An Introduction to Thread in the upcoming book From: Introduction to the C++ Boost Libraries
This is a preview of Chapter 18 An Introduction to Thread in the upcoming book From: Introduction to the C++ Boost Libraries – Volume I – Foundations.
18.1. Introduction and Objectives
In this chapter we discuss how to create C++ code that make use of multi-core processors. In particular, we introduce the thread concept. A thread is a software entity and it represents an independent unit of execution in a program. We design an application by creating threads and letting them execute separate parts of the program code with the objective of improving the speedup of an application. We define the speedup as a number that indicates how many times faster a parallel program is than its serial equivalent. The formula for the speedup S(p) on a CPU with p processors is:
S(p)= T(1)/T(p)
where the factor T(p) is the total execution time on a CPU with p processors. When the speedup equals the number of processors we then say that the speedup is perfectly linear .
The improved performance of parallel programs comes at a price and in this case we must ensure that the threads are synchronised so that they do not destroy the integrity of the shared data. To this end, Boost.Thread has a number of synchronisation mechanisms to protect the program from data races, and ensuring that the code is thread-safe. We also show how to define locks on objects and data so that only one thread can update the data at any given time.
When working with Boost.Thread you should use the following header file:
and the following namespaces:
This chapter is a gentle introduction to multi-threading. We recommend that you also run the source code that accompanies the book to see how multithreaded code differs from sequential code. In Volume II we use Thread as the basis for the implementation of parallel design patterns (Mattson 2005).
18.2 An Introduction to Threads
A process is a collection of resources to enable the execution of program instructions.
Examples of resources are (virtual) memory, I/O descriptors, run-time stack and signal handlers. It is possible to create a program that consists of a collection of cooperating processes. What is the structure of a process?
A thread is a lightweight unit of execution that shares an address space with other threads. A process has one or more threads. Threads share the resources of the in process. The execution context for a thread is the data address space that contains all variables in a program. This includes both global variables and automatic variables in routines as well as dynamically allocated variables. Furthermore, each thread has its own stack within the execution context. Multiple threads invoke their own routines without interfering with the stack frames of other threads.
18.3 The Life of a Thread
Each process starts with one thread, the master or main thread. Before a new thread can be used, it must be created. The main thread can have one or more child threads. Each thread executes independently of the other threads.
What is happening in a thread after it has been created and before it no longer exists? A general answer is that it is either executing or not executing. The latter state may have several causes:
18.3.1 How Threads Communicate
A multi-threaded application consists of a collection of threads. Each thread is responsible for some particular task in the application. In order to avoid anarchy we need to address a number of important issues:
The main reason for creating a multi-threaded application is performance and responsiveness. As such, threaded code does not add new functionality to a serial application. There should be compelling reasons for using parallel programming techniques.
In this section we give an overview of a number of issues to address when developing parallel applications (see Mattson 2005 and Nichols 1996). First, we give a list of criteria that help us determine the categories of applications that could benefit from parallel processing. Second, having determined that a given application should be parallelised we discuss how to analyse and design the application with ’ parallelism in mind ’.
18.4.1 Suitable Tasks for Multi-threading
The ideal situation is when we can design an application that consists of a number of independent tasks in which each task is responsible for its own input, processing and output.
In practice, however tasks are inter-dependent and we must take this into account.
Concurrency is a property of software systems in which several computations are executing simultaneously and potentially interacting with each other. We maximise concurrency while we minimise the need for synchronisation. We identify a task that will be a candidate for threading based on the following criteria (Nichols 1996):
This class represents a thread. It has member functions for creating threads, firing up threads, thread synchronisation and notification, and finally changing thread state. We discuss the functionality of the thread class in this chapter.
There are three constructors in thread:
We now discuss some code to show how to create a simple ‘101’ multi-threaded program.
There are two threads, namely the main thread (in the main() function) and a thread that we explicitly create in main(). The program is simple – each one thread is prints some text on the console.
The first case is when we create a thread whose thread function is a free (global) function:
We now create a thread with
GlobalFuntion()
as thread function and we fire the thread up:
Each thread prints information on the console. There is no coordination between the threads and you will get different output each time you run the program. The output depends on the thread scheduler. You can run the program and view the output.
We now discuss how to create a thread whose thread function is a static member function of a class and that is a functor at the same time.
We can now create threads based on the static member function
StaticFunction()
and on the fact that
CallableClass
is a function object:
and
Finally, when a thread’s destructor is called then the thread of execution becomes detached and it no longer has an associated
boost::thread
object. In other words, the member function
Thread::detach()
is called while the thread function continues running.
18.6 The Life of a Thread
In general, a thread is either doing something (running its thread function) or is doing nothing (wait or sleep mode). The state transition diagram is shown in Figure 18.1. The scheduler is responsible for some of the transitions between states:
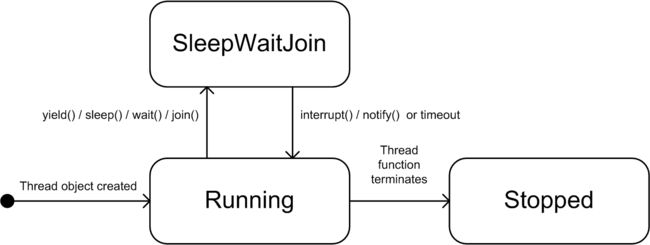
We now discuss some of the member functions that appear in Figure 18.1. First, we note that multi-tasking is not guaranteed to be preemptive and this can result in possible performance degradation because a thread can be involved in a computationally intensive algorithm. Preemption relates to the ability of the operating system to stop a running thread in favour of another thread. In order to give other threads a chance to run, a running thread may voluntarily give up or yield control. Control is returned as soon as possible. For example, we use the global function yield() in the boost::this_thread namespace.
As an example, consider a callable object that computes the powers of numbers (this class could be adapted to compute powers of very large matrices which would constitute a computationally intensive algorithm):
A thread can put itself to sleep for a certain duration (the units can be a POSIX time duration, hours, minutes, seconds, milliseconds or nanoseconds). We use the sleep option when we wish to give other threads a chance to run and for tasks that fire at regular intervals. The main difference is that with yield the thread gets the processor as soon as possible.
We give an example to show how to put a thread to sleep. We simulate an animation application by creating a thread whose thread function displays some information, then sleeps only to be awoken again by the scheduler at a later stage. The thread function is modelled as AnimationClass:
Note that the boost thread is created in the Start() function passing itself as thread function. This function object will loop until we call Stop(). In the current case the main() function will call this member function. The code corresponding to the second thread is:
We note the presence of the variable
boost::mutex m_mustStopMutex
and the
call lock()
and
unlock()
on that variable in the
Stop()
and
operator ()
functions.We discuss mutexes in section 18.7.
The next question is: how does a thread ‘wait’ on another thread before proceeding? The answer is to use join() (wait for a thread to finish) or timed_join (wait for a thread to finish for a certain amount of time). The effect in both cases is to put the calling thread into WaitSleepJoin state. It is used when we need to wait on the result of a lengthy calculation.
To give an example, we revisit the class PowerClass and we use it in main() as follows:
Here we see that the main thread does some calculations and it waits until the computationally intensive thread function in PowerClass has completed.
18.7 Basic Thread Synchronisation
One of the attention points when writing multi-threaded code is to determine how to organise threads in such a way that access to shared data is done in a controlled manner.
This is because the order in which threads access data is non-deterministic and this can lead to inconsistent results; called race conditions. A classic example is when two threads attempt to withdraw funds from an account at the same time. The steps in a sequential program to perform this transaction are:
Figure 18.2 Thread Synchronisation
The solution is to ensure that steps 1, 2 and 3 constitute an atomic transaction by which we mean that they are locked by a single thread at any one moment in time. Boost.Thread has a number of classes for thread synchronisation. The first class is called mutex (mutual exclusion) and it allows us to define a lock on a code block and release the lock when the thread has finished executing the code block. To do this, we create an Account class containing an embedded mutex:
We now give the code for withdrawing funds from an account. Notice the thread-unsafe version (which can lead to race conditions) and the thread-safe version using mutex:
Only one thread has the lock at any time. If another thread tries to lock a mutex that is already locked it will enter the SleepWaitJoin state. Summarising, only one thread can hold a lock on a mutex and the code following the call to mutex.lock() can only be executed by one thread at a given time.
A major disadvantage of using mutex is that the system will deadlock (‘hang’) if you forget to call mutex.unlock(). For this reason we use the unique_lock adapter class that locks a mutex in its constructor and that unlocks a mutex in its destructor. The new version of the withdraw member function will be:
Note that it is not necessary to unlock the mutex in this case.
18.8 Thread Interruption
A thread that is in the WaitSleepJoin state can be interrupted by another thread which results in the former thread transitioning into the Running state. To interrupt a thread we call the thread member function interrupt() and then an exception of type thread_interrupted is thrown. We note that interrupt() only works when the thread is in the WaitSleepJoin state. If the thread never enters this state, you should call boost::this_thread::interruption_point() to specify a point where the thread can be interrupted.
The following function contains a defined interruption point:
We now use this function in a test program; in this case we start a thread with ThreadFunction() as thread function. We let it run and then we interrupt it.
18.9 Thread Notification
In some cases a thread A needs to wait for another thread B to perform some activity. Boost.Thread provides an efficient way for thread notification:
18.10 Thread Groups
Boost.Thread contains the class thread_group that supports the creation and management of a group of threads as one entity. The threads in the group are related in some way. The functionality is:
18.11 Shared Queue Pattern
This pattern is a specialisation of the Shared Data Pattern (Mattson 2005). It is a thread-safe wrapper for the STL queue container. It is a blocking queue because a thread wishing to dequeue the data will go into sleep mode if the queue is empty and it will only call this function when it receives a notify() from another thread. This notification implies that new data is in the queue. The lock is automatically released and waiting threads are notified using a condition variable. A condition variable provides a way of naming an event in which threads have a general interest.
The interface is:
We now use this class as a data container in the Producer-Consumer pattern.
18.12 The Producer-Consumer Pattern
This pattern is useful in a variety of situations. There are many applications of this pattern (POSA 1996, Mattson 2005, GOF 1995). In general, one or more producer agents write information to a synchronised queue while one or more consumer agents extract information from the queue. It is possible to extend the pattern to support multiple queues. The Producer-Consumer Pattern is depicted in Figure 18.3.
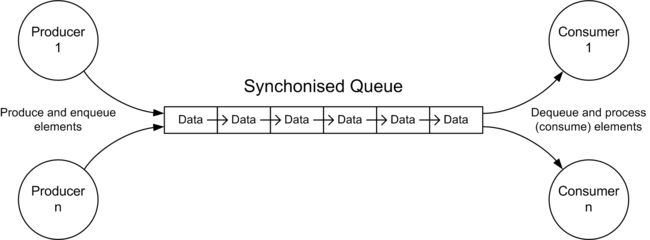
We create a producer class as follows:
Similarly, the interface for the consumer class is given by:
Finally, the following code creates thread groups for producers and consumers using the thread-group class:
18.13 Thread Local Storage
We know that global data is shared between threads. In some cases we may wish to give each thread its own copy of global data. To this end, we call thread_specific_ptr
Here is an example of a thread function that defines it own copy of global data:
We now initialise the copy of the global data, we also create a thread group and we add a number of threads to it, each one having its own copy of the global data:
18.14 Summary and Conclusions
We have included a chapter on multi-threading using Boost.Thread. It is now possible to create parallel applications in C++. We see a future for multi-tasking and multi-threading applications and for this reason we decided to give an introduction to the most important functionality in this library.
Boost.Thread contains low-level operations or implementation mechanisms that we use to design and implement multithreaded applications. It contains the building blocks that can be used with parallel design patterns (see Mattson 2005). We summarise the main steps in the process of creating a multithreaded application:
About the Author:
Daniel Duffy is an author and trainer. His company Datasim specializes in methods and techniques for solving problems in quantitative finance. He is the author of Monte Carlo Frameworks: Building Customisable High-performance C++ Applications and Introduction to C++ for Financial Engineers: An Object-Oriented Approach . For more information on the author, see QuantNet's interview with Daniel Duffy
18.1. Introduction and Objectives
In this chapter we discuss how to create C++ code that make use of multi-core processors. In particular, we introduce the thread concept. A thread is a software entity and it represents an independent unit of execution in a program. We design an application by creating threads and letting them execute separate parts of the program code with the objective of improving the speedup of an application. We define the speedup as a number that indicates how many times faster a parallel program is than its serial equivalent. The formula for the speedup S(p) on a CPU with p processors is:
S(p)= T(1)/T(p)
where the factor T(p) is the total execution time on a CPU with p processors. When the speedup equals the number of processors we then say that the speedup is perfectly linear .
The improved performance of parallel programs comes at a price and in this case we must ensure that the threads are synchronised so that they do not destroy the integrity of the shared data. To this end, Boost.Thread has a number of synchronisation mechanisms to protect the program from data races, and ensuring that the code is thread-safe. We also show how to define locks on objects and data so that only one thread can update the data at any given time.
When working with Boost.Thread you should use the following header file:
Code (C++):
-
#include
Code (C++):
-
using namespace boost ;
-
using namespace boost :: this_thread ;
18.2 An Introduction to Threads
A process is a collection of resources to enable the execution of program instructions.
Examples of resources are (virtual) memory, I/O descriptors, run-time stack and signal handlers. It is possible to create a program that consists of a collection of cooperating processes. What is the structure of a process?
- A read-only area for program instructions.
- A read-write area for global data.
- A heap area for memory that we allocate dynamically using the new operator or the mallocsystem call.
- A stack where we store the automatic variables of the current procedure.
A thread is a lightweight unit of execution that shares an address space with other threads. A process has one or more threads. Threads share the resources of the in process. The execution context for a thread is the data address space that contains all variables in a program. This includes both global variables and automatic variables in routines as well as dynamically allocated variables. Furthermore, each thread has its own stack within the execution context. Multiple threads invoke their own routines without interfering with the stack frames of other threads.
18.3 The Life of a Thread
Each process starts with one thread, the master or main thread. Before a new thread can be used, it must be created. The main thread can have one or more child threads. Each thread executes independently of the other threads.
What is happening in a thread after it has been created and before it no longer exists? A general answer is that it is either executing or not executing. The latter state may have several causes:
- It is sleeping.
- It is waiting on some other thread.
- It is blocked, that is it is waiting on system resources to perform an input or output operation.
18.3.1 How Threads Communicate
A multi-threaded application consists of a collection of threads. Each thread is responsible for some particular task in the application. In order to avoid anarchy we need to address a number of important issues:
- Synchronisation: ensuring that an event in one thread notifies another thread. This is calledevent synchronisation. This signals the occurrence of an event among multiple threads. Another type of synchronisation is mutual exclusion that gives a thread exclusive access to a shared variable or to some other resource for a certain amount of time. This ensures the integrity of the shared variable when multiple threads attempt to access and modify it. We place a lock on the resource and failure to do this may result in a race condition. This occurs when multiple threads share data and at least one of the threads accesses this data without using a defined synchronisation mechanism.
- Scheduling: we order the events in a program by imposing some kind of scheduling policy on them. In general, there are more concurrent tasks to be executed than there are processors to run them. The scheduler synchronises access to the different processors on a CPU. Thus the scheduler determines which threads are currently executing on the available processors.
The main reason for creating a multi-threaded application is performance and responsiveness. As such, threaded code does not add new functionality to a serial application. There should be compelling reasons for using parallel programming techniques.
In this section we give an overview of a number of issues to address when developing parallel applications (see Mattson 2005 and Nichols 1996). First, we give a list of criteria that help us determine the categories of applications that could benefit from parallel processing. Second, having determined that a given application should be parallelised we discuss how to analyse and design the application with ’ parallelism in mind ’.
18.4.1 Suitable Tasks for Multi-threading
The ideal situation is when we can design an application that consists of a number of independent tasks in which each task is responsible for its own input, processing and output.
In practice, however tasks are inter-dependent and we must take this into account.
Concurrency is a property of software systems in which several computations are executing simultaneously and potentially interacting with each other. We maximise concurrency while we minimise the need for synchronisation. We identify a task that will be a candidate for threading based on the following criteria (Nichols 1996):
- Its degree of independence from other tasks. Does the task need results or data from other tasks and do other tasks depend on its results? These questions determine theprovide/require constraints between tasks. An analysis of these questions will lead us to questions concerning task dependencies and resource sharing.
- Does a task spend a long time in a suspended state and is it blocked in potentially long waits? Tasks that consume resources are candidates for threads. For example, if we dedicate a thread for I/O operations then our program will run faster instead of having to wait for slow I/O operations to complete.
- Compute-intensive routines. In many applications we may be able to dedicate threads to tasks with time-consuming calculations. Examples of such calculations are array processing, matrix manipulation and random number generation.
This class represents a thread. It has member functions for creating threads, firing up threads, thread synchronisation and notification, and finally changing thread state. We discuss the functionality of the thread class in this chapter.
There are three constructors in thread:
- Default constructor.
- Create a thread with an instance of a callable type (which can be a function object, a global or static function) as argument. This function is run when the thread fires up that is, after thread creation.
- Create a thread with a callable type and its bound arguments to the thread constructor.
We now discuss some code to show how to create a simple ‘101’ multi-threaded program.
There are two threads, namely the main thread (in the main() function) and a thread that we explicitly create in main(). The program is simple – each one thread is prints some text on the console.
The first case is when we create a thread whose thread function is a free (global) function:
Code (C++):
-
// Global function called by thread
-
void GlobalFunction ( )
-
{
-
for ( int i = 0 ; i < 10 ; ++i )
-
{
-
cout << i << "Do something in parallel with main method." << endl ;
-
boost :: this_thread :: yield ( ) ; // 'yield' discussed in section 18.6
-
}
-
}
-
Code (C++):
-
int main ( )
-
{
-
boost :: thread t ( &GlobalFunction ) ;
-
-
for ( int i = 0 ; i < 10 ; i ++ )
-
{
-
cout << i << "Do something in main method." <<endl ;
-
}
-
-
return 0 ;
-
}
-
We now discuss how to create a thread whose thread function is a static member function of a class and that is a functor at the same time.
Code (C++):
-
class CallableClass
-
{
-
private :
-
// Number of iterations
-
int m_iterations ;
-
-
public :
-
-
// Default constructor
-
CallableClass ( )
-
{
-
m_iterations = 10 ;
-
}
-
-
// Constructor with number of iterations
-
CallableClass ( int iterations )
-
{
-
m_iterations =iterations ;
-
}
-
-
// Copy constructor
-
CallableClass ( const CallableClass & source )
-
{
-
m_iterations =source. m_iterations ;
-
}
-
-
// Destructor
-
~CallableClass ( )
-
{
-
}
-
-
// Assignment operator
-
CallableClass & operator = ( const CallableClass & source )
-
{
-
m_iterations =source. m_iterations ;
-
return * this ;
-
}
-
-
// Static function called by thread
-
static void StaticFunction ( )
-
{
-
for ( int i = 0 ; i < 10 ; i ++ ) // Hard-coded upper limit
-
{
-
cout <<i << "Do something in parallel (Static function)." <<endl ;
-
boost :: this_thread :: yield ( ) ; // 'yield' discussed in section 18.6
-
}
-
}
-
-
// Operator() called by the thread
-
void operator ( ) ( )
-
{
-
for ( int i = 0 ; i <m_iterations ; i ++ )
-
{
-
cout <<i << " - Do something in parallel (operator() )." <<endl ;
-
boost :: this_thread :: yield ( ) ; // 'yield' discussed in section 18.6
-
}
-
}
-
-
} ;
-
Code (C++):
-
int main ( )
-
{
-
boost :: thread t ( &CallableClass :: StaticFunction ) ;
-
-
for ( int i = 0 ; i < 10 ; i ++ )
-
{
-
cout <<i << " - Do something in main method." <<endl ;
-
}
-
-
return 0 ;
-
}
-
Code (C++):
-
int main ( )
-
{
-
// Using a callable object as thread function
-
int numberIterations = 20 ;
-
CallableClass c (numberIterations ) ;
-
boost :: thread t (c ) ;
-
-
for ( int i = 0 ; i < 10 ; i ++ )
-
{
-
cout << i << " – Do something in main method." << endl ;
-
}
-
-
return 0 ;
-
}
-
18.6 The Life of a Thread
In general, a thread is either doing something (running its thread function) or is doing nothing (wait or sleep mode). The state transition diagram is shown in Figure 18.1. The scheduler is responsible for some of the transitions between states:
- Running: the thread has been created and is already started or is ready to start (this is a runnable state). The scheduler has allocated processor time for the thread.
- WaitSleepJoin: the thread is waiting for an event to trigger. The thread will be placed in the Running state when this event triggers.
- Stopped: the thread function has run its course (has completed).
Figure 18.1 Thread Lifecycle
We now discuss some of the member functions that appear in Figure 18.1. First, we note that multi-tasking is not guaranteed to be preemptive and this can result in possible performance degradation because a thread can be involved in a computationally intensive algorithm. Preemption relates to the ability of the operating system to stop a running thread in favour of another thread. In order to give other threads a chance to run, a running thread may voluntarily give up or yield control. Control is returned as soon as possible. For example, we use the global function yield() in the boost::this_thread namespace.
As an example, consider a callable object that computes the powers of numbers (this class could be adapted to compute powers of very large matrices which would constitute a computationally intensive algorithm):
Code (C++):
-
class PowerClass
-
{
-
private :
-
-
// Version II: m will be a large matrix
-
int m, n ; // Variables for m^n
-
-
public :
-
double result ; // Public data member for the result
-
-
// Constructor with arguments
-
PowerClass ( int m, int n )
-
{
-
this - >m =m ; this - >n =n ;
-
this - >result = 0.0 ;
-
}
-
-
// Calculate m^n. Supposes n>=0
-
void operator ( ) ( )
-
{
-
result =m ; // Start with m^1
-
for ( int i = 1 ; i <n ; ++i )
-
{
-
result * =m ; // result=result*m
-
boost :: this_thread :: yield ( ) ;
-
}
-
if (n == 0 ) result = 1 ; // m^0 is always 1
-
}
-
} ;
-
We give an example to show how to put a thread to sleep. We simulate an animation application by creating a thread whose thread function displays some information, then sleeps only to be awoken again by the scheduler at a later stage. The thread function is modelled as AnimationClass:
Code (C++):
-
class AnimationClass
-
{
-
private :
-
boost :: thread * m_thread ; // The thread runs this object
-
int m_frame ; // The current frame number
-
-
// Variable that indicates to stop and the mutex to
-
// synchronise "must stop" on (mutex explained later)
-
bool m_mustStop ;
-
boost :: mutex m_mustStopMutex ;
-
-
public :
-
// Default constructor
-
AnimationClass ( )
-
{
-
m_thread = NULL ;
-
m_mustStop = false ;
-
m_frame = 0 ;
-
}
-
-
// Destructor
-
~AnimationClass ( )
-
{
-
if (m_thread ! = NULL ) delete m_thread ;
-
}
-
-
// Start the threa
-
void Start ( )
-
{
-
// Create thread and start it with myself as argument.
-
// Pass myself as reference since I don't want a copy
-
m_thread = new boost :: thread (boost :: ref ( * this ) ) ;
-
}
-
-
// Stop the thread
-
void Stop ( )
-
{
-
// Signal the thread to stop (thread-safe)
-
m_mustStopMutex. lock ( ) ;
-
m_mustStop = true ;
-
m_mustStopMutex. unlock ( ) ;
-
-
// Wait for the thread to finish.
-
if (m_thread ! = NULL ) m_thread - >join ( ) ;
-
}
-
-
// Display next frame of the animation
-
void DisplayNextFrame ( )
-
{
-
// Simulate next frame
-
cout << "Press
to stop. Frame: " <<m_frame ++ <<endl ; -
}
-
-
// Thread function
-
void operator ( ) ( )
-
{
-
bool mustStop ;
-
-
do
-
{
-
// Display the next animation frame
-
DisplayNextFrame ( ) ;
-
-
// Sleep for 40ms (25 frames/second).
-
boost :: this_thread :: sleep (boost :: posix_time :: millisec ( 40 ) ) ;
-
-
// Get the "must stop" state (thread-safe)
-
m_mustStopMutex. lock ( ) ;
-
mustStop =m_mustStop ;
-
m_mustStopMutex. unlock ( ) ;
-
}
-
while (mustStop == false ) ;
-
}
-
} ;
-
Code (C++):
-
int main ( )
-
{
-
// Create and start the animation class
-
AnimationClass ac ;
-
ac. Start ( ) ;
-
-
// Wait for the user to press return
-
getchar ( ) ;
-
-
// Stop the animation class
-
cout << "Animation stopping..." << endl ;
-
ac. Stop ( ) ;
-
cout << "Animation stopped." << endl ;
-
-
return 0 ;
-
}
-
The next question is: how does a thread ‘wait’ on another thread before proceeding? The answer is to use join() (wait for a thread to finish) or timed_join (wait for a thread to finish for a certain amount of time). The effect in both cases is to put the calling thread into WaitSleepJoin state. It is used when we need to wait on the result of a lengthy calculation.
To give an example, we revisit the class PowerClass and we use it in main() as follows:
Code (C++):
-
int main ( )
-
{
-
int m = 2 ;
-
int n = 200 ;
-
-
// Create a m^n calculation object
-
PowerClass pc (m, n ) ;
-
-
// Create thread and start m^n calculation in parallel
-
// Since we read the result from pc, we must pass it as reference,
-
// else the result will be placed in a copy of pc
-
boost :: thread t (boost :: ref (pc ) ) ;
-
-
// Do calculation while the PowerClass is calculating m^n
-
double result =m *n ;
-
-
// Wait till the PowerClass is finished
-
// Leave this out and the result will be bogus
-
t. join ( ) ;
-
-
// Display result.
-
cout << "(" << m << "^" << n << ") / (" << m << "*" << n
-
<< ") = " <<pc. result /result <<endl ;
-
}
-
18.7 Basic Thread Synchronisation
One of the attention points when writing multi-threaded code is to determine how to organise threads in such a way that access to shared data is done in a controlled manner.
This is because the order in which threads access data is non-deterministic and this can lead to inconsistent results; called race conditions. A classic example is when two threads attempt to withdraw funds from an account at the same time. The steps in a sequential program to perform this transaction are:
- Check the balance (are there enough funds in the account?).
- Give the amount to withdraw.
- Commit the transaction and update the account.
| Thread 1 | Thread 2 | balance |
| if (70>balance) | 100 | |
| if (90>balance) | 100 | |
| balance-=70 | 30 | |
| balance-=90 | -60 |
The solution is to ensure that steps 1, 2 and 3 constitute an atomic transaction by which we mean that they are locked by a single thread at any one moment in time. Boost.Thread has a number of classes for thread synchronisation. The first class is called mutex (mutual exclusion) and it allows us to define a lock on a code block and release the lock when the thread has finished executing the code block. To do this, we create an Account class containing an embedded mutex:
Code (C++):
-
class Account
-
{
-
private :
-
-
// The mutex to synchronise on
-
boost :: mutex m_mutex ;
-
-
// more...
-
} ;
-
Code (C++):
-
// Withdraw an amount (not synchronized). Scary!
-
void Withdraw ( int amount )
-
{
-
if (m_balance -amount >= 0 )
-
{
-
// For testing we now give other threads a chance to run
-
boost :: this_thread :: sleep (boost :: posix_time :: seconds ( 1 ) ) ;
-
-
m_balance - =amount ;
-
}
-
else throw NoFundsException ( ) ;
-
}
-
-
// Withdraw an amount (locking using mutex object)
-
void WithdrawSynchronized ( int amount )
-
{
-
// Acquire lock on mutex.
-
// If lock already locked, it waits till unlocked
-
m_mutex. lock ( ) ;
-
-
if (m_balance -amount >= 0 )
-
{
-
// For testing we now give other threads a chance to run
-
boost :: this_thread :: sleep (boost :: posix_time :: seconds ( 1 ) ) ;
-
-
m_balance - =amount ;
-
}
-
else
-
{
-
// Release lock on mutex. Forget this and it will hang
-
m_mutex. unlock ( ) ;
-
throw NoFundsException ( ) ;
-
}
-
-
// Release lock on mutex. Forget this and it will hang
-
m_mutex. unlock ( ) ;
-
}
-
A major disadvantage of using mutex is that the system will deadlock (‘hang’) if you forget to call mutex.unlock(). For this reason we use the unique_lock
Code (C++):
-
// Withdraw an amount (locking using unique_lock)
-
void WithdrawSynchronized2 ( int amount )
-
{
-
// Acquire lock on mutex. Will be automatically unlocked
-
// when lock is destroyed at the end of the function
-
boost :: unique_lock <boost :: mutex > lock (m_mutex ) ;
-
if (m_balance -amount >= 0 )
-
{
-
// For testing we now give other threads a change to run
-
boost :: this_thread :: sleep (boost :: posix_time :: seconds ( 1 ) ) ;
-
m_balance - =amount ;
-
}
-
else throw NoFundsException ( ) ;
-
} // Mutex automatically unlocked here
-
18.8 Thread Interruption
A thread that is in the WaitSleepJoin state can be interrupted by another thread which results in the former thread transitioning into the Running state. To interrupt a thread we call the thread member function interrupt() and then an exception of type thread_interrupted is thrown. We note that interrupt() only works when the thread is in the WaitSleepJoin state. If the thread never enters this state, you should call boost::this_thread::interruption_point() to specify a point where the thread can be interrupted.
The following function contains a defined interruption point:
Code (C++):
-
// The function that will be run by the thread
-
void ThreadFunction ( )
-
{
-
// Never ending loop. Normally the thread will never finish
-
while ( true )
-
{
-
try
-
{
-
// Interrupt can only occur in wait/sleep or join operation.
-
// If you don't do that, call interuption_point().
-
// Remove this line, and the thread will never be interrupted.
-
boost :: this_thread :: interruption_point ( ) ;
-
}
-
catch ( const boost :: thread_interrupted & )
-
{
-
// Thread interruption request received, break the loop
-
cout << "- Thread interrupted. Exiting thread." <<endl ;
-
break ;
-
}
-
}
-
}
-
Code (C++):
-
int main ( )
-
{
-
// Create and start the thread
-
boost :: thread t ( &ThreadFunction ) ;
-
-
// Wait 2 seconds for the thread to finish
-
cout << "Wait for 2 seconds for the thread to stop." <<endl ;
-
while (t. timed_join (boost :: posix_time :: seconds ( 2 ) ) == false )
-
{
-
// Interupt the thread
-
cout << "Thread not stopped, interrupt it now." <<endl ;
-
t. interrupt ( ) ;
-
cout << "Thread interrupt request sent. "’
-
cout << "Wait to finish for 2 seconds again." <<endl ;
-
}
-
-
// The thread has been stopped
-
cout << "Thread stopped" <<endl ;
-
}
-
In some cases a thread A needs to wait for another thread B to perform some activity. Boost.Thread provides an efficient way for thread notification:
- wait(): thread A releases the lock when wait() is called; A then sleeps until another thread B calls notify().
- notify(): signals a change in an object related to thread B. Then one waiting thread (in this case A) wakes up after the lock has been released.
- notify_all(): this has the same intent as notify() except that all waiting threads wake up.
18.10 Thread Groups
Boost.Thread contains the class thread_group that supports the creation and management of a group of threads as one entity. The threads in the group are related in some way. The functionality is:
- Create a new thread group with no threads.
- Delete all threads in the group.
- Create a new thread and add it to the group.
- Remove a thread from the group without deleting the thread.
- join_all(): call join() on each thread in the group.
- interrupt_all(): call interrupt() on each thread object in the group.
- size(): give the number of threads in the group.
18.11 Shared Queue Pattern
This pattern is a specialisation of the Shared Data Pattern (Mattson 2005). It is a thread-safe wrapper for the STL queue
The interface is:
Code (C++):
-
// Queue class that has thread synchronisation
-
template < typename T >
-
class SynchronisedQueue
-
{
-
private :
-
std :: queue <T > m_queue ; // Use STL queue to store data
-
boost :: mutex m_mutex ; // The mutex to synchronise on
-
boost :: condition_variable m_cond ; // The condition to wait for
-
-
public :
-
-
// Add data to the queue and notify others
-
void Enqueue ( const T & data )
-
{
-
// Acquire lock on the queue
-
boost :: unique_lock <boost :: mutex > lock (m_mutex ) ;
-
-
// Add the data to the queue
-
m_queue. push (data ) ;
-
-
// Notify others that data is ready
-
m_cond. notify_one ( ) ;
-
-
} // Lock is automatically released here
-
-
// Get data from the queue. Wait for data if not available
-
T Dequeue ( )
-
{
-
-
// Acquire lock on the queue
-
boost :: unique_lock <boost :: mutex > lock (m_mutex ) ;
-
-
// When there is no data, wait till someone fills it.
-
// Lock is automatically released in the wait and obtained
-
// again after the wait
-
while (m_queue. size ( ) == 0 ) m_cond. wait (lock ) ;
-
-
// Retrieve the data from the queue
-
T result =m_queue. front ( ) ; m_queue. pop ( ) ;
-
return result ;
-
-
} // Lock is automatically released here
-
} ;
-
18.12 The Producer-Consumer Pattern
This pattern is useful in a variety of situations. There are many applications of this pattern (POSA 1996, Mattson 2005, GOF 1995). In general, one or more producer agents write information to a synchronised queue while one or more consumer agents extract information from the queue. It is possible to extend the pattern to support multiple queues. The Producer-Consumer Pattern is depicted in Figure 18.3.
Figure 18.3 Producer-Consumer Pattern
We create a producer class as follows:
Code (C++):
-
// Class that produces objects and puts them in a queue
-
class Producer
-
{
-
private :
-
int m_id ; // The id of the producer
-
SynchronisedQueue <string > * m_queue ; // The queue to use
-
-
public :
-
-
// Constructor with id and the queue to use
-
Producer ( int id, SynchronisedQueue <string > * queue )
-
{
-
m_id =id ;
-
m_queue =queue ;
-
}
-
-
// The thread function fills the queue with data
-
void operator ( ) ( )
-
{
-
int data = 0 ;
-
while ( true )
-
{
-
// Produce a string and store in the queue
-
string str = "Producer: " + IntToString (m_id ) +
-
" data: " + IntToString (data ++ ) ;
-
m_queue - >Enqueue (str ) ;
-
cout <<str <<endl ;
-
-
// Sleep one second
-
boost :: this_thread :: sleep (boost :: posix_time :: seconds ( 1 ) ) ;
-
}
-
}
-
} ;
-
Code (C++):
-
// Class that consumes objects from a queue
-
class Consumer
-
{
-
private :
-
int m_id ; // The id of the consumer
-
SynchronisedQueue <string > * m_queue ; // The queue to use
-
-
public :
-
// Constructor with id and the queue to use.
-
Consumer ( int id, SynchronisedQueue <string > * queue )
-
{
-
m_id =id ;
-
m_queue =queue ;
-
}
-
-
// The thread function reads data from the queue
-
void operator ( ) ( )
-
{
-
while ( true )
-
{
-
// Get the data from the queue and print it
-
cout << "Consumer " <<IntToString (m_id ). c_str ( )
-
<< " consumed: (" <<m_queue - >Dequeue ( ). c_str ( ) ;
-
-
// Make sure we can be interrupted
-
boost :: this_thread :: interruption_point ( ) ;
-
}
-
}
-
} ;
-
Code (C++):
-
#include "Producer.hpp"
-
#include "Consumer.hpp"
-
-
using namespace std ;
-
-
int main ( )
-
{
-
// Display the number of processors/cores
-
cout <<boost :: thread :: hardware_concurrency ( )
-
<< " processors/cores detected." <<endl <<endl ;
-
cout << "When threads are running, press enter to stop" <<endl ;
-
-
// The number of producers/consumers
-
int nrProducers, nrConsumers ;
-
-
// The shared queue
-
SynchronisedQueue <string > queue ;
-
-
// Ask the number of producers
-
cout << "How many producers do you want? : " ;
-
cin >>nrProducers ;
-
-
// Ask the number of consumers
-
cout << "How many consumers do you want? : " ;
-
cin >>nrConsumers ;
-
-
// Create producers
-
boost :: thread_group producers ;
-
for ( int i = 0 ; i <nrProducers ; i ++ )
-
{
-
Producer p (i, &queue ) ;
-
producers. create_thread (p ) ;
-
}
-
-
// Create consumers
-
boost :: thread_group consumers ;
-
for ( int i = 0 ; i <nrConsumers ; i ++ )
-
{
-
Consumer c (i, &queue ) ;
-
consumers. create_thread (c ) ;
-
}
-
// Wait for enter (two times because the return from the
-
// previous cin is still in the buffer)
-
getchar ( ) ; getchar ( ) ;
-
-
// Interrupt the threads and stop them
-
producers. interrupt_all ( ) ; producers. join_all ( ) ;
-
consumers. interrupt_all ( ) ; consumers. join_all ( ) ;
-
}
-
We know that global data is shared between threads. In some cases we may wish to give each thread its own copy of global data. To this end, we call thread_specific_ptr
Here is an example of a thread function that defines it own copy of global data:
Code (C++):
-
// Global data. Each thread has its own value
-
boost :: thread_specific_ptr < int > threadLocalData ;
-
-
// Callable function
-
void CallableFunction ( int id )
-
{
-
// Initialise thread local data (for the current thread)
-
threadLocalData. reset ( new int ) ;
-
*threadLocalData = 0 ;
-
-
// Do this a number of times
-
for ( int i = 0 ; i < 5 ; i ++ )
-
{
-
// Print value of global data and increase value
-
cout << "Thread: " <<id << " - Value: " << ( *threadLocalData ) ++ <<endl ;
-
-
// Wait one second
-
boost :: this_thread :: sleep (boost :: posix_time :: seconds ( 1 ) ) ;
-
}
-
}
-
Code (C++):
-
int main ( )
-
{
-
// Initialise thread local data (for the main thread)
-
threadLocalData. reset ( new int ) ;
-
*threadLocalData = 0 ;
-
-
// Create threads and add them to the thread group
-
boost :: thread_group threads ;
-
for ( int i = 0 ; i < 3 ; i ++ )
-
{
-
boost :: thread * t = new boost :: thread ( &CallableFunction, i ) ;
-
threads. add_thread (t ) ;
-
}
-
-
// Wait till they are finished
-
threads. join_all ( ) ;
-
-
// Display thread local storage value, should still be zero
-
cout << "Main - Value: " << ( *threadLocalData ) <<endl ;
-
return 0 ;
-
}
-
We have included a chapter on multi-threading using Boost.Thread. It is now possible to create parallel applications in C++. We see a future for multi-tasking and multi-threading applications and for this reason we decided to give an introduction to the most important functionality in this library.
Boost.Thread contains low-level operations or implementation mechanisms that we use to design and implement multithreaded applications. It contains the building blocks that can be used with parallel design patterns (see Mattson 2005). We summarise the main steps in the process of creating a multithreaded application:
- Finding Concurrency: we decide if a problem is a suitable candidate for a parallel solution. System decomposition based on tasks or data allows us to find potentially concurrent tasks and their dependencies. In particular, we need a way of grouping tasks and ordering the groups in order to satisfy temporal constraints.
- An initial design is produced.
- Algorithm Structure Design: we elaborate the initial model in order to move it closet to a program. We pay attention to forces such as efficiency, simplicity, portability and scalability. The algorithm structure will be determined by tasks on the one hand or by data on the other hand. Examples of high-level algorithms are Divide and Conquer, Geometric Decomposition and Pipeline.
- Supporting Structures Design: in this phase we need to decide how to model program structure and shared data. For example, the program could be designed as a SPMD (Single Program Multiple Data), Master Worker or Loop Parallelism pattern. Possible data structures are Shared Data and Shared Queue whose implementation we discussed in section 18.11.
- Implementation Mechanisms: in this phase we deploy the functionality of Boost.Thread to implement the design.
About the Author:
Daniel Duffy is an author and trainer. His company Datasim specializes in methods and techniques for solving problems in quantitative finance. He is the author of Monte Carlo Frameworks: Building Customisable High-performance C++ Applications and Introduction to C++ for Financial Engineers: An Object-Oriented Approach . For more information on the author, see QuantNet's interview with Daniel Duffy