基于内容的垃圾邮件过滤
1 引言
电子邮件(E-mail)以其方便、快捷、低成本的独特魅力成为人们日常生活中不可缺少的通信手段之一。但电子邮件给人们带来极大便利的同时,也日益显示出其负面影响,那就是我们每天收到的邮件中有很大一部分是那种“不请自来”的,它们或者是推销广告,或者是一些有害的不良信息,甚至还有病毒,通常我们称它们为垃圾邮件(Spam、Junk Mail)。对于电子邮件服务提供商和用户而言,垃圾邮件给他们带来了很大的困扰,因而人们开始从多方面寻找解决方案。
目前最常用的垃圾邮件过滤技术有以下三种:
基于黑/白名单的过滤技术。白名单中的发件人发送的任何邮件都认为是合法邮件,黑名单中的发件人发送的任何邮件都认为是垃圾邮件。这是目前电子邮件过滤中广泛使用的技术。通常做法是收集一个黑、白名单列表,可以是电子邮件地址,也可以是邮件服务器的域名、IP地址,收到邮件时对发件人进行实时检查。
行为模式识别技术:垃圾邮件总有一些区别于正常邮件的行为特征,如短期内大量发送,特殊时间发送,邮件转发,邮件地址异常等,通过分析垃圾邮件的发信行为特征来判别该邮件是否为垃圾邮件,这种过滤技术就称为行为模式识别技术。
基于内容的过滤技术:包括基于规则的过滤技术和基于概率统计的过滤技术两种。基于规则的过滤技术的实质是一个归纳总结的过程,通过考查一个个的训练样本,归纳总结出其中规律性的东西来形成规则。规则方法的主要优点是可以生成人类理解的规则,缺点是在规律性不明显的应用领域效果较差。基于统计的过滤技术通过统计词语在垃圾邮件和正常邮件中出现的频率,来标识其是否带有明显的垃圾邮件特征。当有新的邮件到来时,可以从中提取特征词,通过计算特征词的垃圾邮件特征的明显程度来判定其是否是垃圾邮件。
上述三种垃圾邮件过滤技术分别针对电子邮件发送至接收过程中的不同阶段或不同方面,并不是对立的,在实用的垃圾邮件检测系统中,通常将它们结合使用。
在本文中,我们主要研究的是基于内容的垃圾邮件过滤技术[1],对于基于内容的垃圾邮件过滤技术,不管是基于规则的方法还是基于概率统计的方法,在使用时都需经历从训练到过滤的过程。通过已有的训练集合训练出相应的垃圾邮件分类器,然后将分类器应用到新邮件的判定中去。
从本质上看,基于内容的垃圾邮件过滤是一个文本分类问题,当前有多种文本分类算法可供采用,通过组内的研究和比较,我们选用了其中的三种方法,包括朴素贝叶斯分类算法,决策树和Boosting方法,朴素贝叶斯分类算法是一种基于概率统计的方法,后两者是基于规则的方法。本文主要描述基于决策树的文本分类算法。实验结果表明,三种方法都能达到较高的垃圾邮件过滤效果,并且Boosting方法具有最好的表现。
2 垃圾邮件过滤器模型
2.1 垃圾邮件过滤器的组成
判断一封邮件是否为垃圾邮件的过程就是将邮件文本进行分类的过程,文本分类需要的资源为语料集,语料集在文本分类时需分成为训练语料一集和测试语料集两部分。文本分类过程主要由训练和分类两部分组成。在训练过程中,将训练语料集经过文本预处理,特征选择等处理和分析,挖掘出文本和文本类别之间潜在的关系模型。在分类过程中,测试语料集经过文本预处理,特征表示,根据训练过程中得到的文本和文本类别之间的关系模型,将文本分到一个或某几个类别中。垃圾邮件过滤器的组成如图2.1所示。

图2.1 垃圾邮件过滤器的组成
2.2 邮件预处理
2.2.1 文本预处理
在文本分类前,首先要对文本进行预处理。文本预处理是将非结构化,半结构化的文本信息转化成计算机可识别,处理的结构化信息。文本预处理的首要任务是分词,主要由分析词法、消除停用词、还原词干、选择词四部分组成[2]。由于当前所提供的训练与测试数据集已经过预处理,故不再需要进行分词。
2.2.2 文本表示
对直接用字符集表示的自然文本,计算机还没办法直接理解,需要将其进一步转化,将自然语言形式的文本映射成机器内部表示结构。当前,常用的文本表示方式是向量空间模型(VSM,Vector Space Model)。
向量空间模型[3]是以代数理论为基础的,在此模型中,一篇文本可以表示为一个n维向量(w1,w1,...,wn),其中wi(i=1,2,...,n)表示第i个特征项(Term)的权重,n是特征项的个数,特征项可以是字、词、短语或者某种概念,本文中采用词作为特征项。权重有多种计算方法,最简单的是布尔权重,即权重为1(该特征项在文本中出现)或者0(该特征项没有在文本中出现)。更通常的情况下,VSM中的权重计算采用词频(TF,Term Frequency,表示该特征词在文本中出现的次数)和文档频次(DF,Document Frequency,表示出现该特征词的文档数量)的某种组合。
解决了文本表示问题之后,我们可以将文本分类抽象为一般的描述:设类别总数为C,cj表示第j(j=1,2,...,C)类,提供给分类器的训练集(训练集中的文本都已经过人工分类)包含D篇文本,特征空间为(t1,t2,...,tn),n为特征数量,每篇文本可表示为di=(wi1,wi2,...,win), i=1,2,...,D。一篇待分类文本可泛化表示为dx=(wx1,wx2,...,wxn),任务是将dx分到相应的类别中去。
2.2.3 特征选择
除了文本表示,如何选择一种合适的算法处理高维数据是文本分类面临的另外一个重要问题。在理论上,随着特征数量的增加,将会对文本分类提供更多的信息,以提高分类的效率和准确度。但实际上,选择过多的特征不仅减慢了学习过程,而且由于大量不相关和冗余特征的存在影响了学习的精确度和准确度。因此需要对高维特征空间降维。特征选择是一种常用的特征降维方法。
特征选择被广泛应用于各种领域,如机器学习,模式识别和统计学等领域。特征选择是从具有n个特征的特征集合中选取m个特征构成子特征集合,使评估函数的值在所有具有m个特征的特征子集合中达到最大值。特征选择是对原始文本中重要信息的提取,从统计角度压缩特征维数,侧重于特征的分布信息。
卡方统计特征选择方法[4]是一种常用的特征选择方法,可用于度量特征和类别之间的相关性。特征与类别间的卡方统计值越大,说明特征与类别间的独立性越小,则它们之间的相关性越强。
卡方统计量用来衡量特征项与类别之间的相关性,评估函数如下:
(2.1)
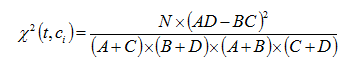
(2.2)
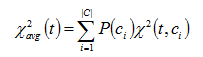
A、B、C、D均表示文本数量,如表2.1所示,N=A+B+C+D。
表2.1
|
|
Ci类文本集合 |
非Ci类文本集合 |
| t出现 |
A |
B |
| t不出现 |
C |
D |
统计量度量词和类别独立性的缺乏程度,越大,独立性越小,相关性越大。表示对所有类别求平均的统计量,它是一个规范化的值,故不同特征项的统计量可进行直接比较。通过设定一个阈值T,把度量值小于T的那些特征过滤掉,剩下的即认为是对分类有贡献的特征。
3 基于决策树的文本分类方法
决策树[5](Decision Tree)又称为分类树(Classification Tree),它是最为广泛应用的归纳推理算法之一,可用于处理类别型或连续型变量的分类预测问题,并可以用图形和if- then 的规则表示模型,可读性较高。决策树模型通过不断地划分数据,使依赖变量的差别最大,最终目的是将数据分类到不同的组织或不同的分枝,在依赖变量的值上建立最强的归类。
决策树是一种监督式的学习方法,产生一种类似流程图的树结构。决策树对数据进行处理是利用归纳算法产生分类规则和决策树,再对新数据进行预测分析。树的终端节点“叶子节点”(Leaf Node),表示分类结果的类别(Class),每个内部节点表示一个变量的测试,分枝(Branch)为测试输出,代表变量的一个可能数值。为达到分类目的,变量值在数据上测试,每一条路径代表一个分类规则。
决策树构建的主要分为两步:第一是选择适当的算法训练样本构建决策树,第二是适当地修剪决策树。
决策树学习主要利用信息论中的信息增益(Infonnation Gain),通过寻找数据集中有最大信息量的变量,建立数据的一个节点,再根据变量的不同值建立树的分枝,每个分枝子集中重复建树的下层结果和分枝的过程,一直到完成建立整株决策树。
决策树学习可能遭遇模型过度适配(Overfitting)的问题,过度适配是指模型过度训练,导致模型记住的不是训练集的一般性而是训练集的局部特性。因此,完整的决策树构造过程,除了决策树的构建外,还应该包含树剪枝(Tree Pruning),解决和避免模型过度配适问题。树剪枝通常使用统计测量值剪去最不可靠的分枝,可用的统计测量有卡方值或信息增益等,如此可以加速分类结果的产生,同时也可提高测试数据能够正确分类的能力。
决策树的算法基本上是一种贪心算法,是由上至下的逐次搜索方式,渐次产生决策树模型结构。Quinlan于1979年提出ID3算法,ID3 算法是著名的决策树归纳算法;算法C4.5和C5.0是ID3算法的修订版本[6]。
CART算法由Friedman等人提出,20世纪80年代以来就开始发展,基于树结构产生分类和回归模型[6]。CART与C4.5 /C5.0算法的最大相异之处是其在每一个节点上都是采用二分法,也就是一次只能够有两个子节点,C4.5/ C5.0则在每一个节点上都可以产生不同数量的分枝。
在实验所使用的Python机器学习模块Sklearn中,采用的是CART算法的优化版本[7]。
4 实验结果及分析
4.1 实验数据集
本实验的数据集包括训练集和测试集,两个数据集使用相同的格式:每一行表示一封电子邮件,第一列是电子邮件ID,第二列表示是否为垃圾邮件,剩余列为邮件中出现的单词及对应次数。
4.2 实验结果评测指标
设测试集合共有N封邮件,为了方便叙述,先定义几个变量,TP表示被正确识别出的垃圾邮件总数;FP表示被误判为垃圾邮件的总数;FN表示被误判为非垃圾邮件的总数;TN表示被正确识别出的非垃圾邮件总数。
根据上述规定,利用以下几个评价指标来衡量垃圾邮件过滤方法的性能[8]:
(1)召回率(Recall):即垃圾邮件检出率。这个指标反映了过滤系统发现垃圾邮件的能力,召回率越高,“漏网”的垃圾邮件就越少。
(2)精确率(Precison):即垃圾邮件检对率。
(3)平均准确率(Average Accuracy):每个类别下准确率的算术平均。
(4)F1值:即召回率和精确率的调和平均。
4.3 实验结果
通过设置不同的卡方检验的阙值T,选择不同的文本分类方法使用训练集对分类器进行训练,然后使用测试集进行测试,测试结果如图3.1所示。

图3.1 实验结果
通过实验结果可以看出朴素贝叶斯,决策树和AdaBoost之间的性能差异。其中,AdaBoost整体表现更好,精确率和F1值都是在98%左右;决策树算法的的各项指标与AdaBoost接近;朴素贝叶斯算法的性能相对较差,但平均准确率和F1值也达到了92%。对于召回率(Recall)来说,三种分类器的召回率的差别不大,都在97%左右。
4.4 实验结果分析
通过实验结果分析可以发现,AdaBoost、决策树和贝叶斯随着特征数量的增加精确率浮动不大,决策树和AdaBoost的精确率基本相似,要高于贝叶斯。在特征数量小于740时,三种分类方法的召回率波动很大;特征数量在740-900之间的时候,三种分类方法的召回率波动较小。
对于决策树分类器来说,在特征数量增加的时候,平均准确率会降低,我们分析认为,随着特征数量的不断增加,将会引入一些不重要的特征,甚至是噪声,而决策树分类器对噪声数据比较敏感。对于朴素贝叶斯分类器,平均准确率和精确率波动较小,分类效率稳定,对缺失数据不太敏感。对于AdaBoost,其可以使用各种方法构建子分类器,分类精度较高,但是通过实验发现,该算法要比另外两种算法在训练过程中耗时多。
5 总结
本文主要介绍了基于内容的垃圾邮件过滤技术,并对邮件的预处理和基于规则的决策树算法进行了较详细的描述。在实验部分,采用了三种文本分类方法,贝叶斯,决策树和AdaBoost,并比较了它们的性能和优缺点。实验结果表明,基于内容的垃圾邮件过滤方法可以达到很好的性能。不过,这些方法虽然效果较好,但也存在耗时、耗资源的问题,因此,将基于内容的垃圾邮件过滤方法与基于黑/白名单的过滤技术、行为模式识别技术等相结合,应是实用的垃圾邮件过滤系统发展的趋势。
参考文献
- 王斌, 潘文锋. 基于内容的垃圾邮件过滤技术综述[J]. 中文信息学报, 2005, 19(5):1-10.
- 范小丽. 文本分类中特征选择的研究与实现[D]. 西北大学, 2011:6-18
- Salton G. A vector space model for automatic indexing[J]. Communications of the Acm, 1975, 18(11):613-620.
- 姚海英. 中文文本分类中卡方统计特征选择方法和TF-IDF权重计算方法的研究[D]. 吉林大学, 2016:18-29
- 周英, 旧金武, 卞月青. 大数据挖掘:系统方法与实例分析[M]. 机械工业出版社, 2016:173-177
- 王洪斌. 基于决策树算法的垃圾邮件通信行为检测过滤技术研究[D]. 哈尔滨理工大学, 2008:20-25
- http://scikit-learn.org/stable/modules/tree.html#tree-algorithms
- 潘文锋. 基于内容的垃圾邮件过滤研究[D]. 中国科学院研究生院(计算技术研究所), 2004:4-17