OpenMP的配置及简单使用
1.VS配置OpenMP
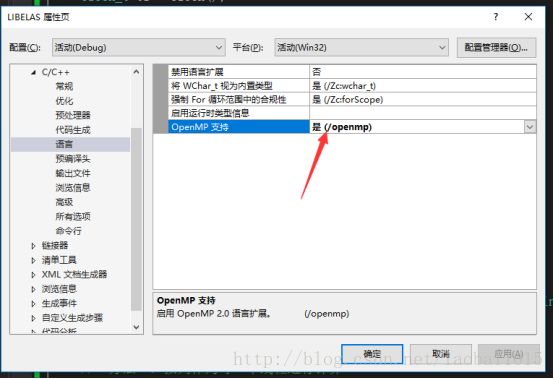
项目属性 --> C/C++ --> 语言 --> OpenMP支持,下拉菜单选择“是(/openmp)”
2.简单使用
(1)测试本机是几核的。
添加如下
说明本计算机是8核,或者说是8线程的。
代码#include
#include
int main()
{
std::cout << "parallel begin:\n";
#pragma omp parallel
{
std::cout << omp_get_thread_num();
}
std::cout << "\n parallel end.\n";
std::cin.get();
return 0;
} 运行结果如下:
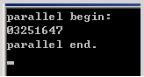
说明本计算机是8核,或者说是8线程的。
(2)简单使用omp中使用parallel制导指令标识代码中的并行段,形式为:
#pragma omp parallel
{
每个线程都会执行大括号里的代码
}parallel
parallel表示其后语句将被多个线程并行执行,“#pragma omp parallel”后面的语句(或者,语句块)被称为parallel region。
多个线程的执行顺序是不能保证的。
for
我们一般是对一个计算量庞大的任务进行划分,让多个线程分别执行计算任务的某一部分,从而达到缩短计算时间的目的。这里的关键是,每个线程执行的计算互不相同(操作的数据不同或者计算任务本身不同),多个线程协作完成所有计算。
OpenMP for指示将C++ for循环的多次迭代划分给多个线程(划分指,每个线程执行的迭代互不重复,所有线程的迭代并起来正好是C++ for循环的所有迭代),这里C++ for循环需要一些限制从而能在执行C++ for之前确定循环次数,例如C++ for中不应含有break等。
使用形式为:
1)
#pragma omp parallel for
for(...)2)
#pragma omp parallel
{//注意:大括号必须要另起一行
#pragma omp for
for(...)
}注意:第二种形式中并行块里面不要再出现parallel制导指令。
第一种形式作用域只是紧跟着的那个for循环,而第二种形式在整个并行块中可以出现多个for制导指令。
当处理多重for循环时,如果是OpenMP3.0及以后的版本,则已经支持task,能够较有效的解决不规则循环和递归函数调用等问题。
基本思路为:创建一个线程组,主线程负责创建task,负线程负责执行task
#pragma omp parallel
{
#pragma omp single
{
for (i = 0;i < N; ++i)
{
for (j = 0; j < M; ++j)
{
#pragma omp task
{
//计算部分
}
}
}
}
}1)有一个简单的test()函数,然后再main()里,用一个for循环把这个test()函数跑8遍。
#include
#include
void test()
{
int a = 0;
for (int i=0;i<100000000;i++)
a++;
}
int main()
{
clock_t t1 = clock();
for (int i=0;i<8;i++)
test();
clock_t t2 = clock();
std::cout<<"time: "< #include
#include
void test()
{
int a = 0;
for (int i=0;i<100000000;i++)
a++;
}
int main()
{
clock_t t1 = clock();
#pragma omp parallel for
for (int i=0;i<8;i++)
test();
clock_t t2 = clock();
std::cout<<"time: "< 编译运行后,打印出来的时间为:0.546秒,几乎为上面时间的1/4.
当编译器发现#pragma omp parallel for后,自动将下面的for循环分成N份,(N为电脑CPU核数),然后把每份指派给一个核去执行,而且多个核之间为并行执行。下面的代码验证了这种分析。
#include
int main()
{
#pragma omp parallel for
for (int i=0;i<10;i++)
std::cout< 会发现控制台打印出了0 3 4 5 8 9 6 7 1 2.注意:因为每个核之间是并行执行,所以每次执行时打印出来的顺序可能不是一样的。
下面我们来谈谈竞态条件(race condition)的问题,这是所有多线程编程最棘手的问题。该问题可表述为:当多个线程并行执行时,有可能多个线程同时对某变量进行了读写操作,从而导致不可预知的结果。比如下面的例子,对于包含10个整形元素的数组a,我们用for循环求它各个元素之和,并将结果保存在变量sum里。
#include
int main()
{
int sum = 0;
int a[10] = {1,2,3,4,5,6,7,8,9,10};
#pragma omp parallel for
for (int i=0;i<10;i++)
sum = sum + a[i];
std::cout<<"sum: "< 如果我们注释掉#pragma omp parallel for,让程序先按照传统串行的方式执行,很明显,sum=55。但按照并行方式执行后,sum则会变成其他值,比如在某次运行过程中,sum=49。其原因是,当某线程A执行sum = sum + a[i]的同时,另一线程B正好在更新sum,而此时A还在用旧的sum做累加,于是出现了错误。
那么用openMP怎么实现并行数组求和呢?下面我们先给出一个基本的解决方案。该方案的思想是,首先生成一个数组sumArray,其长度为并行执行的线程的个数(默认情况下,该个数等于CPU的核数),在for循环里,让各个线程更新自己线程对应的sumArray里的元素累加到sum里,代码如下
#include
#include
int main(){
int sum = 0;
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int coreNum = omp_get_num_procs();//获得处理器个数
int* sumArray = new int[coreNum];//对应处理器个数,先生成一个数组
for (int i=0;i 上面的代码虽然达到了目的,但是它产生了较多的额外操作,比如要先生成数组sumArray,最后还要用一个for循环将它的各元素累加起来,有没有更简便的方法呢?答案是有,OpenMP为我们提供了另一个工具,归约(reduction),见下面代码:
#include
int main(){
int sum = 0;
int a[10] = {1,2,3,4,5,6,7,8,9,10};
#pragma omp parallel for reduction(+:sum)
for (int i=0;i<10;i++)
sum = sum + a[i];
std::cout<<"sum: "< 上面代码里,我们在#pragma omp parallel for后面加上了reduction(+:sum),它的意思是告诉编译器:下面的for循环你要分成多个线程跑,但每个线程都要保存变量sum的拷贝,循环结束后,所有线程把自己的sum累加起来作为最后的输出。
reduction虽然很方便,但它只支持一些基本操作,比如+,-,*,&,|,&&,||等。有些情况下,我们既要避免race condition,但涉及到的操作又超出了reduction的能力范围,应该怎么办呢?这就要用到openMP的另一个工具,critical。来看下面的例子,该例中我们求数组a的最大值,将结果保存在max里。
#include
int main(){
int max = 0;
int a[10] = {11,2,33,49,113,20,321,250,689,16};
#pragma omp parallel for
for (int i=0;i<10;i++)
{
int temp = a[i];
#pragma omp critical
{
if (temp > max)
max = temp;
}
}
std::cout<<"max: "<