Neo4j 数据导入案例NorthWind load csv
介绍如何从关系数据库,以csv的文件格式,导入数据到neo4j数据库。重点理解关系数据库和图形数据库建模的联系。
一、 Northwind 数据库介绍
社区版本的数据样例,主要用来练习sql语句的查询。有较为丰富的表结构和复杂的 关联关系。

两个核心思想
- 列row代表一个节点node
- 一个表table代表一个标签lable
二、数据导入
1,load csv命令导入数据
dbms.directories.import=import 配置文件该参数表示load csv的默认访问路径在import文件夹下面
参考:neo4j server\neo4j-community-3.5.0\import
点击csv文件下载链接
下载后把数据放在import文件夹下,执行以下命令创建角色节点
// Create customers
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/customers.csv" AS row
CREATE (:Customer {companyName: row.CompanyName, customerID: row.CustomerID, fax: row.Fax, phone: row.Phone});
// Create products
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/products.csv" AS row
CREATE (:Product {productName: row.ProductName, productID: row.ProductID, unitPrice: toFloat(row.UnitPrice)});
// Create suppliers
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/suppliers.csv" AS row
CREATE (:Supplier {companyName: row.CompanyName, supplierID: row.SupplierID});
// Create employees
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/employees.csv" AS row
CREATE (:Employee {employeeID:row.EmployeeID, firstName: row.FirstName, lastName: row.LastName, title: row.Title});
// Create categories
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/categories.csv" AS row
CREATE (:Category {categoryID: row.CategoryID, categoryName: row.CategoryName, description: row.Description});
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/orders.csv" AS row
MERGE (order:Order {orderID: row.OrderID}) ON CREATE SET order.shipName = row.ShipName;
解释:
- periodic commit 指示Neo4j在执行完一定行数后提交数据再继续,默认执行1000行,即每1000行提交一次
- WITH HEADERS 表示input文件第一行是header,而不是数据。可以用header的字段选择插入
- AS row,row是标识符代表了一列。 row.header字段名代表字段值,可以给属性动态赋值。
总结:请理解一行数据代表一个节点,一个表文件代表一个角色label。
2、 建立索引
通过上面语句建立了大量的彼此之间毫无联系的节点。为了加快建立关系速度,给所有节点加上索引。
CREATE INDEX ON :Product(productID);
CREATE INDEX ON :Product(productName);
CREATE INDEX ON :Category(categoryID);
CREATE INDEX ON :Employee(employeeID);
CREATE INDEX ON :Supplier(supplierID);
CREATE INDEX ON :Customer(customerID);
CREATE INDEX ON :Customer(customerName);
#以在NODE或关系的属性上创建唯一约束。
CREATE CONSTRAINT ON (o:Order) ASSERT o.orderID IS UNIQUE;
3 创建节点间关系
3.1 建立order和product,customer,employee关系
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (product:Product {productID: row.ProductID})
MERGE (order)-[pu:PRODUCT]->(product)
ON CREATE SET pu.unitPrice = toFloat(row.UnitPrice), pu.quantity = toFloat(row.Quantity);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (employee:Employee {employeeID: row.EmployeeID})
MERGE (employee)-[:SOLD]->(order);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (customer:Customer {customerID: row.CustomerID})
MERGE (customer)-[:PURCHASED]->(order);
解释
- 加载order文件,找到order和product的所有节点。这里的match不是匹配而是查找的意思
- 创建order和product的关系为PRODUCT
- SET 设置属性,为关系设置属性

3.2 创建products, suppliers,categories的关系
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (supplier:Supplier {supplierID: row.SupplierID})
MERGE (supplier)-[:SUPPLIES]->(product);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (category:Category {categoryID: row.CategoryID})
MERGE (product)-[:PART_OF]->(category);
3.3 创建员工和管理者的关系
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:/employees.csv" AS row
MATCH (employee:Employee {employeeID: row.EmployeeID})
MATCH (manager:Employee {employeeID: row.ReportsTo})
MERGE (employee)-[:REPORTS_TO]->(manager);
表中两列的关系
结果查询
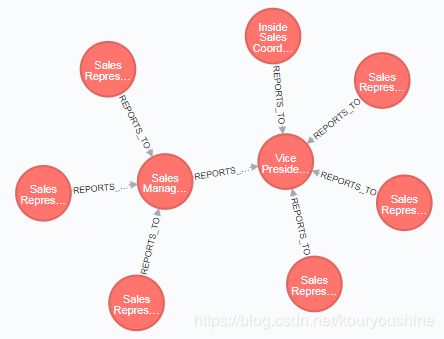
1,返回员工和经理报告层级
match (employee:Employee) -[:REPORTS_TO]-> (manager:Employee) return employee,manager
2,找到所有卖过巧克力的人以及销量
match(employee:Employee ) -[:SOLD]->(ord:Order) -[:PRODUCT]-> (product:Product {productName:"Chocolade"}) return employee.firstName,count ( ord) AS ords
总结
- 以上可以看出关系型数据库和图形数据库是如何转化的。但个人不推荐使用图形数据库来做上述查询,我们都很清楚关系型数据库可以很轻松达成如上功能。随着业务复杂度的提高,图形数据库使用起来会越来越复杂。二关系型数据库可以对业务拆解,有更好的效率。
- 图形数据库适合处理关系相关的业务逻辑
- 重点是通过这个案例理解图形数据库如何建立模型和处理数据的。
官网参考,适合喜欢英语阅读的人