Hadoop集群搭建
Hadoop集群搭建记得完成hadoop的搭建:https://blog.csdn.net/liu1340308350/article/details/105135800
hadoop集群搭建:
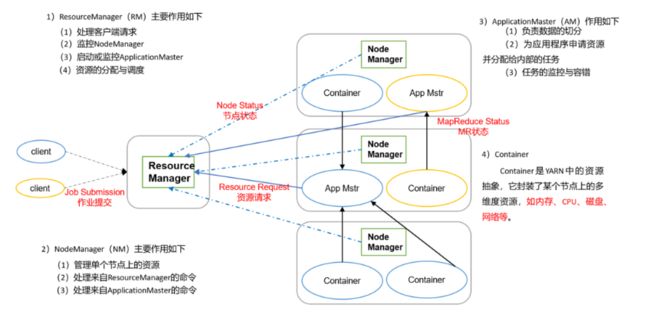
也就是要修改以下文件

修改方法
1.使用sublime文件
配置方法:https://blog.csdn.net/liu1340308350/article/details/105139669
2.直接在secureCRT中配置
这里我是使用第一种方法配置的
修改配置文件
hadoop-env.sh
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/export/servers/jdk
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
# Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_MOVER_OPTS=""
###
# Advanced Users Only!
###
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
也就是修改JDK路径

注意: JAVA_HOME的路径按照你自己的路径来
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration>
fs.defaultFS表示我们对HDFS的访问路径
dfs.replication指定副本数量,也就是一个文件存几遍
dfs.namenode.secondary.http-address表示2nn的访问路径
mapred-site.xml
系统里面没有mapred-site.xml文件,则需要复制一个
cp mapred-site.xml.template mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
slaves
hadoop01
hadoop02
hadoop03
上传配置
将以上修改的文件上传到服务器中:
右键–>SFTP/FTP–>Upload File
对应下图文件:
注意:只要是修改过的文件都需要Upload

配置文件分发
让hadoop02、03和01保持一致
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
scp /etc/profile hadoop02:/etc/profile这句是发环境变量
scp -r /export/ hadoop02:/这句是发hadoop整个文件夹
注意: 命令执行完之后在hadoop02和hadoop03上执行source /etc/profile
配置完以上的文件,那么集群基本配置就已经完成
执行格式化
在hadoop01中执行下列命令
hdfs namenode -format
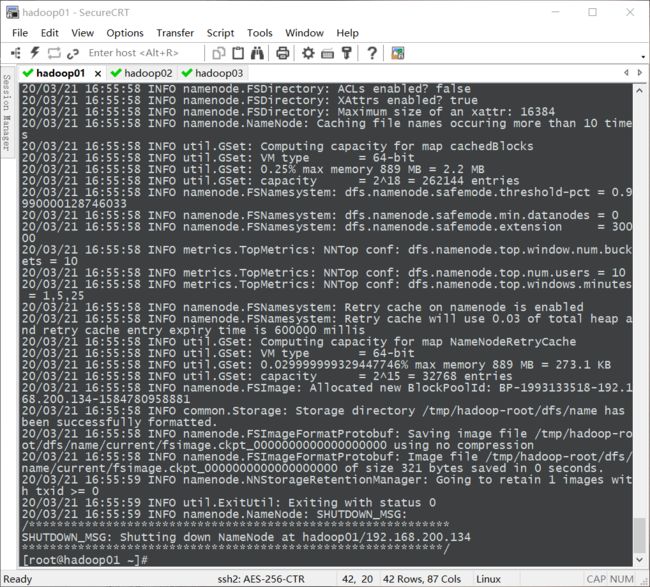
在上图看到下图内容则说明文件配置成功
![]()
查看hadoop信息
![]()
注意: 第一次进入没有data文件,需要启动namenode

下图是hadoop文件的树形结构:
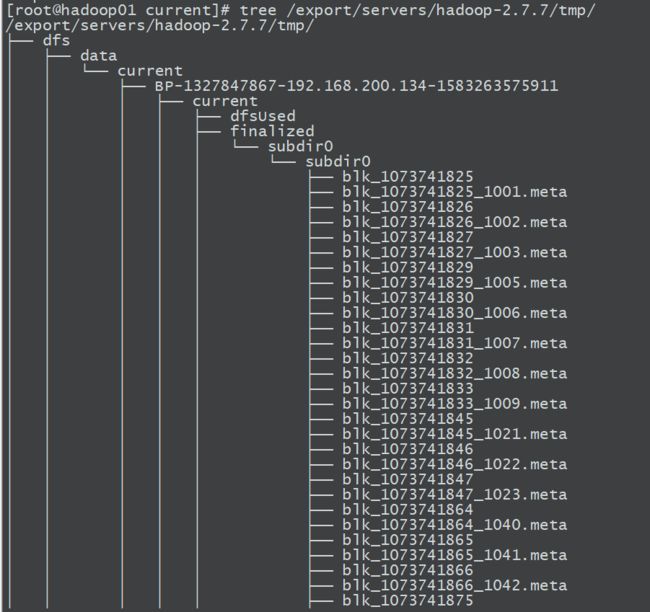
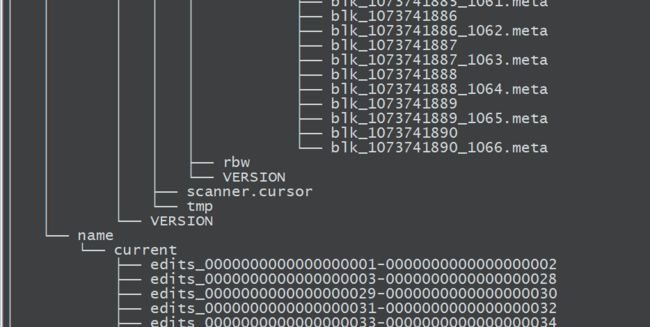

注意:
如果想让文件显示树形结构,需要安装tree文件:yum -y install tree

查看版本信息:clusterID必须保持一致
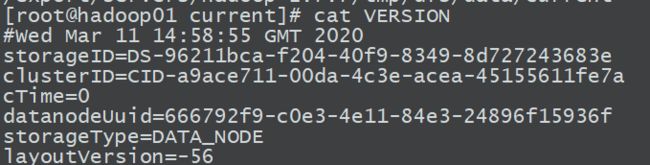
注意:
1.如果后面出现集群找不到数据的情况,那就是因为NameNode和DataNode的集群id不一致
2.格式化NameNode,会产生新的集群id
启动HDFS和YARN
hadoop01:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
hadoop02:
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
在节点hadoop02执行指令启动SecondaryNameNode进程
hadoop-daemon.sh start secondarynamenode
hadoop03:
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
脚本一键启动
在主节点hadoop01上执行指令start-dfs.sh或stop-dfs.sh启动/关闭所有HDFS服务进程
在主节点hadoop01上执行指令start-yarn.sh或stop-yarn.sh启动/关闭所有YARN服务进程;
在主节点hadoop01上执行start-all.sh或stop-all.sh指令,直接启动/关闭整个Hadoop集群服务。
查看是否启动
hadoop01,02,03的情况如下图所示:
hadoop01:

hadoop02:
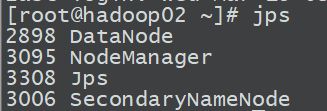
hadoop03:
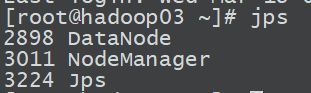
配置jps快捷键
创建文件夹 /root/bin
touch jpsall
vim jpsall
chmod 777 jpsall
jpsall文件内容如下:
#!/bin/bash
for i in hadoop01 hadoop02 hadoop03
do
echo ===================== $i ======================
ssh $i "source /etc/profile && jps | grep -v Jps"
done
配置完成就不再需要单独运行jps了
测试:
游览器访问
Hadoop集群正常启动后,它默认开放了两个端口50070和8088 ,需要关闭防火墙才能访问
service iptables stop
chkconfig iptables off
注意: hadoop02和hadoop03的防火墙也需要关闭
关闭防火墙之后,在游览器中输入下列网址即可访问:
http://hadoop01:50070/
http://hadoop01:8088
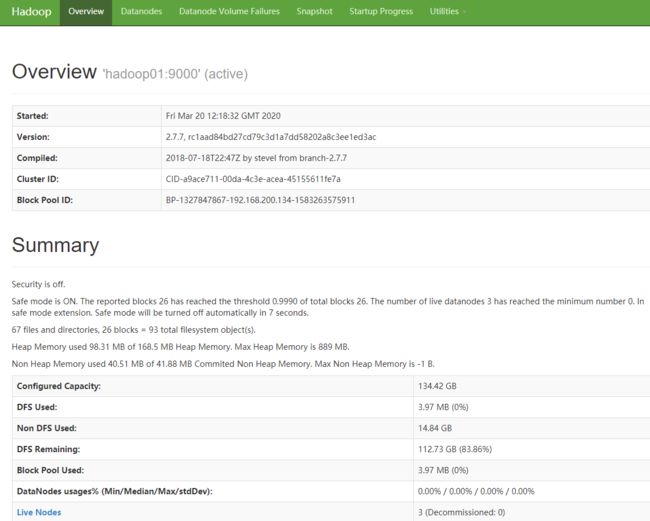
检查3个datanode是否显示:
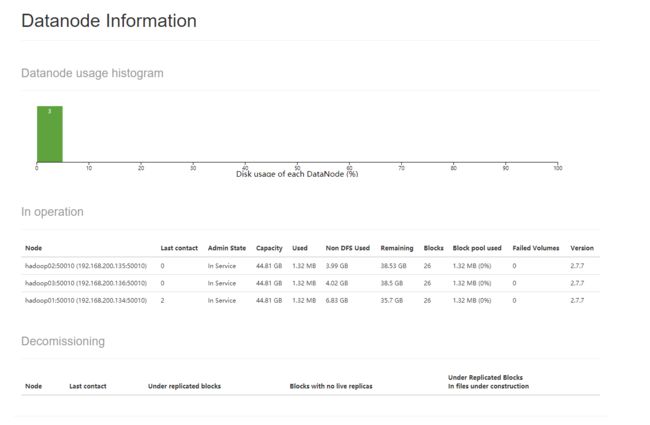
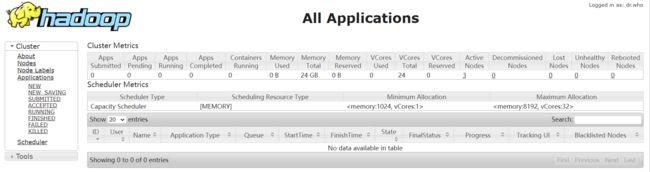
错误处理
执行命令报错:
export HADOOP_ROOT_LOGGER=DEBUG,console hdfs dfs -ls /
![]()

查阅debug报错信息,可以看到问题是glib版本不够
解决方法
1.下载对应文件
下载glibc-2.14.tar.bz2
地址为:http://ftp.ntu.edu.tw/gnu/glibc/
下载glibc-linuxthreads-2.5.tar.bz2
地址为:http://ftp.ntu.edu.tw/gnu/glibc/
2. 安装
yum install gcc
tar -xjvf glibc-2.14.tar.bz2
cd glibc-2.14
tar -xjvf ../glibc-linuxthreads-2.5.tar.bz2
cd ..
export CFLAGS="-g -O2"
glibc-2.14/configure --prefix=/usr --disable-profile --enable-add-ons -
-with-headers=/usr/include --with-binutils=/usr/bin --disable-sanitychecks
make//编译,执行很久(5-10分钟),可能出错,出错再重新执行
make install
ll /lib64/libc.so.6
测试:
![]()
测试集群

可知集群已经上hdfs了:


由下图可知集群测试成功:
看到3个备份,集群数据统一

hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /wordcount/input /wordcount/output
注意: output文件不能存在
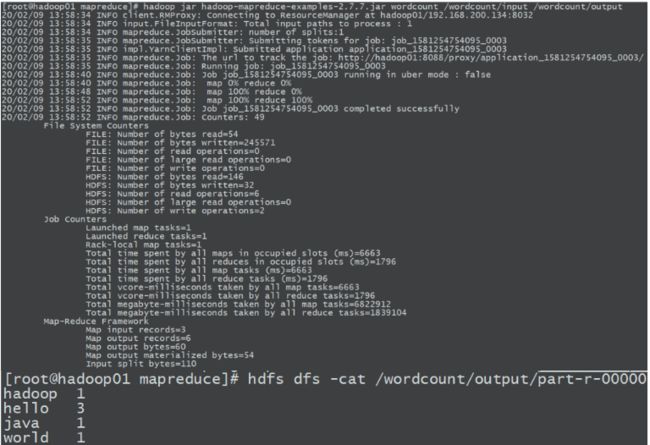
到这一步为止,表示集群运行正常
配置历史服务器

可以看到无法访问页面:
这里就需要继续编辑vim mapred-site.xml文件
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
启动历史服务器
mr-jobhistory-daemon.sh start historyserver
可以看到下图显示:
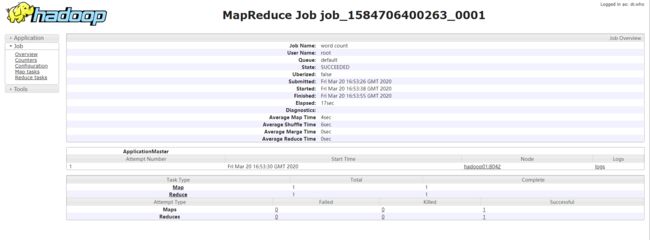
日志聚集
目的: 应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
这里需要配置yarn-site.xml
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
1.重启NodeManager 、ResourceManager和HistoryServer
2…删除HDFS上已经存在的输出文件
hdfs dfs -rm -R /wordcount/output
3.执行WordCount程序
4.查看日志聚集
点击log文件
![]()
可以看到:

那么现在开始,每个任务都开起了实时日志收集功能,日志保存7天,全部可以在cluster中查看了
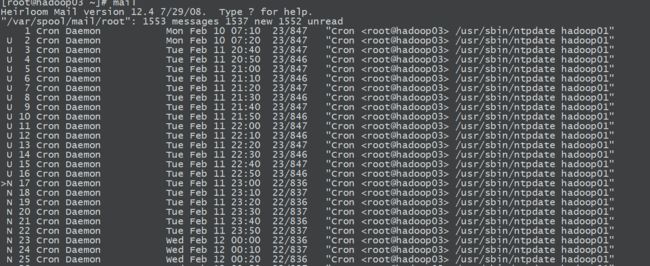
集群时间同步
这里以hadoop01作为基准时间,02、03跟他一致
1.查看是否有ntp文件,系统默认安装
rpm -qa|grep ntp

2.vim /etc/ntp.conf
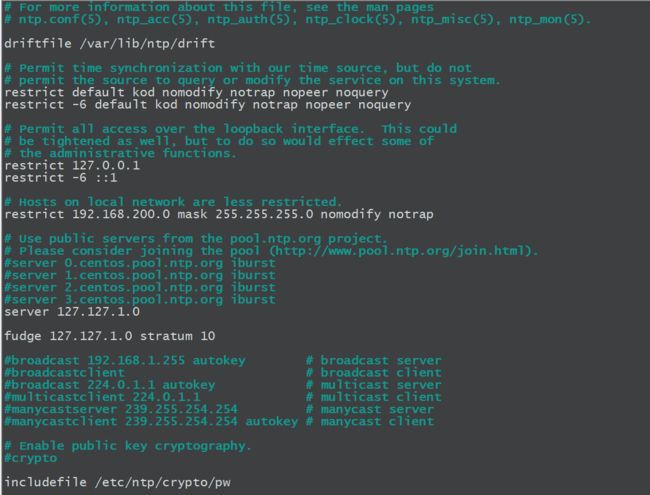

修改点:
1、授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间
将 #restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.200.0 mask 255.255.255.0 nomodify notrap
2、集群在局域网中,不使用其他互联网上的时间
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
\#server 3.centos.pool.ntp.org iburst
3、当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
server 127.127.1.0
fudge 127.127.1.0 stratum 10
3.vim /etc/sysconfig/ntpd
让硬件时间与系统时间一起同步SYNC_HWCLOCK=yes

配置文件保存之后
重新启动ntpd服务
service ntpd status
设置ntpd服务开机启动
chkconfig ntpd on
4.在hadoop2和hadoop3上配置
crontab -e
输入:
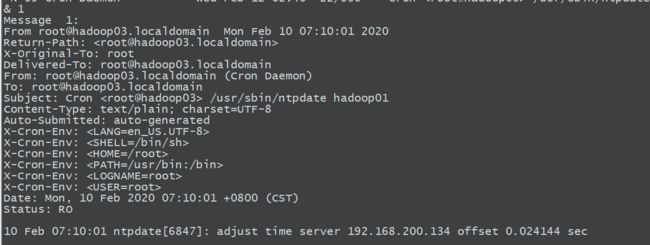
*/10 * * * * /usr/sbin/ntpdate hadoop01
这样会让hadoop02和hadoop03每10分钟与时间服务器同步一次
5.测试
修改hadoop02的当前时间:
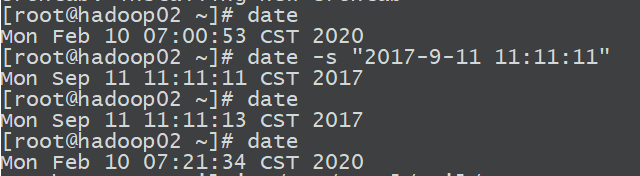
然后输入mail,系统会提示时间已经修改