python爬虫实战--第二章:电影数据处理与可视化
本实战项目通过python爬取豆瓣电影Top250榜单,利用flask框架和Echarts图表分析评分、上映年份并将结果可视化,并制作了词云,项目已经上传至服务器,欢迎各位大佬批评指正。
项目展示:http://121.36.81.197:5000/
源码地址:https://github.com/lzz110/douban_movies_top250
学习资料:Python爬虫技术5天速成(2020全新合集)
项目技术栈:Flask框架、Echarts、WordCloud、SQLite
环境:Python3
上一章已经爬取了网站上的数据并保存到数据库,这一章开始对数据进行处理并可视化到页面。
目录
- 电影排序页面实现
- 数据可视化页面实现
- 词云页面实现
电影排序页面实现
成果展示:将电影按评分排序展示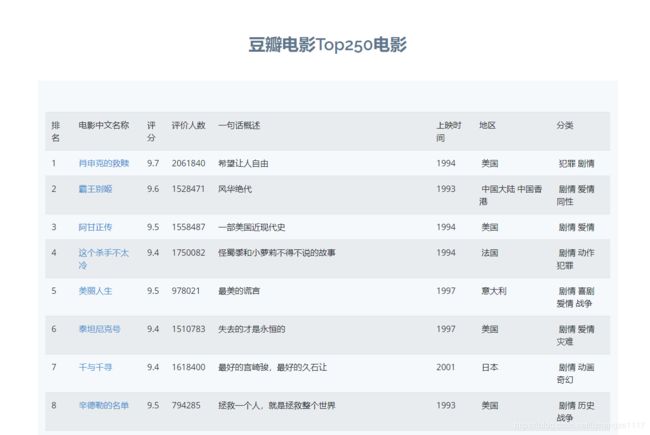
后台核心代码:从数据库中计算所需数据,回传给前端
@app.route('/movie')
def movie():
datalist = []
con = sqlite3.connect("movie.db")
cur = con.cursor()
sql = "select * from movie250"
data = cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
con.close()
# print(datalist)
return render_template("movie.html",movies = datalist)
前端核心代码movie.html:
<section class="counts section-bg">
<div class="container">
<table class="table table-striped">
<tr>
<td>排名td>
<td>电影中文名称td>
<td>评分td>
<td>评价人数td>
<td>一句话概述td>
<td>上映时间td>
<td>地区td>
<td>分类td>
tr>
{% for movie in movies %}
<tr>
<td>{{movie[0]}}td>
<td>
<a href="{{ movie[1] }}" target="_blank">
{{ movie[3] }}
a>
td>
<td>{{movie[4]}}td>
<td>{{movie[5]}}td>
<td>{{movie[6]}}td>
<td>{{movie[7]}}td>
<td>{{movie[8]}}td>
<td>{{movie[9]}}td>
tr>
{% endfor %}
table>
div>
section>
数据可视化页面实现
后台核心代码:从数据库中计算所需数据,回传给前端
@app.route('/score')
def score():
score = [] # 评分
num = [] # 每个评分所统计出的电影数量
score2 = [] # 评分
num2 = [] # 每个评分所统计出的电影数量
res={}
con = sqlite3.connect("movie.db")
cur = con.cursor()
sql = "select score,count(score) from movie250 group by score"
data = cur.execute(sql)
for item in data:
score.append(str(item[0]))
num.append(item[1])
for k, v in zip(score, num):
res.update({k: v, },)
sql2="select year_release,count(year_release) from movie250 group by year_release"
data2 = cur.execute(sql2)
for item2 in data2:
score2.append(str(item2[0]))
num2.append(item2[1])
#print(num2)
cur.close()
con.close()
return render_template("score.html",score=score,num=num,res=res,num2=num2,score2=score2)
前端页面借助Echarts实现,具体操作可参考官网教程
条形图效果展示:
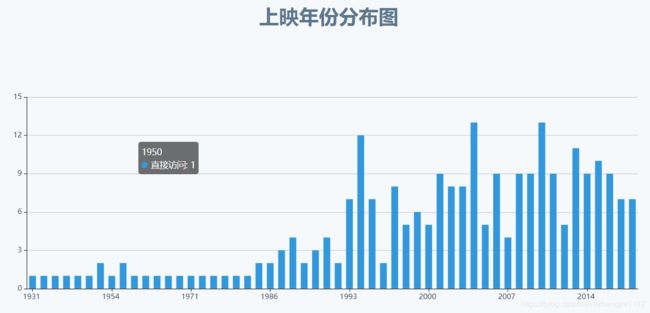
条形图核心代码:
<div class="container">
<div class="section-title">
<h2>评分分布图h2>
div>
<div id="main" style="width: 100%;height:300px">div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
var kv = new Array();//声明一个新的字典
kv = {{ res|safe }};//取出后台传递的数据,此处添加safe过滤避免警告
var test = new Array();//声明一个新的字典用于存放数据
for (var logKey in kv) {
//将对应键值对取出存入test,logKey 为该字典的键
test.push({value: kv[logKey], name: logKey});
}
// 指定图表的配置项和数据
var option = {
tooltip: {
trigger: 'item',
formatter: '{a}
{b} : {c} ({d}%)'
},
legend: {
orient: 'vertical',
left: 'left',
data: {{ score|tojson }}
},
series: [
{
name: '来源',
type: 'pie',
radius: '85%',
center: ['50%', '55%'],
data: test,
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
script>
div>
扇形图效果展示:
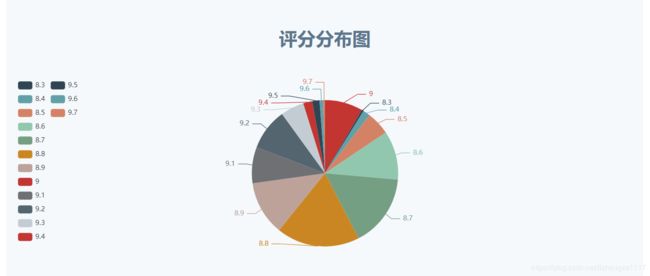
扇形图核心代码:
<div class="container">
<div class="section-title">
<h2>上映年份分布图h2>
div>
{# <div id="tiaoxing" style="width: 600px;height:400px;">div>#}
<div id="tiaoxing" style="width: 100%;height:400px;">div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart2 = echarts.init(document.getElementById('tiaoxing'));
// 指定图表的配置项和数据
var option2 = {
color: ['#3398DB'],
tooltip: {
trigger: 'axis',
axisPointer: { // 坐标轴指示器,坐标轴触发有效
type: 'shadow' // 默认为直线,可选为:'line' | 'shadow'
}
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: [
{
type: 'category',
data: {{score2|tojson}},
axisTick: {
alignWithLabel: true
}
}
],
yAxis: [
{
type: 'value'
}
],
series: [
{
name: '直接访问',
type: 'bar',
barWidth: '60%',
data: {{ num2 }}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart2.setOption(option2);
script>
div>
词云页面实现
生成词云需要用到的库:
import jieba #分词
from matplotlib import pyplot as plt #绘图,数据可视化
from wordcloud import WordCloud #词云
from PIL import Image #图片处理
import numpy as np #矩阵运算
import sqlite3 #数据库
完整代码:
#准备词云所需的文字(词)
con = sqlite3.connect('movie.db')
cur = con.cursor()
sql = 'select category from movie250'
# sql = 'select introduction from movie250'
data = cur.execute(sql)
text = ""
for item in data:
text = text + item[0]
# print(item[0])
# print(text)
cur.close()
con.close()
#分词
cut = jieba.cut(text)
string = ' '.join(cut)
# print(len(string))
img = Image.open(r'.\static\assets\img\tree.jpg') #打开遮罩图片
img_array = np.array(img) #将图片转换为数组
wc = WordCloud(
background_color='white',
mask=img_array,
font_path="msyh.ttc" #字体所在位置:C:\Windows\Fonts
)
wc.generate_from_text(string)
#绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') #是否显示坐标轴
# plt.show() #显示生成的词云图片
#输出词云图片到文件
plt.savefig(r'.\static\assets\img\category.jpg',dpi=500)
# plt.savefig(r'.\static\assets\img\test.jpg',dpi=500)
效果展示:分别根据电影简介和电影分类制作词云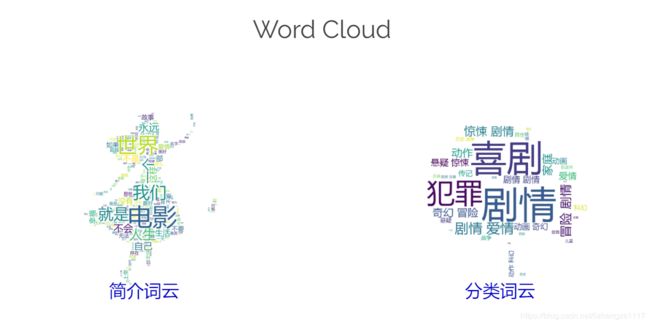
至此 爬虫项目本地就做好了,有需要的话可以上传至云服务器,方便访问,具体步骤可参考第三章:flask项目上传至服务器