上海二手房价数据分析
目的:本篇给大家介绍一个数据分析的初级项目,目的是通过项目了解如何使用Python进行简单的数据分析。
数据源:博主通过爬虫采集的安X客上海二手房数据,由于能力问题,只获取了2160条数据。
数据初探
首先导入要使用的科学计算包numpy,pandas,可视化matplotlib,seaborn
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
然后导入数据,并进行初步的观察,这些观察包括了解数据特征的缺失值,异常值,以及大概的描述性统计。
#coding:utf8
data=pd.read_csv('house_anjuke.csv',encoding='gbk')
data.head()
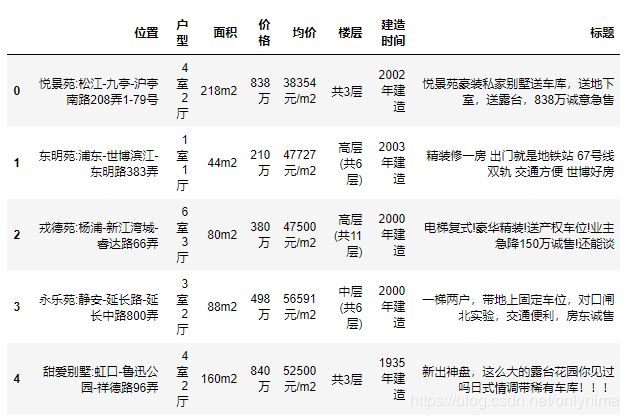
初步观察到一共有7个特征变量,价格在这里是我们的目标变量,然后我们继续深入观察一下。
检查缺失值:
data.info()
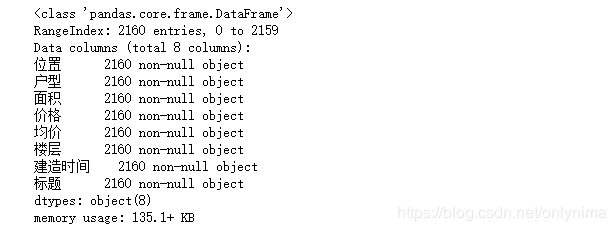
发现有2160条数据,没有缺失值。
提取有效信息:
data['region']=data['位置'].str.split(':').str[1].str.split('-').str[0]
data['district']=data['位置'].str.split(':').str[1].str.split('-').str[1].str.split('-').str[0]
data['name']=data['位置'].str.split(':').str[0]
data['house_area']=data['面积'].str.split('m').str[0]
data['room']=data['户型']
data['year']=data['建造时间'].str[:4]
data['floor']=data['楼层'].str.split("(").str[1].str.split(")").str[0]
data['levels']=data['楼层'].str.split("(").str[0]
data['house_price']=data['价格'].str[:-1]
data['per_square_price']=data['均价'].str[:-4]
这时候查看缺失值:
data.info()

发现floor有很多缺失值,我们先用levels填充一下。
data['floor']=data['floor'].fillna(data['levels'])
清除脏数据:
del data['户型']
del data['位置']
del data['面积']
del data['价格']
del data['均价']
del data['建造时间']
del data['楼层']
del data['标题']
data['house_price']=data['house_price'].astype(float)
data['per_square_price']=data['per_square_price'].astype(float)
data['house_area']=data['house_area'].astype(float)
data['year']=data['year'].astype(int)
data.describe()
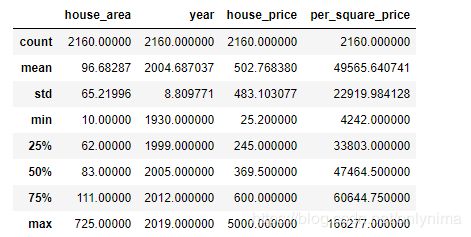
上面给出的特征是数值的一些统计值,包括平均数、标准差、中位数、最小值、最大值,25%分位数,75%分位数。这些统计结果简单直接,比如house_area的最大值为725平方米,最小值为10平方米,那么我们就要思考这个在实际中是不是存在的,如果不存在没有意义,那么这个数据就是一个异常值,会严重影响模型的性能。
数据可视化分析
Region特征分析
对于区域特征,我们可以分析不同区域房价和数量的对比。
data_house_count=data.groupby('region')['house_price'].count().sort_values(ascending=False).to_frame().reset_index()
data_house_mean=data.groupby('region')['per_square_price'].mean().sort_values(ascending=False).to_frame().reset_index()
f,[ax1,ax2,ax3]=plt.subplots(3,1,figsize=(20,15))
sns.barplot(x='region',y='per_square_price',palette='Blues_d',data=data_house_mean,ax=ax1)
ax1.set_title('上海各大区二手房每平米单价对比',fontsize=15)
ax1.set_xlabel('区域')
ax1.set_ylabel('每平米单价')
sns.barplot(x='region',y='house_price',palette='Greens_d',data=data_house_count,ax=ax2)
ax2.set_title("上海各大区二手房数量对比",fontsize=15)
ax2.set_xlabel('区域')
ax2.set_ylabel('数量')
sns.boxplot(x='region',y='house_price',data=data,ax=ax3)
ax3.set_title('上海各大区二手房房屋总价',fontsize=15)
ax3.set_xlabel('区域')
ax3.set_ylabel('房屋总价')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()
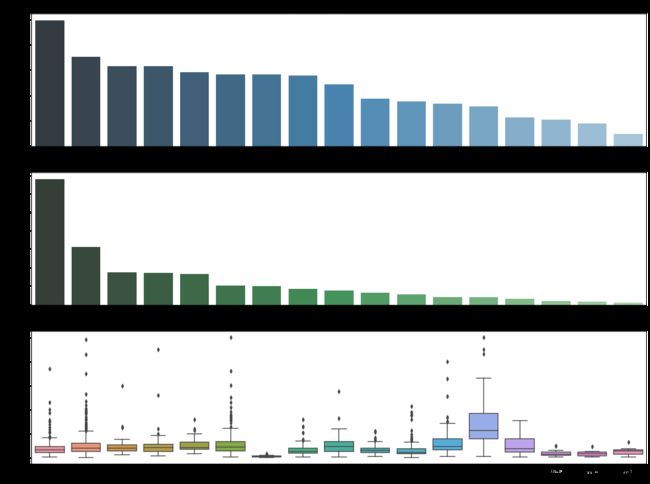
二手房均价:黄浦区的房价最贵均价大约10万/平,因为黄浦区位于中环,且风景好。其次是徐汇区大约7万/平,然后是静安区大约6.5万/平。
二手房数量:从数量统计上来看,目前浦东和闵行二手房数量最多,都超过300套。
二手房总价:通过箱型图看到,各大区域房屋总价中位数都在1000万以下,且房屋总价离散值较高,黄浦和闵行最高达到5000万,说明房屋价格特征不是理想的正太分布。
House_area特征分析
f,[ax1,ax2]=plt.subplots(1,2,figsize=(15,5))
sns.distplot(data['house_area'],bins=20,ax=ax1,color='r')
sns.kdeplot(data['house_area'],shade=True,ax=ax1)
#房屋面积和出售价格的关系
sns.regplot(x='house_area',y='house_price',data=data,ax=ax2)
plt.show()

通过 distplot 和 kdeplot 绘制柱状图观察 area 特征的分布情况,属于长尾类型的分布,这说明了有很多面积很大且超出正常范围的二手房。
通过 regplot 绘制了 area 和 price 之间的散点图,发现 area 特征基本与Price呈现线性关系,符合基本常识,面积越大,价格越高。
Room特征分析
f,ax1=plt.subplots(figsize=(20,20))
sns.countplot(y='room',data=data,ax=ax1)
ax1.set_title('房屋户型',fontsize=15)
ax1.set_xlabel('数量')
ax2.set_ylabel('户型')
plt.show()

看图发现各种厅室组合搭配,其中,2室2厅占绝大部分,其次是3室2厅,2室1厅,1室1厅。 这样的特征肯定是不能作为机器学习模型的数据输入的,需要使用特征工程进行相应的处理。
Floor特征分析
f,ax1=plt.subplots(figsize=(20,5))
sns.countplot(x='floor',data=data,ax=ax1)
ax1.set_title('房屋总楼层',fontsize=15)
ax1.set_xlabel('楼层')
ax1.set_ylabel('数量')
plt.show()
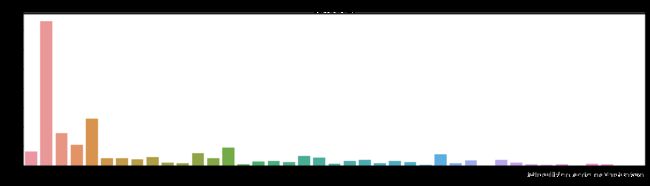
从上图能看到各种楼层分类。其中,共6层占绝大部分,其次是共18层,共11层。
Levels特征分析
f,ax1=plt.subplots(figsize=(20,5))
sns.countplot(x='levels',data=data,ax=ax1)
ax1.set_title('房屋层级',fontsize=15)
ax1.set_xlabel('层级')
ax1.set_ylabel('数量')
plt.show()
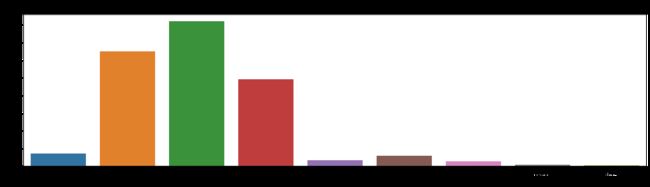
可以看到,中层二手房数量最多,在中国正常情况下中间楼层是比较受欢迎的,价格也高,底层和顶层受欢迎度较低,价格也相对较低。所以楼层是一个非常复杂的特征,对房价影响也比较大。但出现其他几种分类“共x层”需要处理。
Year特征分析
f,[ax1,ax2]=plt.subplots(1,2,figsize=(15,5))
sns.distplot(data['year'],bins=20,ax=ax1,color='r')
sns.kdeplot(data['year'],shade=True,ax=ax1)
#建房时间和出售价格的关系
sns.regplot(x='year',y='house_price',data=data,ax=ax2)
plt.show()
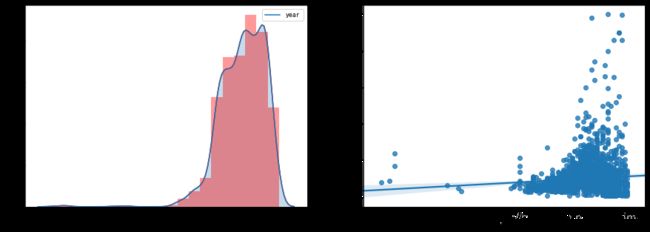
通过上图,发现大部分房子还是集中在2000年以后的, year 特征基本与Price呈现线性关系,符合基本常识,建造年份越近,价格越高。不过也有几套1940年以前的房子在1000万左右。
特征工程
特征工程包括的内容很多,有特征清洗,预处理,监控等,而预处理根据单一特征或多特征又分很多种方法,如归一化,降维,特征选择,特征筛选等等。这么多的方法,为的是什么呢?其目的是让这些特征更友好的作为模型的输入,处理数据的好坏会严重的影响模型性能,而好的特征工程有的时候甚至比建模调参更重要。
Floor
先来看看没经过处理的floor特征值是什么样的
data['floor'].value_counts()

具体的用法就是使用 str.extract() 方法,里面写的是正则表达式。
data['floor'] = data['floor'].str.extract('^.*?(\d+).*', expand=False).astype('int64')
Room
data['room'].value_counts()

这种格式的数据也是不能作为模型的输入的,我们不如干脆将"室"和"厅"都提取出来,单独作为两个新特征,这样效果可能更好。
data['room_num']=data['room'].str.extract('^(\d).*',expand=False).astype('int64')
data['hall_num']=data['room'].str.extract('^\d.*?(\d).*',expand=False)
data['hall_num']=data['hall_num'].fillna(0)
创建新特征
data['total_num']=data['room_num'].astype(float)+data['hall_num'].astype(float)
# 删除无用特征
data=data.drop(['room','per_square_price','name','district','hall_num','room_num'],axis=1)
训练模型、调参和可视化
我们来为模型选择一种算法,这里预测二手房成交价格是个回归问题,我们选择【RandomForestRegression随机森林回归】
因为scikit-learn是个傻瓜式工具包,我们只需要为算法调节一些参数。分别是随机树的棵树(n_estimators)和树的最大深度(max_depth)。在scikit-learn里面最佳参数的查找也是可以用网格搜索grid_search查找的。
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import make_scorer
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
#将价格设为预测目标
target=data['house_price']
#删除不作为特征输入的列
data.drop('house_price',axis=1,inplace=True)
data.drop('region',axis=1,inplace=True)
data.drop('levels',axis=1,inplace=True)
#分割数据(注:正规做法是这里是要将数据集分割为训练集和测试集的,由于我们下面会启动五折交叉验证,为了节省数据集就不再分割了)
#X_train,X_test,y_train,y_test = train_test_split(data,target,random_state = 1)
x_train=data
y_train=target
#调用scikit-learn的网格搜索,传入参数选择范围,并且制定随机森林回归算法,cv = 5表示5折交叉验证
param_grid={"n_estimators":[5,10,50,100,200,500],"max_depth":[5,10,50,100,200,500]}
grid_search=GridSearchCV(RandomForestRegressor(),param_grid,cv=5)
#让模型对训练集和结果进行拟合
grid_search.fit(x_train,y_train)
print(np.around(grid_search.best_score_,2))
输出:
0.75
grid_search.best_params_
输出:
{‘max_depth’: 5, ‘n_estimators’: 50}
结束后可以看到最终我们获得了一个约0.75分的模型,即约75%的数据可以用模型来解释。该模型最佳的参数选择是50棵树,5层深度。
scikit-learn的树算法还提供了一个叫特征权重的属性。我们可以把这个属性调出来可视化一下,看下从机器的“眼睛”如何解读影响房价的这些特征因素。代码是这样的:
#特征重要性可视化
features=x_train.columns
importance=grid_search.best_estimator_.feature_importances_
fi=pd.Series(importance,index=features)
fi=fi.sort_values(ascending=False)
ten=fi[:4]
fig=plt.figure(figsize=(16,9))
ax=fig.add_subplot(1,1,1,facecolor='whitesmoke',alpha=0.2)
ax.grid(color='grey',linestyle=":",alpha=0.8,axis='y')
ax.barh(ten.index,ten.values,color = "dodgerblue")
ax.set_xticklabels([0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8],fontsize = 22)
ax.set_yticklabels(ten.index,fontsize = 22)
ax.set_xlabel("importance",fontsize = 22)
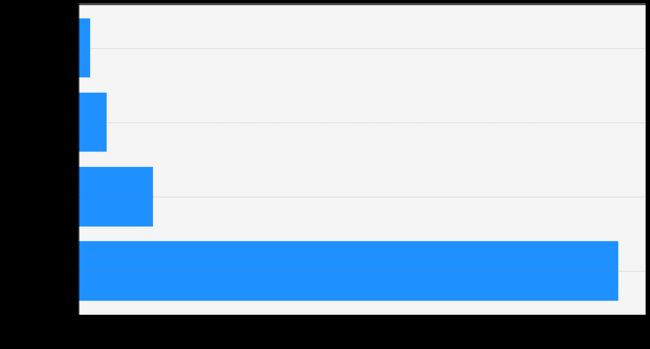
上图展示了机器评价重要程度前几位的特征,所有重要程度的和为1。
可以看出排在第1位的是“面积”,的确符合常识,面积是与总价关联性最强的因素,影响权重在0.8左右。
第2位机器选中的是“层数(高度)”。
第3,4位分别是“建设年份”和“总户数(单元数)”。
未完待续…