hadoop组件---面向列的开源数据库(七)--phoenix查询hbase--映射和常用命令
我们在之前得文章中已经 成功安装了 phoenix,本章需要学习使用phoenix进行增删改查等常用操作。
hadoop组件—面向列的开源数据库(六)–使用sql访问hbase的组件–phoenix全面了解和安装
关于映射和注意事项–看不到原hbase的表和查询不到数据的问题解决
需要注意得一点是 :
本地安装好 Phoenix 之后,用 phoenix 的 !talblse 命令列出所有表,会发现 HBase 原有的表没有被列出来。而使用 Phoenix sql 的 CREATE 语句创建的一张新表,则可以通过 !tables 命令展示出来。
这是因为 Phoenix 无法自动识别 HBase 中原有的表,所以需要将 HBase 中已有的做映射,才能够被 Phoenix 识别并操作。说白了就是要需要告诉 Phoenix 一声 xx 表的 xx 列是主键,xx 列的数据类型。
同时也要在使用时注意 一些 一致性的问题,比如 正常通过接口直接写数据进Phoenix表,相应的索引表也是会更新的,但是直接写数据到底层hbase表,这时候对应的索引表是不会更新,从而影响正常的用户访问。需要数据写进主数据表的时候,往索引表也写一份,这样,外部接口访问Phoenix的数据就正常了。
创建映射示例
使用
hbase shell
进入hbase命令行模式
创建一个 HBase 表并插入一定量数据
create 'test_table','0'
put 'test_table', 'row001','0:name','Joe'
put 'test_table', 'row002','0:name','Li'
put 'test_table', 'row003','0:name','Joey'
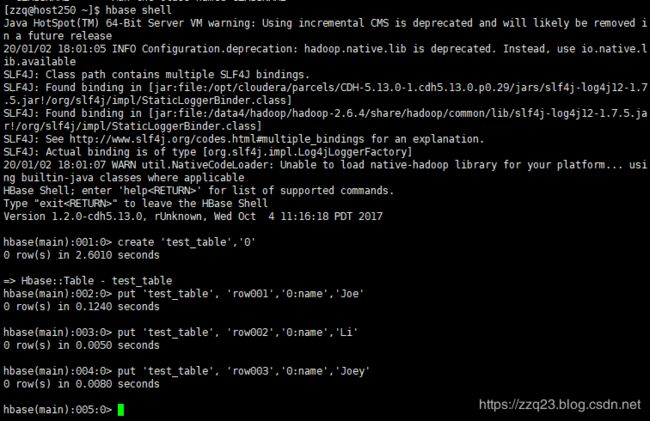
使用命令查询新创建的表
scan 'test_table'
数据如图所示:

在phoenix安装bin目录中 使用如下命令进入phoenix命令行模式
例如安装目录是 /usr/local/phoenix-4.14.0/bin,对应hbase的regionserver节点是host217,详情参考上篇文章。
使用命令启动
cd /usr/local/phoenix-4.14.0/bin
./sqlline.py host217
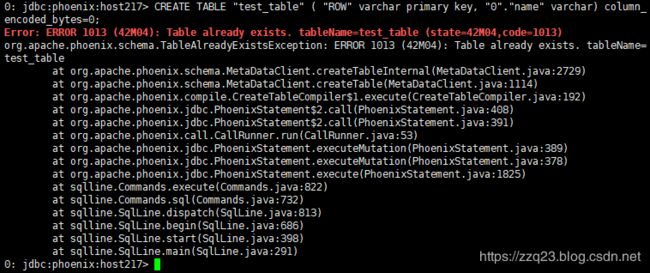
在phoenix命令行中使用命令创建对应的表格:
phoenix-4.10以前的版本使用命令:
CREATE TABLE "test_table" ( "ROW" varchar primary key, "0"."name" varchar);
phoenix-4.10之后的版本使用命令:
CREATE TABLE "test_table" ( "ROW" varchar primary key, "0"."name" varchar) column_encoded_bytes=0;
创建过程需要几秒钟,请耐心等待。
这里有两点需要注意:
-
Phoenix 对表名和列名都是区分大小写的,但是,如果不加双引号,则默认为大写。例如上面这条语句,如果 test_table 不加双引号,则创建后的表名则是 TEST_TABLE。
-
表名要和 HBase 中建立的表名一致。HBase 默认的主列名是 ROW,所以要将“ROW”设置为主键。列簇和列名也要用双引号括起来,要不然小写会自动变成大写。
创建成功如图:

在phoenix命令行中使用命令SELECT语句查询
SELECT * FROM "test_table";
可能遇到的情况–查询不到数据–显示空白
如果我们使用的是 Phoenix 4.10 及以上的版本,可能会遇到查不出数据的情况,如下图所示:

这是因为在 4.10 版本之后,Phoenix 对列的编码方式有所改变
(官方文档地址:http://phoenix.apache.org/columnencoding.html)
就拿上面的例子来说,同样是"name"这个列,看起来列名是一样的,但是 Phoenix 对这个列名进行了编码,也就是说 Phoenix 创建的 name 列实际上和 HBase 里的 name 列不是一个列了,所以查不出来数据。
那么如何解决这个问题呢?
在使用 Phoenix 创建表的时候,需要设置 COLUMN_ENCODED_BYTES 属性为 0,即不让 Phoenix 对 column family 进行编码。
CREATE TABLE "test_table" ( "ROW" varchar primary key, "0"."name" varchar) column_encoded_bytes=0;
这样就能查出数据了。
另外,根据官方文档的内容,“One can set the column mapping property only at the time of creating the table. ”,也就是说只有在创建表的时候才能够设置属性。
如果在创建的时候没有设置,之后怎么去设置就不太清楚了,可能是无法改变,至少目前我还没有找到相关方法。所以大家在创建映射表的时候一定要注意设置属性。
重复创建表格会报错,删除映射表,会同时删除原有 HBase 表。所以如果一开始创建设置不编码列属性column_encoded_bytes=0,而且只做查询操作,还有另外的方式解决,那就是做视图映射。
视图映射
如果只做查询操作的话,建议大家使用视图映射的方式,而非表映射。因为一旦出现问题,例如上面提到的,在创建映射表时如果忘记设置属性(4.10版之后),那么想要删除映射表的话,HBase 中该表也会被删除,导致数据的丢失。而如果是用视图映射,则删除视图不会影响原有表的数据。
创建视图的语句同创建表差不多,而且 4.10前后的版本都可使用,如下:
CREATE VIEW "test_table" ( "ROW" varchar primary key, "0"."name" varchar);
需要注意的是 4.10之后的phoenix版本不能先创建表映射,再创建 视图映射。 否则会报错如下:
Error: ERROR 1036 (42J04): Cannot modify the primary key of a VIEW if last PK column of parent is variable length. columnName=test_table.ROW (state=42J04,code=1036)

解决方法:
新创建表格,把原来的数据导入新表中。
我这里直接新建一个新的原生hbase表,在hbase的shell命令行中使用命令:
create 'test_table_new','0'
put 'test_table_new', 'row001','0:name','Joe'
put 'test_table_new', 'row002','0:name','Li'
put 'test_table_new', 'row003','0:name','Joey'
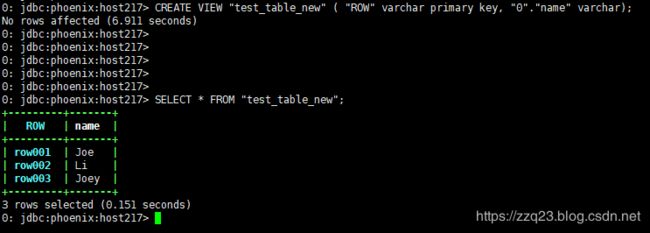
在phoenix命令行中创建视图如下:
CREATE VIEW "test_table_new" ( "ROW" varchar primary key, "0"."name" varchar);
成功创建视图后即可使用select语句等进行查询如下:
SELECT * FROM "test_table_new";
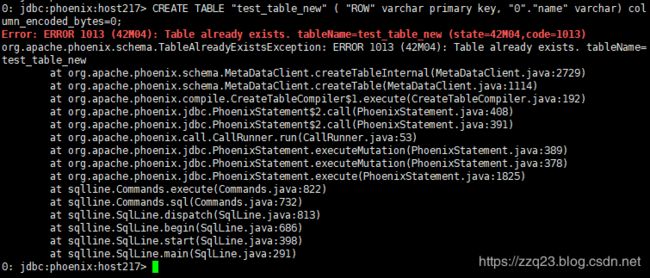
有了视图之后 再创建 表映射,也会失败, 不过 删除 视图不会影响hbase的原表。
CREATE TABLE "test_table_new" ( "ROW" varchar primary key, "0"."name" varchar) column_encoded_bytes=0;
报错如下:
Error: ERROR 1013 (42M04): Table already exists. tableName=test_table_new (state=42M04,code=1013)
关于映射的注意事项
1、需要将原有 HBase 中的表做映射才能后使用 Phoenix 操作
2、Phoenix 区分大小写,切默认情况下会将小写转成大写,所以表名、列簇、列名需要用双引号。
3、Phoenix 4.10 版本之后,在创建表映射时需要将 COLUMN_ENCODED_BYTES 置为 0。
4、删除映射表,会同时删除原有 HBase 表。所以如果只做查询操作,建议做视图映射。
Phoenix 使用shell运行常用sql
创建表
CREATE TABLE IF NOT EXISTS test_table_person (
grade CHAR(1) NOT NULL,
name VARCHAR NOT NULL,
age INT,
CONSTRAINT person PRIMARY KEY (age, name)
);
主键的值对应HBase中的RowKey,列族不指定时默认是0,非主键的列对应HBase的列。
插入或更新数据
UPSERT INTO test_table_person VALUES('A','Joe',18);
UPSERT INTO test_table_person(name,age) VALUES('Joey',16);
UPSERT INTO test_table_person(name,age) VALUES('Joe',16);
如果主键的值重复,那么进行更新操作,否则插入一条新的记录(在进行更新时,没有更新的列保持原值,在进行插入时,没有插入的列为null)
在使用UPSERT时,主键的列不能为空(包括联合主键)
插入另一个表的数据
UPSERT INTO targetTable SELECT * FROM sourceTable;
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100
查询数据
SELECT * FROM test_table_person WHERE name = 'Joey' AND age > 15 ORDER BY age DESC;
在进行查询时,支持ORDER BY、GROUP BY、LIMIT、JOIN等操作,同时Phoenix提供了一系列的函数,其中包括COUNT()、MAX()、MIN()、SUM()等,具体的函数列表可以查看:http://phoenix.apache.org/language/functions.html
不管条件中的列是否是联合主键中的,Phoenix都可以支持。
创建自定义函数方法
CREATE FUNCTION my_reverse(varchar) returns varchar as 'com.mypackage.MyReverseFunction' using jar 'hdfs:/localhost:8080/hbase/lib/myjar.jar'
CREATE FUNCTION my_reverse(varchar) returns varchar as 'com.mypackage.MyReverseFunction'
CREATE FUNCTION my_increment(integer, integer constant defaultvalue='10') returns integer as 'com.mypackage.MyIncrementFunction' using jar '/hbase/lib/myincrement.jar'
CREATE TEMPORARY FUNCTION my_reverse(varchar) returns varchar as 'com.mypackage.MyReverseFunction' using jar 'hdfs:/localhost:8080/hbase/lib/myjar.jar'
创建一个命令行方法my_reverse 使用 hdfs:/localhost:8080/hbase/lib/myjar.jar包里的com.mypackage.MyReverseFunction方法
详情参考 https://blog.csdn.net/gucapg/article/details/85999067
删除自定义函数方法
DROP FUNCTION IF EXISTS my_reverse
DROP FUNCTION my_reverse
删除数据
DELETE FROM test_table_person WHERE name = 'Joe';
删除表
DROP TABLE test_table_person;
创建表来进行表的映射
CREATE TABLE IF NOT EXISTS 表名(
列名 类型 主键,
列簇.列名,
列簇.列名
)
例如
CREATE TABLE "test_table_person" ( "ROW" varchar primary key, "0"."name" varchar, "0"."age" int, "0"."grade" varchar)
HBase中的RowKey映射Phoenix的主键,HBase中的Column映射Phoenix的列,且使用列簇名.列名进行映射。
相当于在SYSTEM.CATALOG表中录入相关的元数据,使Phoenix能够进行操作它
创建视图来进行表的映射
CREATE VIEW 视图名(
列名 类型 主键,
列簇.列名,
列簇.列名
)
例如
CREATE VIEW "test_table_person" ( "ROW" varchar primary key, "0"."name" varchar, "0"."age" int, "0"."grade" varchar)
Phoenix中的视图只能进行查询,不能进行添加、更新、删除操作。
创建表时对表中的数据使用哈希取模进行分区
通过在创建表时指定SALE_BUCKETS来实现将表中的数据预分割到多个Region中,有利于提高读取数据的性能。
其原理是将RowKey进行散列,把得到的余数的byte值插入到RowKey的第一个字节中,并通过预定义每个Region的Start Key和End Key,将数据分散存储到不同的Region中。
CREATE TABLE IF NOT EXISTS test_table_person (
grade CHAR(1) NOT NULL,
name VARCHAR NOT NULL,
age INT,
CONSTRAINT person PRIMARY KEY (age, name)
)SALT_BUCKETS=16;
这里通过SALE_BUCKETS设置哈希函数的除数为16(除留余数法)
创建表时对表中的数据使用具体值进行分区
在创建表时,可以精确的指定RowKey根据什么值来进行预分区,不同的值存储在独立的Region中,有利于提高读取数据的性能。
CREATE TABLE IF NOT EXISTS test_table_person (
grade CHAR(1) NOT NULL,
name VARCHAR NOT NULL,
age INT,
CONSTRAINT person PRIMARY KEY (age, name)
)SPLIT ON('A','B','C');
创建表时指定列族
在HBase中每个列族对应一个文件,如果要查询的列所属的列族下只有它自己,那么将极大的提高读取数据的性能。
CREATE TABLE IF NOT EXISTS test_table_person (
C1.grade CHAR(1) NOT NULL,
name VARCHAR NOT NULL,
age INT,
CONSTRAINT person PRIMARY KEY (age, name)
);
列族只能在非主键列中进行指定,这里指定grade存在C1的列族中。
创建表时对表进行压缩
在创建表时可以指定表的压缩方式,能极大的提高数据的读写效率。
CREATE TABLE IF NOT EXISTS us_population (
grade CHAR(1) NOT NULL,
name VARCHAR NOT NULL,
age INT,
CONSTRAINT person PRIMARY KEY (age, name)
)COMPRESSION='GZ';
可选的压缩方式包括GZip、Snappy、Lzo等。
创建使用自增序列
序列(Sequence)是Phoenix提供的允许产生单调递增数字的一个SQL特性,序列会自动生成顺序递增的序列号,以实现自动提供唯一的主键值。
使用CREATE SEQUENCE语句建立序列的语法如下:
CREATE SEQUENCE my_sequence; //创建默认序列,其增量为1
CREATE SEQUENCE my_sequence START WITH -1000
CREATE SEQUENCE my_sequence INCREMENT BY 10
CREATE SEQUENCE my_schema.my_sequence START 0 CACHE 10
CREATE SEQUENCE my_cycling_sequence MINVALUE 1 MAXVALUE 100 CYCLE; //创建一个最小值为1,最大值为10并且能复位的序列
SELECT CURRENT FOR my_sequence; //查询当前序列号
SELECT NEXT VALUE FOR my_sequence; //查询当前序列的下一个序列号 (NEXT VALUE FOR返回当前序列的下一个序列号,CURENT VALUE FOR返回当前序列号,注意:首次引用序列时,必须是NEXT VALUE FOR)
UPSERT VALUES INTO my_table(id, col1, col2) VALUES( NEXT VALUE FOR my_schema.my_sequence, 'value1', 'value2'); //使用UPSERT SELECT语句,并为主键生成一个唯一的序列值
SELECT CURRENT VALUE FOR my_sequence FROM my_tale; //通过CURRENT VALUE FOR查询某表中某序列为该表分配的最后一个序列号
DROP SEQUENCE my_sequence //删除序列
DROP SEQUENCE IF EXISTS my_schema.my_sequence //删除序列
创建普通索引
CREATE INDEX 索引名称 ON 表名(列名)
例如:
CREATE INDEX my_idx ON sales.opportunity(last_updated_date DESC)
CREATE INDEX IF NOT EXISTS my_comp_idx ON server_metrics ( gc_time DESC, created_date DESC ) DATA_BLOCK_ENCODING='NONE',VERSIONS=?,MAX_FILESIZE=2000000 split on (?, ?, ?)
CREATE INDEX my_idx ON sales.opportunity(UPPER(contact_name))
创建二级索引
在HBase中会自动为RowKey添加索引,因此在通过RowKey查询数据时效率会很高,但是如果要根据其他列来进行组合查询,那么查询的性能就很低下,此时可以使用Phoenix提供的二级索引,能够极大的提高查询数据的性能。
CREATE INDEX 索引名称 ON 表名(列名) INCLUDE(列名)
例如:
CREATE INDEX my_idx ON log.event(created_date DESC) INCLUDE (name, payload) SALT_BUCKETS=10
修改索引
ALTER INDEX my_idx ON sales.opportunity DISABLE
ALTER INDEX IF EXISTS my_idx ON server_metrics REBUILD
删除索引
DROP INDEX my_idx ON sales.opportunity
DROP INDEX IF EXISTS my_idx ON server_metrics
查看sql执行计划explain
EXPLAIN SELECT NAME, COUNT(*) FROM TEST GROUP BY NAME HAVING COUNT(*) > 2;
EXPLAIN SELECT entity_id FROM CORE.CUSTOM_ENTITY_DATA WHERE organization_id='00D300000000XHP' AND SUBSTR(entity_id,1,3) = '002' AND created_date < CURRENT_DATE()-1;
更新统计信息UPDATE STATISTICS
UPDATE STATISTICS my_table
UPDATE STATISTICS my_schema.my_table INDEX
UPDATE STATISTICS my_index
UPDATE STATISTICS my_table COLUMNS
UPDATE STATISTICS my_table SET phoenix.stats.guidepost.width=50000000
修改表格属性
ALTER TABLE my_schema.my_table ADD d.dept_id char(10) VERSIONS=10
ALTER TABLE my_table ADD dept_name char(50), parent_id char(15) null primary key
ALTER TABLE my_table DROP COLUMN d.dept_id, parent_id;
ALTER VIEW my_view DROP COLUMN new_col;
ALTER TABLE my_table SET IMMUTABLE_ROWS=true,DISABLE_WAL=true;
使用新的命名空间schema
如果使用了hbase中的自定义namespace,不仅仅使用default,那么在phoenix中与之对应的是schema的概念。
在SQL环境下,schema就是数据库对象的集合,所谓的数据库对象也就是常说的表,索引,视图,存储过程等。
可以认为schema和数据库相同,也就是说schema的名称和数据库的实例的名称相同,一个数据库有一个schema。
CREATE SCHEMA IF NOT EXISTS my_schema
CREATE SCHEMA my_schema
USE my_schema
USE DEFAULT
DROP SCHEMA IF EXISTS my_schema
DROP SCHEMA my_schema
更多语法