SEO (Search Engine Optimization),即搜索引擎优化。简单来说,SEO就是您可以使用提升网站排名的所有方法的总称,SEO用于确保您的网站及其内容在搜索引擎结果页面(SERP)上的可见性。
验证你的网站(让你博客被搜索引擎找到)
查看你的博客是否被收入
在谷歌或者百度的搜索链接中,使用以下格式可以直接搜索自己的域名, 如果能搜索到就说明已经被收录,反之则没有。可以直接搜索自己的域名,或者加一些关键词来更好地判断,例如:
site: https://jimmyju.github.io/
提交我们的网站
若未被搜索引擎收录,则需进行以下配置,首先要让搜索引擎先验证我们对网站的所有权,两个搜索引擎提交的入口分别为:
Google Search Console
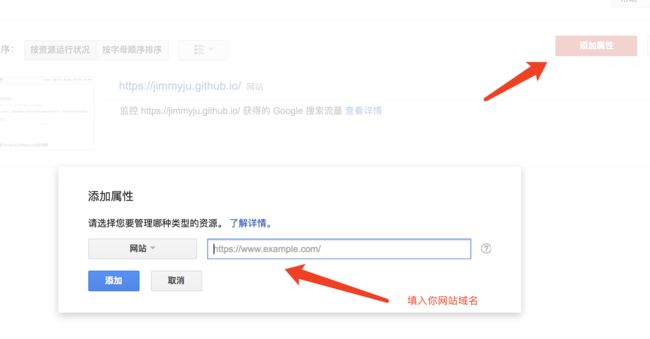
百度站长平台
有多种验证方式,这里推荐 HTML 文件上传方式。下载 HTML 验证文件,拷贝到 Hexo/sources/ 文件夹下,为了使 hexo 不处理这两个验证文件,并且不生成关于这两个文件的 sitemap,我们需要打开验证文件,在最上面添加以下代码:
layout: false
---
然后执行 hexo 部署命令
hexo clean
hexo g
hexo d
最后返回验证页面,就可以查看验证是否通过了
生成Sitemap
Sitemap即网站地图,它的作用在于便于搜索引擎更加智能地抓取网站。最简单和常见的sitemap形式,是XML文件,在其中列出网站中的网址以及关于每个网址的其他元数据
安装sitemap生成插件
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save
编辑站点目录下的_config.yml,添加一下字段
#hexo sitemap
sitemap:
path: sitemap.xml
baidusitemap:
path: baidusitemap.xml
之后在执行 hexo g 后, public目录下发现生成了 sitemap.xml和baidusitemap.xml 就表示配置成功了。
提交sitemap
向谷歌提交
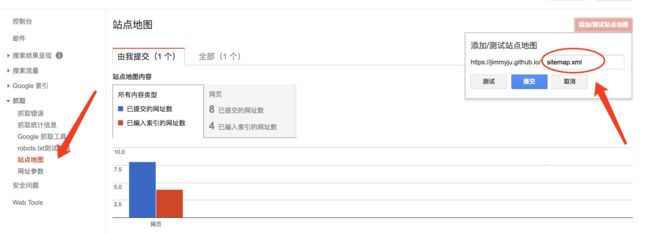
向谷歌提交 sitemap 比较简单,登录 Google Search Console ,选择已经验证过的站点,在抓取 -> 站点地图 中,右上角可看到 添加 / 测试站点地图,添加 sitemap.xml 的链接即可,谷歌效率较高,一般当天或者第二天就能搜到微博了。如图:
向百度提交
与谷歌类似,我们可以直接向百度交 sitemap,登录 百度站长平台,点击 网页抓取-> 链接提交,在 自动提交中选择 sitemap,输入自己的域名加 baidusitemap.xml 即可,之后可查看 url 提取是否成功。
由于 GitHub 屏蔽了百度的爬虫,即使提交成功,百度知道这里有可供抓取的链接,也不一定能抓取成功。 首先我们先检测一下百度爬虫是否可以抓取网页。在百度站长平台网页抓取->抓取诊断 中,选择PC UA点击抓取 , 查看抓取状态, 如果显示 抓取失败, 则需要进一步的配置。
主动推送和自动推送
百度提供了多种链接提交的方式,可以综合使用,互为补充。
如何选择链接提交方式
1、主动推送:最为快速的提交方式,推荐您将站点当天新产出链接立即通过此方式推送给百度,以保证新链接可以及时被百度收录。
2、自动推送:最为便捷的提交方式,请将自动推送的 JS 代码部署在站点的每一个页面源代码中,部署代码的页面在每次被浏览时,链接会被自动推送给百度。可以与主动推送配合使用。
3、sitemap:您可以定期将网站链接放到 sitemap 中,然后将 sitemap 提交给百度。百度会周期性的抓取检查您提交的 sitemap,对其中的链接进行处理,但收录速度慢于主动推送。
4、手动提交:一次性提交链接给百度,可以使用此种方式
自动推送
next 主题已经部署了自动推送的代码,我们只需在主题配置文件 中找到 baidu_push 字段 , 设置其为 true 即可。
主动推送
我这里用的python自动推送脚本(Mac环境)如下所示:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author: LoveNight
# @Last Modified by: LoveNight
# @Last Modified by: Keith
import os
import sys
import json
from bs4 import BeautifulSoup as BS
import requests
#import msvcrt
"""
hexo 博客专用,向百度站长平台提交所有网址
本脚本必须放在hexo博客的根目录下执行!需要已安装生成百度站点地图的插件。
百度站长平台提交链接:http://zhanzhang.baidu.com/linksubmit/index
主动推送:最为快速的提交方式,推荐您将站点当天新产出链接立即通过此方式推送给百度,以保证新链接可以及时被百度收录。
从中找到自己的接口调用地址
python环境:
pip install beautifulsoup4
pip install requests
xcode-select --install
pip install lxml
"""
# ❌❌❌ 抄的需要更改这个URL!!!❌❌❌
url = 'http://data.zz.baidu.com/urls?site=jimmyju.github.io&token=6Q3qdoIrzAtnwLWj'
baidu_sitemap = os.path.join(sys.path[0], 'public', 'baidusitemap.xml')
google_sitemap = os.path.join(sys.path[0], 'public', 'sitemap.xml')
sitemap = [baidu_sitemap, google_sitemap]
assert (os.path.exists(baidu_sitemap) or os.path.exists(
google_sitemap)), "没找到任何网站地图,请检查!"
# 从站点地图中读取网址列表
def getUrls():
urls = []
for _ in sitemap:
if os.path.exists(_):
with open(_, "r") as f:
xml = f.read()
soup = BS(xml, "xml")
tags = soup.find_all("loc")
urls += [x.string for x in tags]
if _ == baidu_sitemap:
tags = soup.find_all("breadCrumb", url=True)
urls += [x["url"] for x in tags]
return urls
# POST提交网址列表
def postUrls(urls):
urls = set(urls) # 先去重
print("一共提取出 %s 个网址" % len(urls))
print(urls)
data = "\n".join(urls)
return requests.post(url, data=data).text
if __name__ == '__main__':
urls = getUrls()
result = postUrls(urls)
print("提交结果:")
print(result)
# msvcrt.getch()
添加robots.txt
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它的作用是告诉搜索引擎此网站中哪些内容是可以被爬取的,哪些是禁止爬取的。
在 source 目录下增加 rebots.txt 文件,网站生成后在网站的根目录(站点目录/public/)下。
(请将域名改为自己的网站)
User-agent: *
Allow: /
Allow: /archives/
Allow: /categories/
Allow: /tags/
Disallow: /vendors/
Disallow: /js/
Disallow: /css/
Disallow: /fonts/
Disallow: /vendors/
Disallow: /fancybox/
Sitemap: https://你的域名/sitemap.xml
Sitemap: https://你的域名/baidusitemap.xml
Allow表示允许被访问的,Disallow是不允许的意思。注意后面两个Sitemap就是网站地图了。而网站地图前面说了是给爬虫用的。这里配置在robots中。
Url持久化
我们可以发现hexo默认生成的文章地址路径是 【网站名称/年/月/日/文章名称】。
这种链接对搜索爬虫是很不友好的,第一它的url结构超过了三层,太深了。
下面我推荐一种方式:
安装 hexo-abbrlink
npm install hexo-abbrlink --save
然后配置_config.yml
# permalink: :title/
permalink: archives/:abbrlink.html
abbrlink:
alg: crc32 # 算法:crc16(default) and crc32
rep: hex # 进制:dec(default) and hex

添加 nofollow 标签
给非友情链接的出站链接添加「nofollow」标签,nofollow 标签是由谷歌领头创新的一个「反垃圾链接」的标签,并被百度、yahoo 等各大搜索引擎广泛支持,引用 nofollow 标签的目的是:用于指示搜索引擎不要追踪(即抓取)网页上的带有 nofollow 属性的任何出站链接,以减少垃圾链接的分散网站权重。
首先修改 footer.swig(your-hexo-site\themes\next\layout_partials)
{{ __('footer.powered', 'Hexo') }}
改成
{{ __('footer.powered', 'Hexo') }}
改成
再修改 sidebar.swig(your-hexo-site\themes\next\layout_macro)
{{ name }}
改成
{{ name }}
改成
优化都完成后可通过谷歌搜索文章标题,测试是否被收录及排名。
页面关键字优化
title
文件路径是your-hexo-site\themes\next\layout\index.swig,打开编辑:
{% block title %}{{ config.title }}{% if theme.index_with_subtitle and config.subtitle %} - {{config.subtitle }}
改为:
{% block title %}{{ config.title }}{% if theme.index_with_subtitle and config.subtitle %} - {{config.subtitle }}{% endif %}{{ theme.description }} {% endblock %}
keywords(关键词、关键字)
keywords在你_config.yml配置文件中就有。注意的是除了根目录上的要修改以外还有主题里的。否则就会出现默认的keywords。
description
description就是这个页面的描述,随便写什么。
Next主题自带SEO优化选项
主题配置文件_config.yml中有个选项是seo,默认是false,改成true 即开启了seo优化,如改变博文title等,然后相同文件下有个关键字选项keywords填充上,写博文时最好每篇博文都加上keywords。hexo的根目录配置文件_config.yml中title、subtitle和description也建议填上。
个人博客
参考链接
Hexo 博客搜索 SEO 优化 -- 谷歌篇
hexo的博客让百度收录
hexo博客SEO优化
提交 sitemap 及解决百度爬虫无法抓取 GitHub Pages 链接问题