【论文笔记】Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction
https://arxiv.org/pdf/1802.08714
本文的目的是出租车需求预测,特点在于结合了时间、空间、语义三方面的信息,深度学习模型
-
- 前言
- 本文贡献
- 参数定义
- DMVST-Net框架
- 空间视角:局部CNN
- 时间视角:LSTM
- 语义视角:结构嵌入
- 损失函数
- 实验
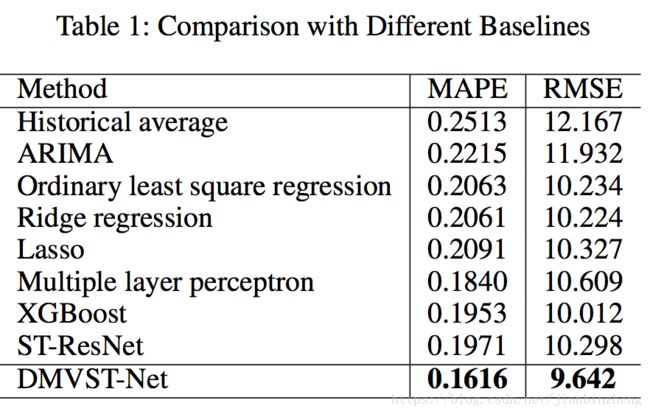
- 算法对比:
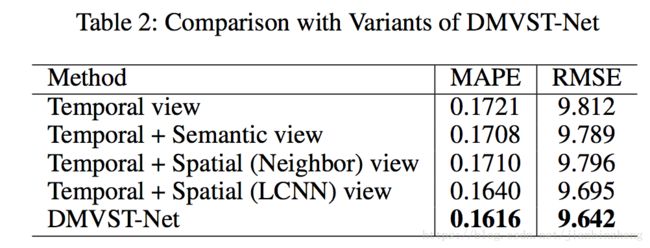
- 组合对比
- 非常重要的一张图
- 前言
前言
简单来说,本文综合了时间、空间、语义三个方面预测需求量。
空间:local CNN,强调了邻近空间相似,较远的位置参与训练之间会有负作用
时间:使用比较传统LSTM来做
语义:使用“区域图”的边来表达区域对间需求模式的相似性,用graph embedding的方法作为环境特征参与训练
本文贡献
- 提出了一种综合多视角的模型,综合考虑空间、时间、语义关系
- 提出局部CNN模型,用于捕捉邻近区域间的局部特征
- 使用基于需求相似性的区域图结果建模相似但不相邻的区域
- 用滴滴出行的大数据做实验
参数定义
不重叠的区域: L={l1,l2,...,li,,lN} L = { l 1 , l 2 , . . . , l i , , l N }
时间间隔: ={I0,I1,...,It,...,IT} L = { I 0 , I 1 , . . . , I t , . . . , I T } ,每段30min
出租车请求:一个请求为 o,(o.t,o.l,o.u) o , ( o . t , o . l , o . u ) ,分别表示时间、位置、用户id,并用用户id过滤重复请求
需求:定义为在一个位置、每个时间点对出租车的需求量。 yit=|{o:o.t∈It∧o.l∈li}| y t i = | { o : o . t ∈ I t ∧ o . l ∈ l i } | 。其中 |⋅| | ⋅ | 表示集合,后续 t t 表示 It I t , i i 表示 li l i
需求预测问题:已知到t时刻的数据,预测t+1时刻的需求量
eit∈ℝr e t i ∈ R r 表示位置i在时间t的特征向量,r是特征个数
Lt−h,...,t Y t − h , . . . , t L 表示历史的需求
εLt−h,...,t ε t − h , . . . , t L 表示所有位置L,在时间段[t-h,t]之间的环境特征
(⋅) F ( ⋅ ) 是预测函数,捕捉信息
DMVST-Net框架
Deep Multi-View Spatial-Temporal Network
空间视角:局部CNN
首先说明:图像范围太大的话,包含了弱相关区域,会有负效果;根据地理学第一定律,只取邻近区域作为空间表示。
取S*S大小图像表示空间特征,则维度为S*S*1,卷积过程为
为激活函数添加约束
K层卷积之后 Yi,Kt∈S×S×λ Y t i , K ∈ R S × S × λ ,添加flatten层再全连接降维得到空间表示
时间视角:LSTM
一堆很复杂的描述,看不懂,大概意思就是把上述不同时序CNN出来的结果混上天气等特征一起时序LSTM
语义视角:结构嵌入
核心:相似的区域不一定相邻
定义一个位置图结构 G=(V,E,D) G = ( V , E , D ) ,每个位置作为结点,结点之间两两成边全连接,D是相似性, V=L,E∈V×V V = L , E ∈ V × V ,D由DTW加衰减计算得到,公式:
用周平均的小时需求序列作为需求模式。另外,用graph embedding的方法(LINE)为每个结点构建一个嵌入向量 mi m i ,再加入全连接层
损失函数
mean square error更倾向于较大数值的预测,为了解决这个问题,加入了“最小化mean absolute percentage loss
实验
2017年2月1日—2017年3月19日训练,3月20日—3月26日预测,取半小时/一小时时间间隔,预测时取前8小时数据预测后续几个时间片的数据
算法对比:
Historical average
ARIMA
LR
MLP
XGBoost
ST-ResNet
组合对比
Temporal view
Temporal view+Semantic view
Temporal view+Spatial(Neighbors) view
Temporal view+Spatial(LCNN) view
DMVST-Net
非常重要的一张图
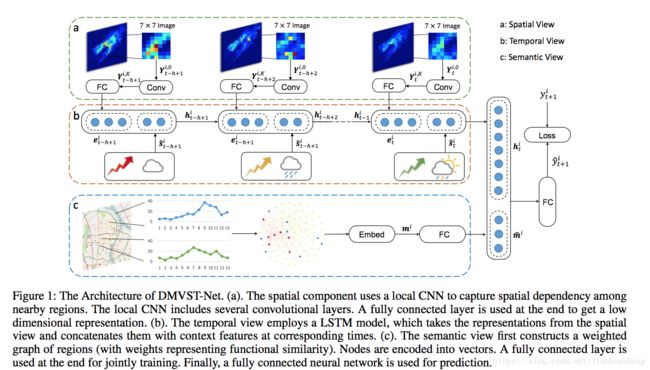
就这上面概述的理解。a是空间,b是时间,c是语义。
空间部分,取邻域的需求情况用LCNN的方式“提特征”、“embedding”
时间部分,将每个时间片的空间特征和天气等其他特征LSTM,构成时空的Embedding
语义特征,表达不同空间区域的需求变化趋势一致性,进行graph embedding,得到空间不相邻的语义相似性
最后,基于上述三个部分给出的embedding向量,全连接输出