一、信息提取
信息有很多种形状和大小。一个重要的形式是结构化数据:实体和关系的可预测的规范的结构。
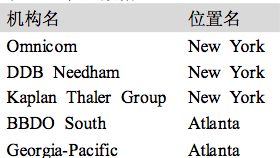
如果这个位置数据被作为一个元组(entity, relation, entity)的链表存储在 Python 中,那么这个问题:“哪些组织在亚特兰大经营?” 可翻译如下:
print [org for (e1, rel, e2) if rel=='IN' and e2=='Atlanta']
>> ['BBDO South', 'Georgia-Pacific']
但如果尝试从文本中获得相似的信息,事情就比较麻烦了。所以,需要采取不同的方法,提前定为我们将只查找文本中非常具体的各种信息,如:组织和地点之间的关系。
首先将自然语言句子这样的非结构化数据转换成上图的结构化数据。然后,利用强大的查询工具,如 SQL。这种从文本获取意义的方法被称为信息提取。
信息提取有许多应用,包括商业智能、简历收获、媒体分析、情感检测、专利检索、电子邮件扫描。当前研究的一个特别重要的领域是提取出电子科学文献的结构化数据,特别是在生物学和医学领域。
1. 信息提取结构
处理文档:首先,使用句子分割器将该文档的原始文本分割成句,使用分词器将每 个句子进一步细分为词。接下来,对每个句子进行词性标注,在下一步命名实体识别中将证明这是非常有益的。在这一步,我们寻找每个句子中提到的潜在的有趣的实体。最后,我们使用关系识别搜索文本中不同实体间的可能关系。

要执行前面三项任务,我们可以定义一个函数,简单地连接 NLTK 中默认的句子分割器,分词器和词性标注器:
def ie_preprocess(document):
sentences = nltk.sent_tokenize(document)
sentences = [nltk.word_tokenize(sent) for sent in sentences]
sentences = [nltk.pos_tag(sent) for sent in sentences]
接下来,命名实体识别中,分割和标注可能组成一个有趣关系的实体。通常情况下,这些将被定义为名词短语,例如the knights who say "ni"或者适当的名称如Monty Python。在一些任务中,同时考虑不明确的名词或名词块也是有用的,如every student或cats,这些不必要一定与确定的NPs和适当名称一样的方式指示实体。
最后,在提取关系时,我们搜索对文本中出现在附近的实体对之间的特殊模式,并使用这些模式建立元组记录实体之间的关系。
二、分块
词块划分是实体识别的基本技术,它分割和标注多词符的序列。如下图所示:
小框显示词级分词和词性标注,大框显示高级别的词块划分。每个这种较大的框叫做一个词块。就像分词忽略空白符,词块划分通常选择词符的一个子集。同样像分词一样,词块划分器生成的片段在源文本中不能重叠。
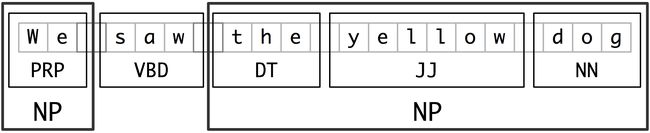
1. 名词短语词块划分
首先思考名词短语词块划分或NP词块划分任务,在那里寻找单独名词短语对应的词块。例如,这里是一些《华尔街日报》文本,其中的NP词块用方括号标记:
sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),
("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
grammar = "NP: {?*}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print(result)
result.draw()
>> (S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))

2. 标记模式
组成一个词块语法的规则使用标记模式来描述已标注的词的序列。一个标记模式是一个词性标记序列,用尖括号分隔,如
# 来自《华尔街日报》的名词短语
another/DT sharp/JJ dive/NN
trade/NN figures/NNS
any/DT new/JJ policy/NN measures/NNS
earlier/JJR stages/NNS
Panamanian/JJ dictator/NN Manuel/NNP Noriega/NNP
3. 用正则表达式进行词块划分
要找到一个给定的句子的词块结构,RegexpParser词块划分器以一个没有词符被划分的平面结构开始。词块划分规则轮流应用,依次更新词块结构。一旦所有的规则都被调用,返回生成的词块结构。
grammar = r"""
NP: {?*} # chunk determiner/possessive, adjectives and noun
{+} # chunk sequences of proper nouns
"""
cp = nltk.RegexpParser(grammar)
sentence = [("Rapunzel", "NNP"), ("let", "VBD"), ("down", "RP"),
("her", "PP$"), ("long", "JJ"), ("golden", "JJ"), ("hair", "NN")]
print(cp.parse(sentence))
>> (S
(NP Rapunzel/NNP)
let/VBD
down/RP
(NP her/PP$ long/JJ golden/JJ hair/NN))
PS: $符号是正则表达式中的一个特殊字符,必须使用反斜杠转义来匹配PP$标记。
如果标记模式匹配位置重叠,最左边的匹配优先。
例如,如果应用一个匹配两个连续的名词文本的规则到一个包含三个连续的名词的文本,则只有前两个名词将被划分:
nouns = [("money", "NN"), ("market", "NN"), ("fund", "NN")]
grammar = "NP: {} # Chunk two consecutive nouns"
cp = nltk.RegexpParser(grammar)
print(cp.parse(nouns))
>> (S (NP money/NN market/NN) fund/NN)
4. 探索文本语料库
cp = nltk.RegexpParser('CHUNK: { }')
brown = nltk.corpus.brown
for sent in brown.tagged_sents():
tree = cp.parse(sent)
for subtree in tree.subtrees():
if subtree.label() == 'CHUNK': print(subtree)
>> (CHUNK combined/VBN to/TO achieve/VB)
(CHUNK continue/VB to/TO place/VB)
(CHUNK serve/VB to/TO protect/VB)
(CHUNK wanted/VBD to/TO wait/VB)
(CHUNK allowed/VBN to/TO place/VB)
(CHUNK expected/VBN to/TO become/VB)
···
5. 词缝加塞
有时定义我们想从一个词块中排除什么比较容易。我们可以定义词缝为一个不包含在词块中的一个词符序列。在下面的例子中,barked/VBD at/IN是一个词缝:
[ the/DT little/JJ yellow/JJ dog/NN ] barked/VBD at/IN [ the/DT cat/NN ]
加缝隙是从一大块中去除一个标识符序列的过程。如果匹配的标识符序列贯穿一整块, 那么这一整块会被去除;如果标识符序列出现在块中间,这些标识符会被去除,在以前只有 一个块的地方留下两个块。如果序列在块的周边,这些标记被去除,留下一个较小的块。

三、开发和评估分块器
使用corpus模块,我们可以加载已经标注并使用IOB符号划分词块的《华尔街日报》文本。这个语料库提供的词块类型有NP,VP和PP。正如我们已经看到的,每个句子使用多行表示,如下所示:
he PRP B-NP
accepted VBD B-VP
the DT B-NP
position NN I-NP
...

可以使用NLTK的corpus模块访问较大量的已经划分词块的文本。CoNLL2000语料库包含27万词的《华尔街日报文本》,分为“训练”和“测试”两部分,标注有词性标记和IOB格式词块标记。我们可以使用nltk.corpus.conll2000访问这些数据。下面是一个读取语料库的“训练”部分的第100个句子的例子:
>>> from nltk.corpus import conll2000
>>> print(conll2000.chunked_sents('train.txt')[99])
(S
(PP Over/IN)
(NP a/DT cup/NN)
(PP of/IN)
(NP coffee/NN)
,/,
(NP Mr./NNP Stone/NNP)
(VP told/VBD)
(NP his/PRP$ story/NN)
./.)
CoNLL2000语料库包含三种词块类型:NP词块、VP词块如has already delivered和PP块如because of。
>>> print(conll2000.chunked_sents('train.txt', chunk_types=['NP'])[99])
(S
Over/IN
(NP a/DT cup/NN)
of/IN
(NP coffee/NN)
,/,
(NP Mr./NNP Stone/NNP)
told/VBD
(NP his/PRP$ story/NN)
./.)
五、命名实体识别
命名实体是确切的名词短语,指示特定类型的个体,如组织、人、日期等。
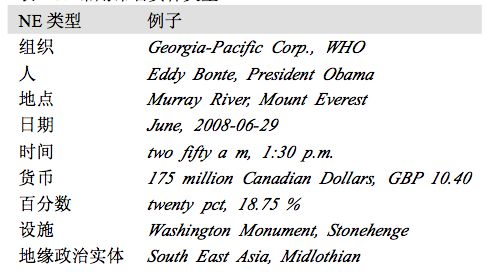
命名实体识别(NER)系统的目标是识别所有文字提及的命名实体。可以分解成两个子 任务:确定 NE 的边界和确定其类型。命名实体识别经常是信息提取中关系识别的前奏,它 也有助于其他任务。
六、关系抽取
一旦文本中的命名实体已被识别,我们就可以提取它们之间存在的关系。如前所述,我们通常会寻找指定类型的命名实体之间的关系。进行这一任务的方法之一是首先寻找所有X, α, Y)形式的三元组,其中X和Y是指定类型的命名实体,α表示X和Y之间关系的字符串。然后我们可以使用正则表达式从α的实体中抽出我们正在查找的关系。下面的例子搜索包含词in的字符串。特殊的正则表达式(?!\b.+ing\b)是一个否定预测先行断言,允许我们忽略如success in supervising the transition of中的字符串,其中in后面跟一个动名词。