数据结构HashMap(Android SparseArray 和ArrayMap)
HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在。在HashMap中,key-value总是会当做一个整体来处理,系统会根据hash算法来来计算key-value的存储位置,我们总是可以通过key快速地存、取value。
HashMap
HashMap.java源码分析:
三个构造函数:
HashMap():默认初始容量capacity(16),默认加载因子factor(0.75)
HashMap(int initialCapacity):构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor):构造一个带指定初始容量和加载因子的空 HashMap。
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
//构建自定义初始容量的构造函数,默认加载因子0.75的HashMap
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//构造一个带指定初始容量和加载因子的空 HashMap
public HashMap(int initialCapacity, float loadFactor) {
...
...
}
HashMap内部是使用一个默认容量为16的数组来存储数据的,而数组中每一个元素却又是一个链表的头结点,所以,更准确的来说,HashMap内部存储结构是使用哈希表的拉链结构(数组+链表),如图:
这种存储数据的方法叫做拉链法
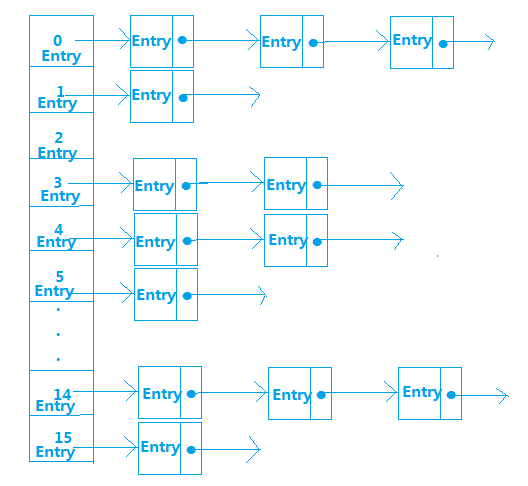
且每一个结点都是Entry类型,那么Entry是什么呢?我们来看看HashMap中Entry的属性:
final K key; //key值
V value; //value值
HashMapEntry next;//next下一个Entry
int hash;//key的hash值
快速存取
put(key,value);
public V put(K key, V value) {
if (table == EMPTY_TABLE) {//判断table空数组,
inflateTable(threshold);//创建数组容量为threshold大小的数组,threshold在HashMap构造函数中赋值initialCapacity(指定初始容量);
}
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许key为null的原因
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key); //计算key的hash值
int i = indexFor(hash, table.length); //计算key hash 值在 table 数组中的位置
//从i出开始迭代 e,找到 key 保存的位置
for (HashMapEntry e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;//旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue;//返回覆盖后的旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
} put过程分析:这篇文章http://www.cnblogs.com/chenssy/p/3521565.html总结的可以。
put过程结论:
当我们想一个HashMap中添加一对key-value时,系统首先会计算key的hash值,然后根据hash值确认在table中存储的位置。若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。如果两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的Entry的value覆盖原来节点的value。如果两个hash值相等但key值不等 ,则将该节点插入该链表的链头。
void addEntry(int hash, K key, V value, int bucketIndex) {
//获取bucketIndex处的Entry
Entry e = table[bucketIndex];
//将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry(hash, key, value, e);
//若HashMap中元素的个数超过极限了,则容量扩大两倍
if (size++ >= threshold)
resize(2 * table.length);
} 这个方法中有两点需要注意:
一是链的产生。这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将
指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。
二、扩容问题。
随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
读取实现:get(key)
相对于HashMap的存而言,取就显得比较简单了。通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可。
public V get(Object key) {
// 若为null,调用getForNullKey方法返回相对应的value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 取出 table 数组中指定索引处的值
for (Entry e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
//若搜索的key与查找的key相同,则返回相对应的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
} 在不断的向HashMap里put数据时,当达到一定的容量限制时(这个容量满足这样的一个关系时候将会扩容:HashMap中的数据量>容量*加载因子,而HashMap中默认的加载因子是0.75),HashMap的空间将会扩大;扩大之前容量的2倍 :resize(newCapacity)
int newCapacity = table.length;//赋值数组长度
newCapacity <<= 1;//x2
if (newCapacity > table.length)
resize(newCapacity);//调整HashMap大小容量为之前table的2倍这也就是重点所在,为什么在Android上需要使用SparseArray和ArrayMap代替HashMap,主要原因就是Hashmap随着数据不断增多,达到最大值时,需要扩容,而且扩容的大小是之前的2倍.
SparseArray
SparseArray.java 源码
SparseArray比HashMap更省内存,在某些条件下性能更好,主要是因为它避免了对key的自动装箱(int转为Integer类型),它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间,我们从源码中可以看到key和value分别是用数组表示:
private int[] mKeys;//int 类型key数组
private Object[] mValues;//value数组构造函数:
SparseArray():默认容量10;
SparseArray(int initialCapacity):指定特定容量的SparseArray
public SparseArray() {
this(10);
}
public SparseArray(int initialCapacity) {
if (initialCapacity == 0) {//判断传入容量值
mKeys = EmptyArray.INT;
mValues = EmptyArray.OBJECT;
} else {//不为0初始化key value数组
mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);
mKeys = new int[mValues.length];
}
mSize = 0;//mSize赋值0
}从上面创建的key数组:SparseArray只能存储key为int类型的数据,同时,SparseArray在存储和读取数据时候,使用的是二分查找法;
/**
* 二分查找,中间位置的值与需要查找的值循环比对
* 小于:范围从mid+1 ~ h1
* 大于:范围从0~mid-1
* 等于:找到值返回位置mid
*/
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final int midVal = array[mid];
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid; // value found
}
}
return ~lo; // value not present
}SparseArray存取数据
SparseArray的put方法:
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);//二分查找数组mKeys中key存放位置,返回值是否大于等于0来判断查找成功
if (i >= 0) {//找到直接替换对应值
mValues[i] = value;
} else {//没有找到
i = ~i;//i按位取反得到非负数
if (i < mSize && mValues[i] == DELETED) {//对应值是否已删除,是则替换对应键值
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {//当mGarbage == true 并且mSize 大于等于key数组的长度
gc(); //调用gc回收
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
//最后将新键值插入数组,调用 GrowingArrayUtils的insert方法:
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
下面进去看看 GrowingArrayUtils的insert方法有什么扩容的;
public static T[] insert(T[] array, int currentSize, int index, T element) {
assert currentSize <= array.length;
if (currentSize + 1 <= array.length) {//小于数组长度
System.arraycopy(array, index, array, index + 1, currentSize - index);
array[index] = element;
return array;
}
//大于数组长度需要进行扩容
T[] newArray = (T[]) Array.newInstance(array.getClass().getComponentType(),
growSize(currentSize));//扩容规则里面就一句三目运算:currentSize <= 4 ? 8 : currentSize * 2;(扩容2倍)
System.arraycopy(array, 0, newArray, 0, index);
newArray[index] = element;
System.arraycopy(array, index, newArray, index + 1, array.length - index);
return newArray;
}
SparseArray的get(key)方法:
public E get(int key) {
return get(key, null);//调用get(key,null)方法
}
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);//二分查找key
if (i < 0 || mValues[i] == DELETED) {//没有找到,或者已经删除返回null
return valueIfKeyNotFound;
} else {//找到直接返回i位置的value值
return (E) mValues[i];
}
}SparseArray在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。
而在获取数据的时候,也是使用二分查找法判断元素的位置,所以,在获取数据的时候非常快,比HashMap快的多,因为HashMap获取数据是通过遍历Entry[]数组来得到对应的元素。
SparseArray应用场景:
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显,将降低至少50%。
满足下面两个条件我们可以使用SparseArray代替HashMap:
- 数据量不大,最好在千级以内
- key必须为int类型,这中情况下的HashMap可以用SparseArray代替:
ArrayMap
ArrayMap是一个
public class ArrayMap<K, V> extends SimpleArrayMap<K, V> implements Map<K, V> {}构造函数由父类实现:
public ArrayMap() {
super();
}
public ArrayMap(int capacity) {
super(capacity);
}
public ArrayMap(SimpleArrayMap map) {
super(map);
}
HashMap内部有一个HashMapEntry[]对象,每一个键值对都存储在这个对象里,当使用put方法添加键值对时,就会new一个HashMapEntry对象,而ArrayMap的存储中没有Entry这个东西,他是由两个数组来维护的,mHashes数组中保存的是每一项的HashCode值,mArray中就是键值对,每两个元素代表一个键值对,前面保存key,后面的保存value。
int[] mHashes;//key的hashcode值
Object[] mArray;//key value数组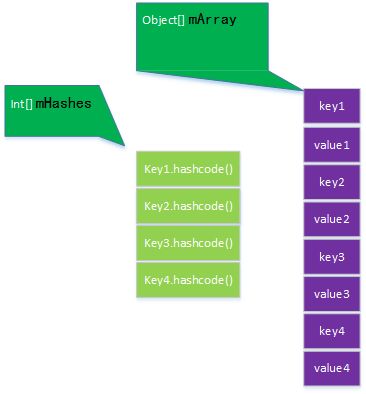
SimpleArrayMap():创建一个空的ArrayMap,默认容量为0,它会跟随添加的item增加容量。
SimpleArrayMap(int capacity):指定特定容量ArrayMap;
SimpleArrayMap(SimpleArrayMap map):指定特定的map;
public SimpleArrayMap() {
mHashes = ContainerHelpers.EMPTY_INTS;
mArray = ContainerHelpers.EMPTY_OBJECTS;
mSize = 0;
}
...ArrayMap 存取
ArrayMap 的put(K key, V value):key 不为null
/**
* Add a new value to the array map.
* @param key The key under which to store the value. Must not be null. If
* this key already exists in the array, its value will be replaced.
* @param value The value to store for the given key.
* @return Returns the old value that was stored for the given key, or null if there
* was no such key.
*/
public V put(K key, V value) {
final int hash;
int index;
//key 不能为null
if (key == null) { //key == null,hash为0
hash = 0;
index = indexOfNull();
} else {//获取key的hash值
hash = key.hashCode();
index = indexOf(key, hash);//获取位置
}
//返回index位置的old值
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];//old 赋值 value
mArray[index] = value;
return old;
}
//否则按位取反
index = ~index;
//扩容 System.arrayCopy数据
if (mSize >= mHashes.length) {
final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1))
: (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);//申请数组
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
freeArrays(ohashes, oarray, mSize);//重新收缩数组,释放空间
}
if (index < mSize) {
if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (mSize-index)
+ " to " + (index+1));
System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
//最后 mHashs数组存储key的hash值
mHashes[index] = hash;
mArray[index<<1] = key;//mArray数组相邻位置存储key 和value值
mArray[(index<<1)+1] = value;
mSize++;
return null;
}从最后可以看出:ArrayMap的存储中没有Entry这个东西,他是由两个数组来维护的,mHashes数组中保存的是每一项的HashCode值,mArray中就是键值对,每两个元素代表一个键值对,前面保存key,后面的保存value。
ArrayMap 的get(Object key):从Array数组获得value
/**
* Retrieve a value from the array.
* @param key The key of the value to retrieve.
* @return Returns the value associated with the given key,
* or null if there is no such key.
*/
public V get(Object key) {
final int index = indexOfKey(key);//获得key在Array的存储位置
return index >= 0 ? (V)mArray[(index<<1)+1] : null;//如果index>=0 取(index+1)上的value值,否则返回null(从上面put知道array存储是key(index) value(index+1)存储的)
}ArrayMap 和 HashMap区别:
- 1.存储方式不同
HashMap内部有一个HashMapEntry[]对象,每一个键值对都存储在这个对象里,当使用put方法添加键值对时,就会new一个HashMapEntry对象
ArrayMap的存储中没有Entry这个东西,他是由两个数组来维护的
mHashes数组中保存的是每一项的HashCode值,
mArray中就是键值对,每两个元素代表一个键值对,前面保存key,后面的保存value。- 2.添加数据时扩容时的处理不一样
HashMap使用New的方式申请空间,并返回一个新的对象,开销会比较大
ArrayMap用的是System.arrayCopy数据,所以效率相对要高。3、ArrayMap提供了数组收缩的功能,只要判断过判断容量尺寸,例如clear,put,remove等方法,只要通过判断size大小触发到freeArrays或者allocArrays方法,会重新收缩数组,释放空间。
4、ArrayMap相比传统的HashMap速度要慢,因为查找方法是二分法,并且当你删除或者添加数据时,会对空间重新调整,在使用大量数据时,效率低于50%。可以说ArrayMap是牺牲了时间换区空间。但在写手机app时,适时的使用ArrayMap,会给内存使用带来可观的提升。ArrayMap内部还是按照正序排列的,这时因为ArrayMap在检索数据的时候使用的是二分查找,所以每次插入新数据的时候ArrayMap都需要重新排序,逆序是最差情况;
HashMap ArrayMap SparseArray性能测试对比(转载 )
直接看:http://www.jianshu.com/p/7b9a1b386265测试对比
1.插入性能时间对比
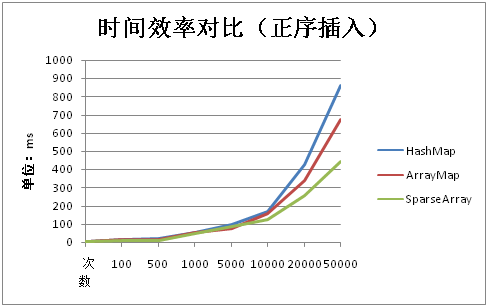
数据量小的时候,差异并不大(当然了,数据量小,时间基准小,确实差异不大),当数据量大于5000左右,SparseArray,最快,HashMap最慢,乍一看,好像SparseArray是最快的,但是要注意,这是顺序插入的。也就是SparseArray和Arraymap最理想的情况。
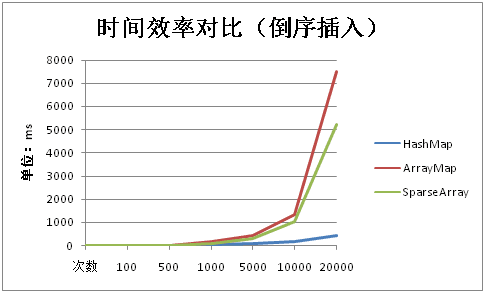
倒序插入:数据量大的时候HashMap远超Arraymap和SparseArray,也前面分析一致。
当然了,数据量小的时候,例如1000以下,这点时间差异也是可以忽略的。

SparseArray在内存占用方面的确要优于HashMap和ArrayMap不少,通过数据观察,大致节省30%左右,而ArrayMap的表现正如前面说的,优化作用有限,几乎和HashMap相同。
2.查找性能对比


如何选择使用
1.在数据量小的时候一般认为1000以下,当你的key为int的时候,使用SparseArray确实是一个很不错的选择,内存大概能节省30%,相比用HashMap,因为它key值不需要装箱,所以时间性能平均来看也优于HashMap,建议使用!
2.ArrayMap相对于SparseArray,特点就是key值类型不受限,任何情况下都可以取代HashMap,但是通过研究和测试发现,ArrayMap的内存节省并不明显,也就在10%左右,但是时间性能确是最差的,当然了,1000以内的如果key不是int 可以选择ArrayMap。
参考:
Android内存优化(使用SparseArray和ArrayMap代替HashMap)
Java集合—HashMap源码剖析
http://www.cnblogs.com/chenssy/p/3521565.html
深入Java集合学习系列:HashMap的实现原理
SparseArray源码解析
HashMap,ArrayMap,SparseArray源码分析及性能对比
Android源码分析–ArrayMap优化