SpringBoot @Cacheable缓存入门程序
导语
在之前的博客中分享了关于SpringBoot缓存的一些基本的概念,在这篇博客中提供一个小小的入门的实例,通过这个实例可以更好的了解关于SpringBoot缓存有关的知识点。
首先既然是缓存的使用就不得不提及关于缓存的使用场景,在实际的开发中很多的地方都是需要使用到缓存的技术。
- 1.场景1:和数据库中的数据结构保持一致,原样缓存
- 2.场景2:列表排序分页场景的缓存
- 3.场景3:较大的详情内容数据缓存
- 等等场景
在这些场景中都使用了缓存技术,当然这里并不是对于这些缓存场景进行分析,所以不做过多的解释。有兴趣的话可以了解。
在SpringBoot中对于缓存主要有两个步骤,第一开启基于注解缓存,第二标注注解。
入门实例
1.创建对应的MySql数据库和数据表。
配置对应的数据库的链接
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=
spring.datasource.username=
spring.datasource.password=
配置完成数据库连接之后就要建立对应的Mapper对象,当然这里使用的是基于注解的形式,当然也可以是基于配置文件的形式,这里由于功能比较简单所以说使用基于注解的方式进行配置
import com.example.cache.bean.Employee;
import org.apache.ibatis.annotations.*;
@Mapper
public interface EmployeeMapper {
@Select("select * from employee where id = #{id}")
public Employee getEmpById(Integer id);
@Update("update employee set lastName=#{lastName},email=#{email},gender=#{gender},d_id=#{dId} where id=#{id}")
public void updateEmp(Employee employee);
@Delete("delete from employee where id=#{id}")
public void deleteEmpById(Integer id);
@Insert("insert into employee (lastName,email,gender,d_id) values(#{lastName},#{email},#{gender},#{dId})")
public void insertEmployee(Employee employee);
}
在主类上标注扫描Mapper的注解@MapperScan通过这个注解,可以将Mapper注解扫描到Spring容器中。也就是说所有的在对应的mapper包下的标记了@Mapper注解的类都被检查。
//配置扫描包
@MapperScan("com.example.cache.mapper")
@SpringBootApplication
@EnableCaching
public class Springboot01CacheApplication {
public static void main(String[] args) {
SpringApplication.run(Springboot01CacheApplication.class, args);
}
}
2.按照如下的目录结构创建对应的Service和Controller层。
Service层
import com.example.cache.bean.Employee;
import com.example.cache.mapper.EmployeeMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
@Service
public class EmployeeService {
@Autowired
EmployeeMapper employeeMapper;
/**
* @Cacheable
* 将方法的运行结果进行缓存,如果需要相同的数据,就可以直接从缓存中获取
* 不用调用方法
*
* CacheManager管理多个Cache组件,对缓存真正的CRUD操作在Cache组件中,每一个缓存组件
* 有自己唯一一个名字
* value/cacheNames:指定缓存组件的名字
* key ;缓存数据时使用的key;可以用他来指定,默认使用方法参数的值 1-方法返回值
* 编写SPEL表达式 #id:参数id的值, #a0,#p0,#root.args[0]
* keyGenerator key的生成器,可以自己指定key的生成器的组件ID
* key/keyGenerator 二选一
*
* cacheManager 指定缓存管理器,或者指定缓存解析器cacheResolver
*
* condition 指定复合条件的情况下才缓存
*
* unless 否定缓存,当unless指定的条件为true,方法的返回值就不会缓存,可以获取到结果进行判断
*
* sync 是否使用异步模式
* @param id
* @return
*/
@Cacheable(cacheNames = {"emp"})
public Employee getEmp(Integer id){
System.out.println("查询"+id+"号员工");
return employeeMapper.getEmpById(id);
}
}
注意
在这里介绍点新的东西@Cacheable注解标注这个方法的返回值是可以缓存的,也就是说可以将这个注解的标注的方法返回值作为缓存。而这个注解的源码如下
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Cacheable {
/**
* 缓存管理器的名称.
*/
@AliasFor("cacheNames")
String[] value() default {};=
@AliasFor("value")
String[] cacheNames() default {};
//标注一个缓存的key
String key() default "";
//key的生成器
String keyGenerator() default "";
//缓存管理器
String cacheManager() default "";
//缓存分析器
String cacheResolver() default "";
//当满足条件的饿时候开始缓存
String condition() default "";
//当条件不满足的时候开始缓存
String unless() default "";
//是否同步缓存
boolean sync() default false;
controller层
import com.example.cache.bean.Employee;
import com.example.cache.service.EmployeeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class EmployeeController {
@Autowired
EmployeeService employeeService;
@GetMapping("/emp/{id}")
public Employee getEmployee(@PathVariable Integer id){
Employee emp = employeeService.getEmp(id);
return emp;
}
}
完成以上操作之后就可以通过浏览器访问对应的localhost:8080端口执行缓存操作,当我们第一次请求两个员工的时候都会在后台打印出查询结果当然了这个需要打开对应的日志级别。
logging.level.com.example.cache.mapper=debug
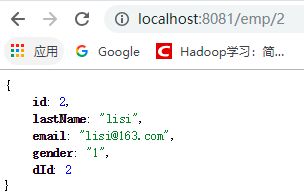
如图所示。当第二次访问相同的数据的时候就不需要再通过插叙数据库所获取到。所以就不会再控制台输出查询语句。

总结
其实SpringBoot的缓存原理是很简单的,通过这个例子看到了关于缓存的基本使用方式,了解的关于@Cacheable注解的相关内容。