——JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
了解爬虫中数据的分类
在爬虫爬取的数据中有很多不同类型的数据,我们需要了解数据的不同类型来又规律的提取和解析数据
结构化数据:json,xml等
处理方式:直接转化为python类型非结构化数据:HTML
处理方式:正则表达式、xpath
介绍结构化数据和非结构化数据
- 结构化数据例子:
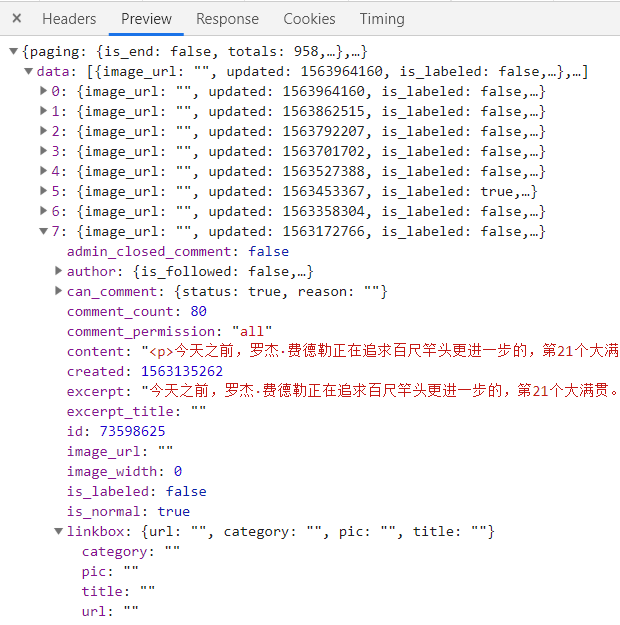
- 非结构化数据例子:

我们看结构化数据:像极了字典!
json是什么?
在Python语言当中,json是一种特殊的字符串,这种字符串特殊在它的写法——它是用列表/字典的语法写成的。
json和html一样,常用来做网络数据传输。它存在于在Network-XHR里,严格来说其实它不是列表/字典,它是json。
json数据如何查找?
1. chrome 开发者工具:F12
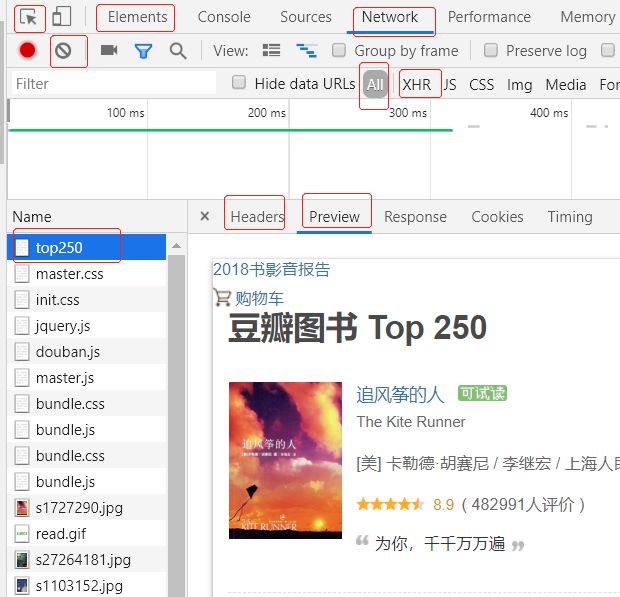
各面板说明:
Element :查找网页源代码HTML中元素,实时在浏览器里面得到反馈
Network:实时网络请求的记录
All:查看全部
top250 :这是豆瓣图书top250第0个请求
Headers :该资源的HTTP头信息
Preview :根据你选择的资源类型(JSON、图片、文本)显示相应的预览
Response:响应信息面板包含资源还未进行格式处理的内容
HXR :一种不借助网页刷新即可传输数据的对象
分析网页时,先判断提取的数据在HTML中,还是Json中
点开Nekwork → All → 第0个请求,看Preview(优先)或Response,看看里面有没有我们想要的信息,有的话数据就在html源代码中,否则数据在json中,要去看XHR
如上图,我们在豆瓣图书T250的第0个请求可以看到书本信息,那么书本信息就在html源代码中
2. json数据查找方法
打开开发者工具,选中选中XHR面板
刷新页面,逐个查看Preview(预览),看看有没有我们想要的
如果刷新后出来的数量过多,可以清空所有,点下一页,去看下一页的预览
如果没有看到本页的数据,但可以看到类似的数据,那么它应该是下一页的数据,就是本页加载下一页的,按照这个逻辑,那么第一页的数据如何获取呢?
获取第一页的数据,我们先去第三页(之后的页数都可以),
刷新第三页 →清空 →点开第一页,这样一般可以拿到第一页和第二页的数据如果是影音,还要点击播放按钮,才加载出来
json数据如何解析?
实例展示:提取知乎文章的标题、概要、链接
# url = `https://www.zhihu.com/people/zhang-jia-wei/posts?page=1`
1. 分析网页
点开Nekwork → All → (posts?page=1)第0个请求 → Preview,查看页面预览
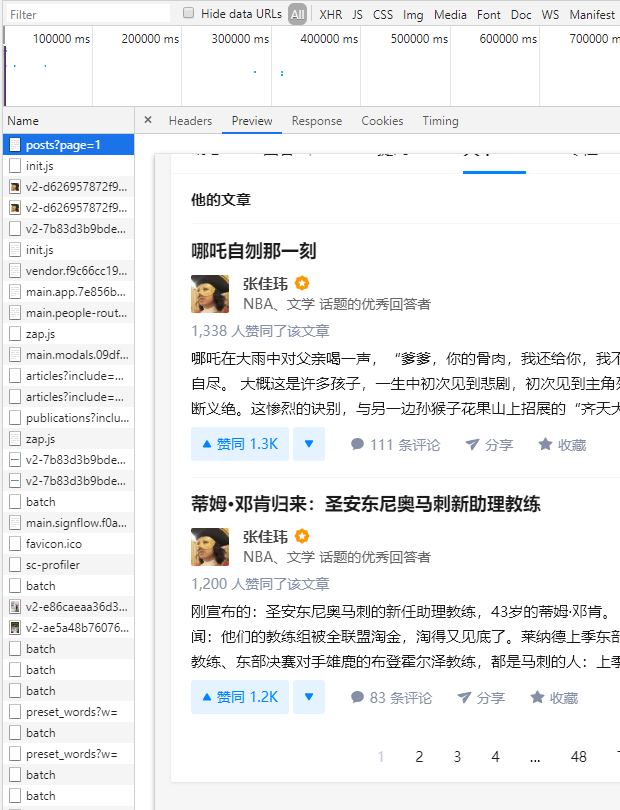
发现只有两篇文章,显然不是我们想要的数据,也就是说,这个url 并不是我们想要提取的数据的真正url,如果我们去请求这个url只能拿到两篇文章
2. 查找json数据
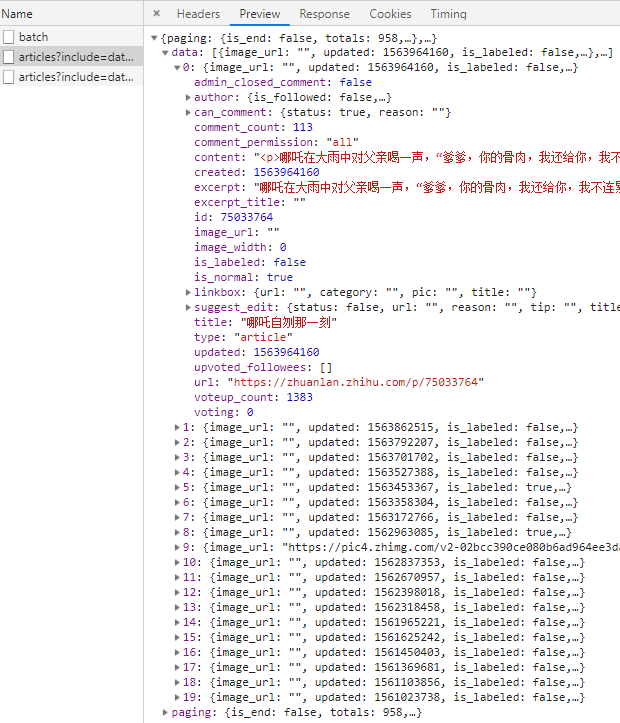
打开开发者工具,选中XHR面板,先去第三页,刷新第三页 →清空 →点开第一页,拿到数据
3. 分析Requests请求
在上面我们已经看了响应的数据,那么我们如何发送请求呢?点开Headers面板
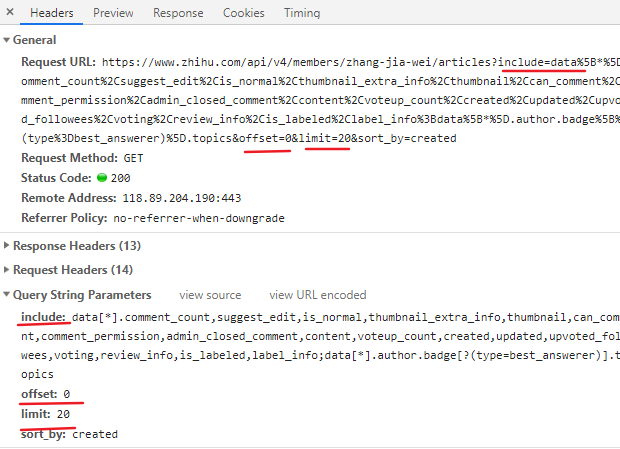
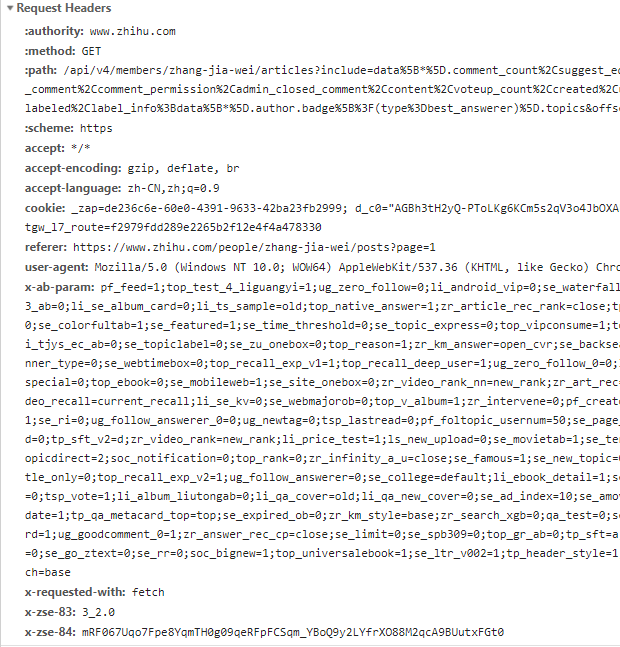
我们知道,Requests对象包含URL,请求方式,请求头,请求体(携带的参数)
General中可以看到,Requests URL一大串,其实Requests URL?号后面是get请求携带的params参数,和
Query String Parameters中的数据是一样的,但是我们不知道那些数据是变化的,大概猜一下,offset:0可能是变化的,limit:20应该是死的,表示当页文章的数量Requests Headers中
user-agent是伪装浏览器的,其它的应该没用的
我们直接去拿第二页的数据来做下对比,就可以了
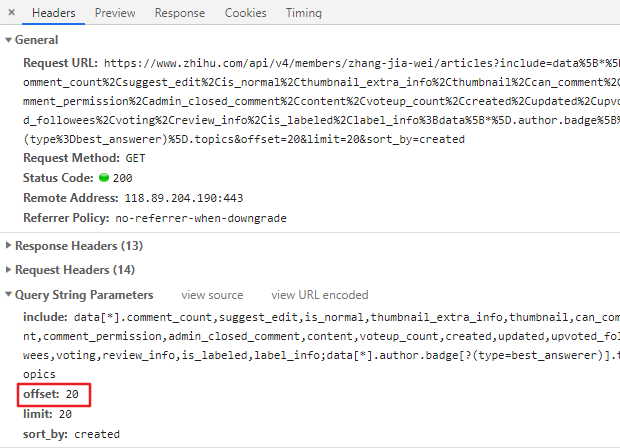

通过对比我们发现:offset的值由0变20,其它的没什么变化,可以不管!那么这个offset应该就是对应页数的变化了,下面我们提取3页的文章
代码实现:
import requests
for i in range(3):
url = 'https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
headers = {'user-agent': 'Mozilla/5.0'}
params = {'include': 'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset': str(i*20),
'limit': '20',
'sort_by': 'created'
}
r = requests.get(url,headers = headers,params = params)
print(r.status_code)
print(type(r.json()))
运行结果:
200
200
200
>>>
我们发现,请求成功了,r.json()是Requests库内置的Json解析器的方法,我们看到结果返回字典dict,这个字典是多层字典嵌套的,我们一层一层扒开不就提取到数据了?
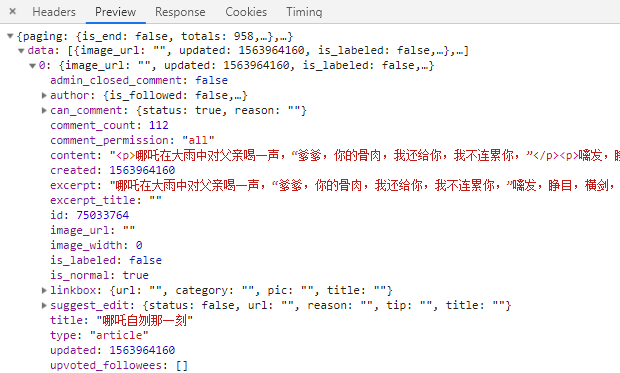
完整代码:
import requests
for i in range(3):
url = 'https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
headers = {'user-agent': 'Mozilla/5.0'}
params = {'include': 'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset': str(i*20),
'limit': '20',
'sort_by': 'created'
}
r = requests.get(url,headers = headers,params = params)
articles = r.json()['data']
for article in articles:
title = article['title']
excerpt = article['excerpt']
link = article['url']
print(title,excerpt,link)
数据提取之小结:
看第0个请求判断数据在html中还是json中
json数据查找方法是
刷新→清空→翻页Requests库的json解析方法是
json()json解析成字典结构一层一层提取
>>>阅读更多文章请点击以下链接:
python爬虫从入门到放弃之一:认识爬虫
python爬虫从入门到放弃之二:HTML基础
python爬虫从入门到放弃之三:爬虫的基本流程
python爬虫从入门到放弃之四:Requests库基础
python爬虫从入门到放弃之五:Requests库高级用法
python爬虫从入门到放弃之六:BeautifulSoup库
python爬虫从入门到放弃之七:正则表达式
python爬虫从入门到放弃之八:Xpath
python爬虫从入门到放弃之九:Json解析
python爬虫从入门到放弃之十:selenium库
python爬虫从入门到放弃之十一:定时发送邮件
python爬虫从入门到放弃之十二:多协程
python爬虫从入门到放弃之十三:Scrapy概念和流程
python爬虫从入门到放弃之十四:Scrapy入门使用
python爬虫从入门到放弃之十五:ScrapyScrapy爬取多个页面
python爬虫从入门到放弃之十六:Xpath简化
python爬虫从入门到放弃之十七:常见反爬手段
python爬虫已放弃,视频教程资源来领取