best_feat = choose_best_feat_entropy(data_set, self.method)
best_feat_label = labels[best_feat]
p_tree[best_feat_label] = {}
del(labels[best_feat])
sub_labels = labels
res_data = split_data_entropy(data_set, best_feat) # get split data by best_feat feature
for son_label in res_data.keys():
son_val = get_class_value(res_data[son_label]) # if only one class return class else return dict()
p_tree[best_feat_label][son_label] = son_val
if type(son_val).__name__ == "dict":
tree_queue.append(p_tree[best_feat_label][son_label])
data_queue.append(res_data[son_label])
labels_queue.append(sub_labels.copy()) # use copy method , avoid being changed
# during deciding process
选择最优特征实现如下:
def choose_best_feat_entropy(data_set, method):
"""choose best feature with entropy method
# parm:
data_set: data_set to split
method : ID3, or C45"""
if method == "ID3":
calc_func = calc_info_gain
elif method == "C4.5":
calc_func = calc_info_gain_ratio
else:
return
best_info_gain = 0.0
best_feat = -1
base_ent = calc_entropy(data_set)
feat_nums = len(data_set[0]) - 1
for i in range(feat_nums):
info_gain = calc_func(base_ent, data_set, i)
if info_gain > best_info_gain:
best_info_gain = info_gain
best_feat = i
return best_feat数据切分如下:
def split_data_entropy(data_set, col):
"""split data in entropy method with feature col
# parm:
data_set: data_set to split
col : feature index"""
res_set = {}
for feat_vec in data_set:
# tmpLine = featVec[:col]
# tmpLine.extend(featVec[col + 1:])
res_vec = feat_vec[:col]
res_vec.extend(feat_vec[col+1:])
col_val = feat_vec[col]
if col_val not in res_set.keys():
res_set[col_val] = [res_vec]
else:
res_set[col_val].append(res_vec)
return res_setC45 决策树
信息增益比
以信息增益进行分类决策时,存在偏向于取值较多的特征的问题。于是为了解决这个问题人们有开发了基于信息增益比的分类决策方法,也就是C4.5。C4.5与ID3都是利用贪心算法进行求解,不同的是分类决策的依据不同。
因此,C4.5算法在结构与递归上与ID3完全相同,区别就在于选取决断特征时选择信息增益比最大的,即选择
基于此, 可以发现, C45与ID3基本一致,只是在选择最佳特征时,一个选择最佳增益,一个选择最佳增益比。代码这里就不再重复。
当数据特征不多时, ID3与C45的决策是一致的。以一个隐形眼镜数据集为例,数据如下
age,prescript,astigmatic,tearRate
young,myope,no,reduced,no lenses
young,myope,no,normal,soft
young,myope,yes,reduced,no lenses
young,myope,yes,normal,hard
young,hyper,no,reduced,no lenses
young,hyper,no,normal,soft
young,hyper,yes,reduced,no lenses
young,hyper,yes,normal,hard
pre,myope,no,reduced,no lenses
pre,myope,no,normal,soft
pre,myope,yes,reduced,no lenses
pre,myope,yes,normal,hard
pre,hyper,no,reduced,no lenses
pre,hyper,no,normal,soft
pre,hyper,yes,reduced,no lenses
pre,hyper,yes,normal,no lenses
presbyopic,myope,no,reduced,no lenses
presbyopic,myope,no,normal,no lenses
presbyopic,myope,yes,reduced,no lenses
presbyopic,myope,yes,normal,hard
presbyopic,hyper,no,reduced,no lenses
presbyopic,hyper,no,normal,soft
presbyopic,hyper,yes,reduced,no lenses
presbyopic,hyper,yes,normal,no lenses
该数据是引用《机器学习实战》的一个数据实例,它包含很多患者眼部状况的观察条件以及医生推荐的隐形眼镜类型。ID3与C45的分类结果如下:
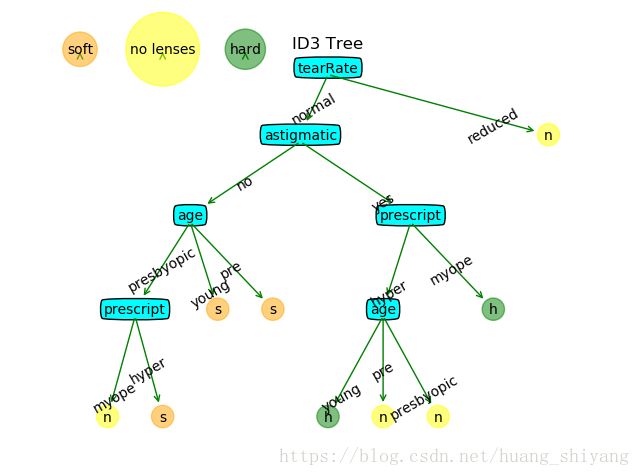
当然上述的结果存在过拟合现象, 下文在介绍完CART会介绍如何用测试数据判断并进行剪枝。
截至此, 上述的ID3, C45的特征都是离散, 如果连续的特征该怎么处理?或者一个数据里既有离散特征同时又有连续的特征该怎么处理, CART提供了实现的可能性。 目前基于CART的决策树如sklearn的DecisionTreeClassifier会将离散标签映射成连续值进行处理, 这是一个不错的方法,但是只实现了二分法, 对于离散特征失去了直观的表示方法。因此下文基于CART会实现混合离散值与连续值的决策树。
同时下文,将会以一个汽车购买实例, 以决策树分析的方式, 分析顾客最喜欢的汽车类型
未完待续。。。
参考:
MachineLearning in actiong