文章目录
- 0. 前言
- 1. 运行过程
- 2. 源码解析
- 2.1. 基本概念
- 2.2. 主函数
- 2.3. 将caffe模型转换为TensorRT可识别的形式
- 2.4. 模型推理
0. 前言
- 目标:在根据官方文档安装完后尝试测试一下TensorRT是否安装成功。
- 代码可以在
samples/sampleMNIST 中找到,也可以看 github 中对应路径。
- TODO:进一步理解模型推理过程中的
stream/buffer/context 等变量的含义。
1. 运行过程
- 以下过程可以参考 README.md 相关信息。
- 下文中
./ 指的是 tensorrt 所在路径,如 /home/ubuntu/TensorRT-6.0.1.5。
1.1. 数据准备
- 第一步:在 MNIST官网 下载数据训练数据
train-images-idx3-ubyte.gz 和 train-labels-idx1-ubyte.gz,并保存到 ./data/mnist 中。
- 第二步:通过
gzip -d xxx.gz 解压上面两个文件。
- 第三步:在
./data/mnist/ 目录下运行 python generate_pgms.py,生成若干 *.pgm 文件。
1.2. 代码编译与运行
- 第一步:在
./samples/sampleMNIST 目录下执行 make 命令。可执行文件生成在 ./bin/ 目录下。
- 第二步:在
./ 目录下运行 ./bin/sample_mnist 即可看到预期结果。
&&&& RUNNING TensorRT.sample_mnist # ./bin/sample_mnist
[06/06/2020-16:26:42] [I] Building and running a GPU inference engine for MNIST
[06/06/2020-16:26:48] [I] [TRT] Detected 1 inputs and 1 output network tensors.
[06/06/2020-16:26:48] [I] Input:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@:.%@@@@@
@@@@@@@@@@@@@@@%%%%* .@@@@@@
@@@@@@@@@@@%-::. =- :@@@@@@
@@@@@@@@@@@+ -. *@@@@@@
@@@@@@@@@@= -=@@# @@@@@@@
@@@@@@@@@@= .%@@%- +@@@@@@@
@@@@@@@@@@#. -@%: +@@@@@@@@
@@@@@@@@@@@- .*. +@@@@@@@@@
@@@@@@@@@@@= -%@@@@@@@@@
@@@@@@@@@@@+ :%@@@@@@@@@@
@@@@@@@@@@@- :@@@@@@@@@@@@
@@@@@@@@@@- :@@@@@@@@@@@@
@@@@@@@@%+ :- :@@@@@@@@@@@@
@@@@@@@@* +@* -@@@@@@@@@@@@
@@@@@@@# *@%. =@@@@@@@@@@@@
@@@@@@@= :@@+ +@@@@@@@@@@@@
@@@@@@@= :@* -@@@@@@@@@@@@@
@@@@@@@- -: *@@@@@@@@@@@@@@
@@@@@@@+ =@@@@@@@@@@@@@@@
@@@@@@@@+ :+@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[06/06/2020-16:26:48] [I] Output:
0:
1:
2:
3:
4:
5:
6:
7:
8: **********
9:
&&&& PASSED TensorRT.sample_mnist # ./bin/sample_mnist
2. 源码解析
2.1. 基本概念
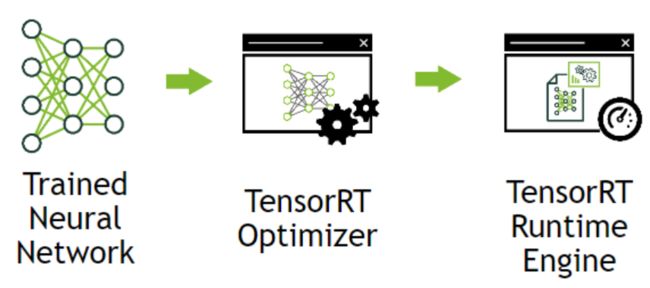
- 在几乎TensorRT MNIST笔记的文章中都有一张图:
- 这张图来自 TensorRT官方文档,用于介绍TensorRT的基本流程,也就是下面源码的基本流程。
- 第一步:将训练好的神经网络模型转换为TensorRT的形式,并用TensorRT Optimizer进行优化。
- 第二步:将在TensorRT Engine中运行优化好的TensorRT网络结构。
2.2. 主函数
- 主要作用:
- 解析输入参数。
- 构造
SampleMNIST 对象,调用相关方法实现Caffe模型转换、TensorRT Engine推理。
int main(int argc, char** argv)
{
samplesCommon::Args args;
bool argsOK = samplesCommon::parseArgs(args, argc, argv);
if (!argsOK)
{
gLogError << "Invalid arguments" << std::endl;
printHelpInfo();
return EXIT_FAILURE;
}
if (args.help)
{
printHelpInfo();
return EXIT_SUCCESS;
}
auto sampleTest = gLogger.defineTest(gSampleName, argc, argv);
gLogger.reportTestStart(sampleTest);
samplesCommon::CaffeSampleParams params = initializeSampleParams(args);
SampleMNIST sample(params);
gLogInfo << "Building and running a GPU inference engine for MNIST" << std::endl;
if (!sample.build())
{
return gLogger.reportFail(sampleTest);
}
if (!sample.infer())
{
return gLogger.reportFail(sampleTest);
}
if (!sample.teardown())
{
return gLogger.reportFail(sampleTest);
}
return gLogger.reportPass(sampleTest);
}
2.3. 将caffe模型转换为TensorRT可识别的形式
- 实现方式:通过主函数中的
sample.build() 实现。
build函数基本流程
- 主要工作就是,定义一个
network 对象,用于保存 caffe 模型转换后的结果。
- 猜测所谓的 Tensor Optimizer 就是在
builder->buildEngineWithConfig 中实现的。
bool SampleMNIST::build()
{
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger.getTRTLogger()));
if (!builder)
return false;
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetwork());
if (!network) return false;
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config) return false;
auto parser = SampleUniquePtr<nvcaffeparser1::ICaffeParser>(nvcaffeparser1::createCaffeParser());
if (!parser) return false;
constructNetwork(parser, network);
builder->setMaxBatchSize(mParams.batchSize);
config->setMaxWorkspaceSize(16_MiB);
config->setFlag(BuilderFlag::kGPU_FALLBACK);
config->setFlag(BuilderFlag::kSTRICT_TYPES);
if (mParams.fp16) config->setFlag(BuilderFlag::kFP16);
if (mParams.int8) config->setFlag(BuilderFlag::kINT8);
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(builder->buildEngineWithConfig(*network, *config), samplesCommon::InferDeleter());
if (!mEngine) return false;
assert(network->getNbInputs() == 1);
mInputDims = network->getInput(0)->getDimensions();
assert(mInputDims.nbDims == 3);
return true;
}
- caffe模型转换具体实现过程
- 其实模型转换本身,
parser->parse 一个函数就解决了。
- 下面代码的大量篇幅是在:在模型开头添加
输入图片减去平均数 操作上。
void SampleMNIST::constructNetwork(SampleUniquePtr<nvcaffeparser1::ICaffeParser>& parser, SampleUniquePtr<nvinfer1::INetworkDefinition>& network)
{
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(
mParams.prototxtFileName.c_str(),
mParams.weightsFileName.c_str(),
*network,
nvinfer1::DataType::kFLOAT);
for (auto& s : mParams.outputTensorNames)
{
network->markOutput(*blobNameToTensor->find(s.c_str()));
}
nvinfer1::Dims inputDims = network->getInput(0)->getDimensions();
mMeanBlob = SampleUniquePtr<nvcaffeparser1::IBinaryProtoBlob>(parser->parseBinaryProto(mParams.meanFileName.c_str()));
nvinfer1::Weights meanWeights{nvinfer1::DataType::kFLOAT, mMeanBlob->getData(), inputDims.d[1] * inputDims.d[2]};
float maxMean = samplesCommon::getMaxValue(static_cast<const float*>(meanWeights.values), samplesCommon::volume(inputDims));
auto mean = network->addConstant(nvinfer1::Dims3(1, inputDims.d[1], inputDims.d[2]), meanWeights);
mean->getOutput(0)->setDynamicRange(-maxMean, maxMean);
network->getInput(0)->setDynamicRange(-maxMean, maxMean);
auto meanSub = network->addElementWise(*network->getInput(0), *mean->getOutput(0), ElementWiseOperation::kSUB);
meanSub->getOutput(0)->setDynamicRange(-maxMean, maxMean);
network->getLayer(0)->setInput(0, *meanSub->getOutput(0));
samplesCommon::setAllTensorScales(network.get(), 127.0f, 127.0f);
}
2.4. 模型推理
- 主要工作:就是将转换好的模型在tensorrt engine上跑一边。
- 主要通过
infer() 函数完成,本函数的主要操作就是:
- 读取输入数据(
processInput)。
- 通过 cuda stream / buffer 等进行推理。
- 判断输出结果是否正确(
verifyOutput)。
bool SampleMNIST::infer()
{
samplesCommon::BufferManager buffers(mEngine, mParams.batchSize);
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
return false;
}
srand(time(NULL));
const int digit = rand() % 10;
assert(mParams.inputTensorNames.size() == 1);
if (!processInput(buffers, mParams.inputTensorNames[0], digit))
{
return false;
}
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
buffers.copyInputToDeviceAsync(stream);
if (!context->enqueue(mParams.batchSize, buffers.getDeviceBindings().data(), stream, nullptr))
{
return false;
}
buffers.copyOutputToHostAsync(stream);
cudaStreamSynchronize(stream);
cudaStreamDestroy(stream);
assert(mParams.outputTensorNames.size() == 1);
bool outputCorrect = verifyOutput(buffers, mParams.outputTensorNames[0], digit);
return outputCorrect;
}
bool SampleMNIST::processInput(const samplesCommon::BufferManager& buffers, const std::string& inputTensorName, int inputFileIdx) const
{
const int inputH = mInputDims.d[1];
const int inputW = mInputDims.d[2];
srand(unsigned(time(nullptr)));
std::vector<uint8_t> fileData(inputH * inputW);
readPGMFile(locateFile(std::to_string(inputFileIdx) + ".pgm", mParams.dataDirs), fileData.data(), inputH, inputW);
gLogInfo << "Input:\n";
for (int i = 0; i < inputH * inputW; i++)
{
gLogInfo << (" .:-=+*#%@"[fileData[i] / 26]) << (((i + 1) % inputW) ? "" : "\n");
}
gLogInfo << std::endl;
float* hostInputBuffer = static_cast<float*>(buffers.getHostBuffer(inputTensorName));
for (int i = 0; i < inputH * inputW; i++)
{
hostInputBuffer[i] = float(fileData[i]);
}
return true;
}
bool SampleMNIST::verifyOutput(const samplesCommon::BufferManager& buffers, const std::string& outputTensorName, int groundTruthDigit) const
{
const float* prob = static_cast<const float*>(buffers.getHostBuffer(outputTensorName));
gLogInfo << "Output:\n";
float val{0.0f};
int idx{0};
const int kDIGITS = 10;
for (int i = 0; i < kDIGITS; i++)
{
if (val < prob[i])
{
val = prob[i];
idx = i;
}
gLogInfo << i << ": " << std::string(int(std::floor(prob[i] * 10 + 0.5f)), '*') << "\n";
}
gLogInfo << std::endl;
return (idx == groundTruthDigit && val > 0.9f);
}