MySQL数据库存储过程
-
- 存储过程相关命令汇总
- 存储过程
- 存储过程优化
- 再说存储过程的输出参数
- 再说WHILE 和 REPEAT循环
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
——百度百科
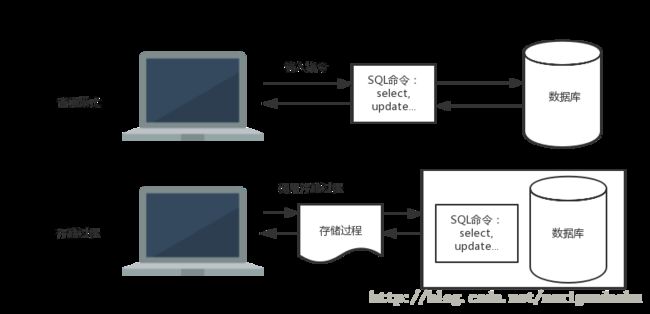
如图所示,在普通模式下获取数据,用户需要输入SQL命令与数据库进行交互,而存储过程是编写好的SQL命令,存储在数据库中,用户操作的时候只需要调用存储过程,而不用重新输入冗余繁杂的SQL命令。因此
- 存储过程有什么优点?
1.存储过程可以重复使用,大大减小开发人员的负担;
2.对于网络上的服务器,可以大大减小网络流量,因为只需要传递存储过程的名称即可;
3,可以防止对表的直接访问,只需要赋予用户存储过程的访问权限。
0 存储过程相关命令汇总
| 操作 | SQL命令 |
|---|---|
| 创建存储过程 | CREATE PROCEDURE 存储过程名(参数种类1 参数1 数据类型1,[...] BEGIN 具体的procedure(处理) END |
| 查看数据库中的存储过程 | SHOW PROCEDURE STATUS\G |
| 查看具体的存储过程 | SHOW CREATE PROCEDURE 存储过程名\G |
| 调用(执行)存储过程 | CALL 存储过程名(参数1,...); |
| 删除存储过程 | DROP PROCEDURE 存储过程名 |
| 变量声明 | DECLARE 变量名 数据类型; |
| 变量赋值 | SET 变量名= ; |
1 存储过程
1.1 创建存储过程 CREATE PROCEDURE
创建存储过程的命令是:
>CREATE PROCEDURE 存储过程名(参数种类1 参数1 数据类型1,[...])
BEGIN
具体的procedure(处理)
END
- 1)存储过程中具体的处理类容放在 BEGIN和END 之间;
- 2)存储过程需要制定参数,包括种类( IN,OUT,INOUT ,分别代表输入参数,输出参数和即是输入也是输出的参数),参数名和数据类型。【和函数不同,函数指定输入参数即可】
eg:创建一个对表customer的姓名(nam)进行模糊检索,命名为sp_search_customer。

对于上图创建PROCEDURE的几点说明:
①>DELIMITER //表示给变分隔符,默认分隔符是;,否则存储过程中含有;,MySQL监视器无法分辨。(最后将分隔符改回来)
②存储过程( BEGIN和END 之间)的具体处理内容,主要包括条件、case,循环。
| 分类 | SQL命令 |
|---|---|
| 简单条件 | IF cond1 THEN exp1 ELSEIF cond2 THEN exp2 ELSE expelse END IF |
| case | CASE 表达式 WHEN 值1 THEN … WHEN …THEN… ELSE … END CASE |
| 循环(后置判断) | REPEAT … UNTIL …END REPEAT |
| 循环(前置判断) | WHILE … DO … END WHILE |
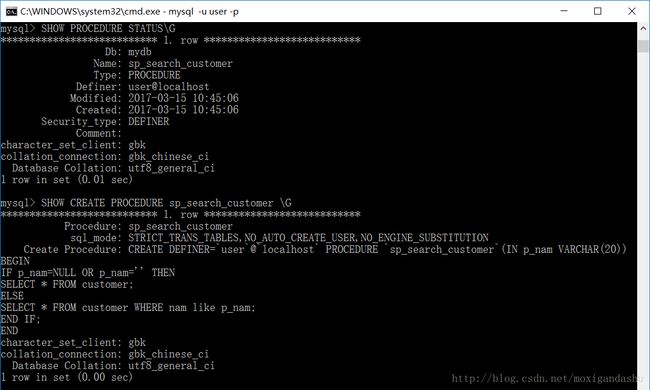
**1.2 查看存储过程** 查看数据库中是否存在存储过程:
>SHOW PROCEDURE STATUS\G查看存储过程的具体信息:
>SHOW CREATE PROCEDURE 存储过程名\Geg:查看存储过程sp_search_customer
1.3 执行存储过程 CALL
调用存储过程使用CALL 存储过程名命令,具体如下:
CALL 存储过程名(参数,...)eg:通过创建好的存储过程sp_search_cusotmer来执行存储过程:
检索‘王’姓顾客:
>CALL sp_search_customer('王%');检索所有顾客:
>CALL sp_search_customer('');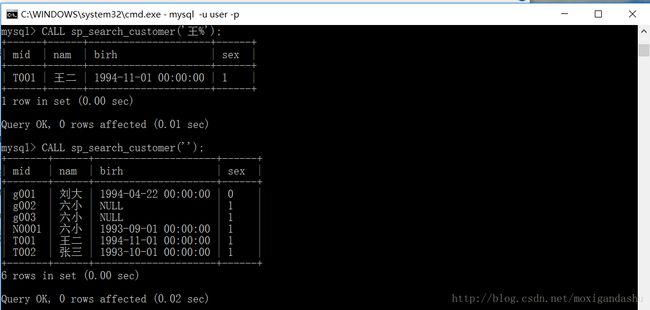
1.4 删除存储过程 DROP PROCEDURE
删除存储过程使用命令:
DROP PROCEDURE 存储过程名;2 存储过程优化
(1)使用if条件语句创建存储过程

可以看到,上述条件语句部分的结构大致都为:
IF... THEN
SELECT...;
ELSEIF ...THEN
SELECT...;
ELSEIF...THEN
SELECT...;
ELSE
SELECT...;其中的语句具有较高的重复性和冗余性,因此比较繁琐,如果我们用CASE替代呢?
(2)CASE命令的多重分支
使用CASE来创建多重分支:
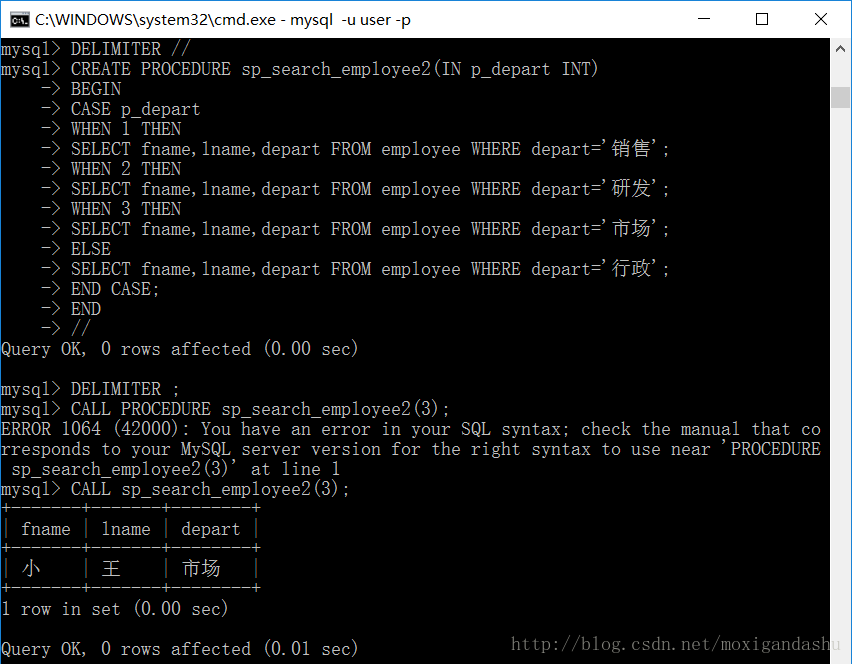
p_dapart放到CASE之后,一个p_dapart取代了多个p_dapart,因此使用CASE代码在判断语句处显得简洁一些,如果通过定义变量的形式呢?
(3)定义本地变量
存储过程中定义的变量,被称为本地变量,对程序设计语言有所了解的知道这是一个局部变量。数据库中,
声明局部变量的命令:
>DECLARE 变量名 数据类型 [初始值...]给变量赋值的命令:
>SET 变量名=,在创建procedure过程中顶一个本地变量tem:
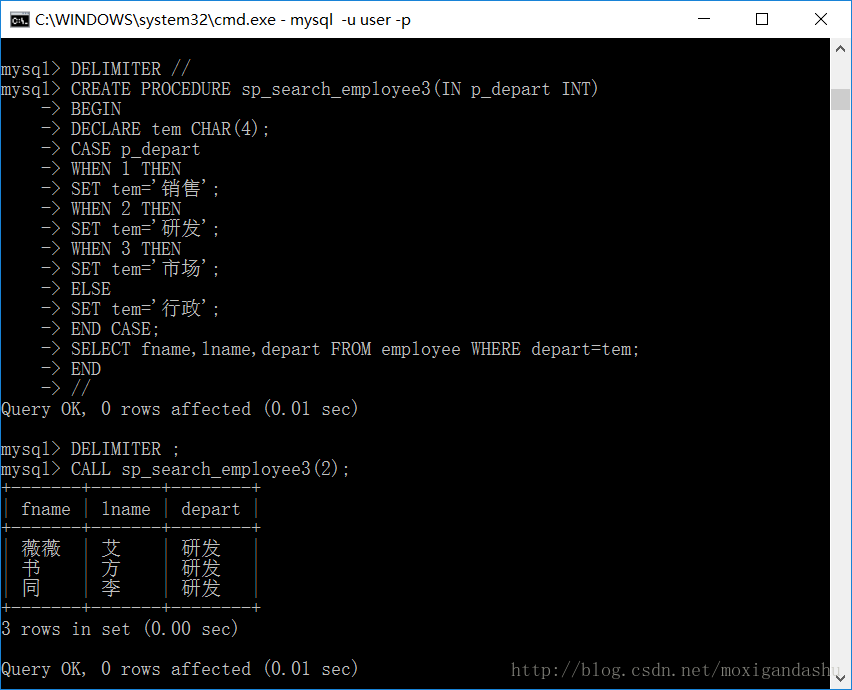
可以看到,这种方式大大地简化了代码的冗余性和重复性。
3 再说存储过程的输出参数
在创建存储过程的时候,如果制定了 OUT护着INOUT ,在调用存储过程时请在输出参数前面加上 @ ,这样结果将保存到“@变量名“中。
eg:创建一个计算阶乘的存储过程:
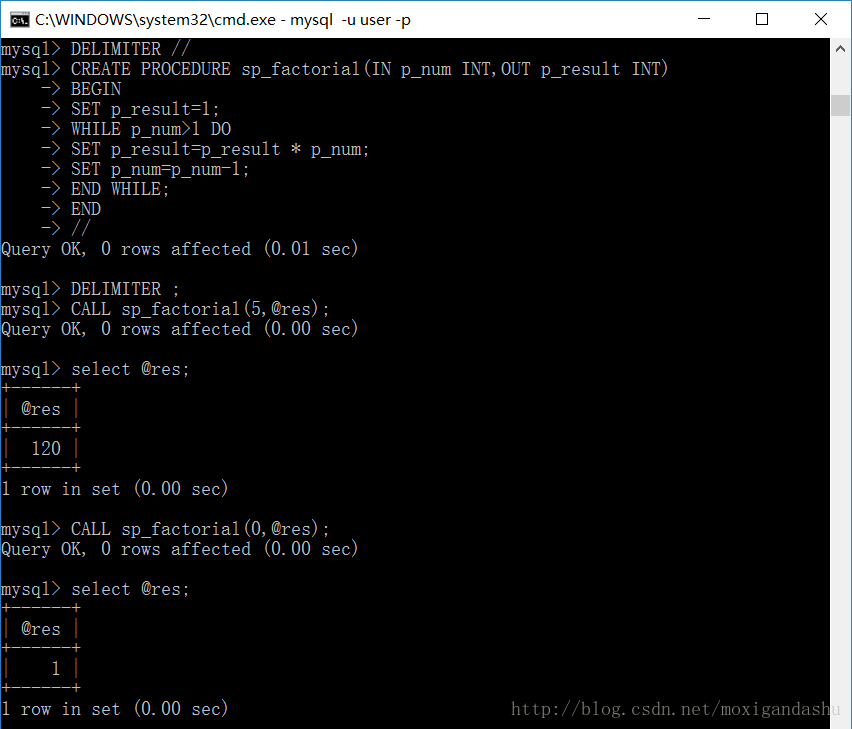
最终的结果将保存到“@res“之中,如上图所示。
- 请注意,用 WHILE 循环创建的计算阶乘的存储过程, !5=120,!0=1 ,结果是正确的。先记住这句话,接下来看下用REPEAT创建同样的阶乘计算的存储过程。
4 再说WHILE 和 REPEAT循环
我们使用repeat创建一个计算阶乘的存储过程:
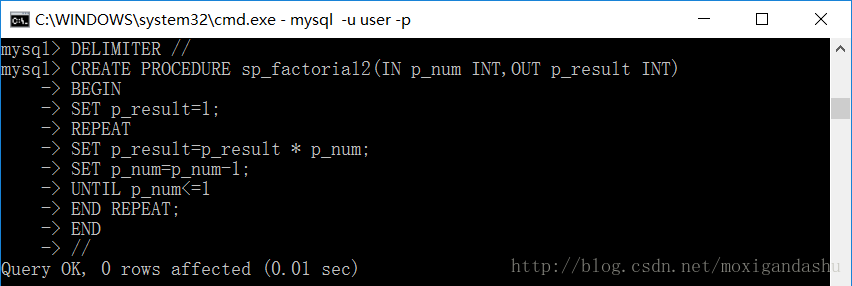
接下来看下同样计算 !5和!0 结果如何?
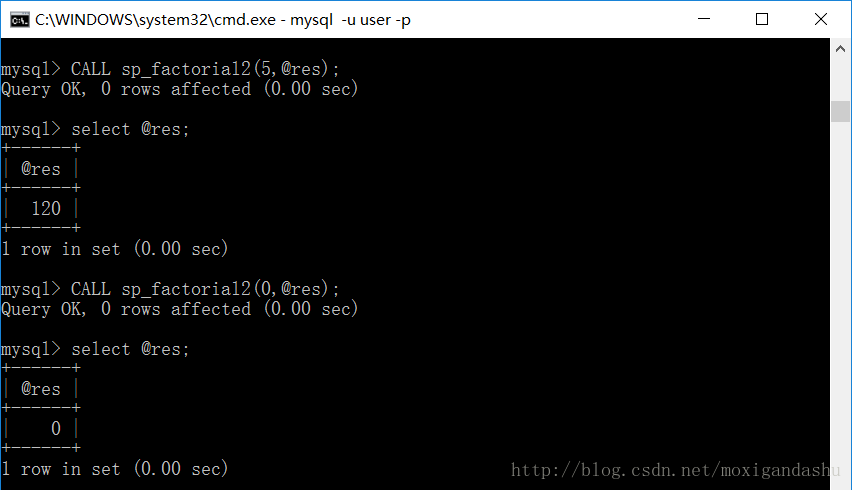
可以看到!5=120的结果正确,但是!0得到的结果为0,不为1。这是什么原因呢?
问题出在WHILE是前置判断,是先验的,先验证WHILE后面的条件是否成立,为TRUE则继续执行,若FALSE则结束循环;
而REPEAT是后置判断,是后验的,不管三七二十一先执行语句,然后验证UNTIL后面的条件语句是否成立,不成立则结束。因此REPEAT循环执行了一次 presult=presult∗pnum,即presult=1∗0 。
因此:
- WHILE循环是前置判断,先验的循环
- REPEAT循环是后置判断,后验的循环