PostgreSQL 之 流复制概述
基于流复制协议的wal日志从主节点到备节点实时复制传输与复用。为了实现数据库的高可用,一般需要搭建主库和备库。
流复制是搭建主备库的一种有效方式,它不需要额外增加软件,只需要在单数据库模式的基础上,再复制一份PostgreSQL数据库到另外的一台机器上,对两台数据库进行参数配置,即可实现。
这两套数据库之间的数据,通过wal日志,后台自动同步。对外部的应用程序而言,可以看作是两套数据库,需要根据业务需要,显式分别连接不同的数据库。
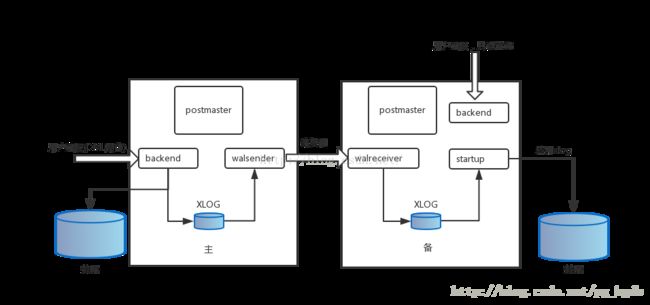
那流复制是怎么实现的呢?请参见下图,流复制主要涉及到几个backend辅助进程:walwriter,walsender,walreceiver,startup。
当用户连接进行数据操作,产生对应的WAL日志记录后,walwriter会周期性地把产生的WALpage刷新到磁盘中,如果配置了备库,则walsender会不断将WAL page发给备库的walreceiver进程,walreceiver进程会把对应WAL page直接写到本地磁盘,同时slave上的startup辅助进程会不断地应用xlog日志,改变本地数据,实现与主库之间的数据同步。而且,通过配置,备库是可以接受用户的只读请求。
Postgresql不同版本流复制的主要区别如下:
而PostgreSQL9.0之前提供的方法是主库写完一个WAL日志文件后,才把WAL日志文件传送到备库,这样的方式导致主备延迟特别大。
PostgreSQL在9.0之后引入了主备流复制机制,通过流复制,备库不断的从主库同步相应的数据,并在备库apply每个WAL record,每次传输单位是WAL日志的record。
同时PostgreSQL9.0之后提供了Hot Standby,备库在应用WAL record的同时也能够提供只读服务,大大提升了用户体验。
附:
9.0开始支持1+n的异步流复制.
9.1支持1+1+n的同步和异步流复制
9.2开始支持级联流复制
9.3开始支持跨平台的流复制协议
9.3开始流复制协议增加了时间线文件传输的协议,支持自动切换时间线.
9.4可以使用流复制做增量数据同步,所以停机服务时间会非常短。
流复制传递日志两种方式:
异步流复制
同步流复制
两者的主要区别是什么?
在异步流复制的情况下,事务被提交到master之后数据才可以被复制。
换句话说,slave从不会超前master,就写操作而言,通常滞后于master一些,此延迟(delay)被称为滞后性(lag)。
同步复制较高数据一致性规则
如果您决定使用同步复制,系统必须确保通过事务写入的数据至少事务同时在两台服务器上提交。这意味着:slave不滞后于master,而且终端用户在两台服务器上看到的数据是一致的。
考虑数据丢失
假设我们正在以异步复制方式同步数据:
1.事物发送到master。
2.事物提交到master。
3.在事物发送到slave之前,master宕机。
4.slave永远都不会收到这个事务。
在异步复制的情况下,有一个窗口(滞后),在滞后窗口期间数据会丢失。滞后窗口的大小因设置类型的不同而不同。它的大小非常短(几毫秒)或非常长(几分钟,几小时,几天)。
一个重要的事实是:数据可能丢失。一个小的滞后只会是数据丢失的可能性较小,但任何大于零的滞后都容易导致数据丢失。
如果您想确保数据永远不丢失,您必须切换到同步复制。
一个同步事务是同步的,因为如果事物提交到了两台服务器它才是有效的。
考虑性能问题
通过网络发送不必要的消息的开销是昂贵的和费时的。
如果一个事务采用同步的方式复制,PostgreSQL必须确保数据到达第二个节点,这样就会导致延迟问题。
同步复制要求在数据写入Standby数据库后,事务的commit才返回,所以Standby库出现问题时,会导致主库被hang住。(解决这个问题的方法是启动两个Standby数据库,这两个standby数据库只要有一个是正常的,就不会让主库hang住)
在许多方面,同步复制比异步复制要昂贵很多,因此如果这种消耗确实需要和调整,应该三思而后行。(只在需要的时候使用同步复制)
by 波罗