postgresql系列之窗口函数
本文是《sql基础教程》《postgresql实战》的读书笔记;具体可以参考这两本书相关章节。
一、 窗口函数
1.1 基本概念
窗口函数可以进行排序、生成序列号等一般的聚合函数无法实现的高级操作;聚合函数将结果集进行计算并且通常返回一行。窗口函数也是基于结果集的运算。与聚合函数不同的是,窗口函数并不会将结果集进行分组合并输出一行;而是将计算的结果合并到基于结果集运算的列上。
思考:为什么说窗口函数是基于结果集的预算 ?
解读: 关于这个问题,则必须要谈谈 查询语句的逻辑处理顺序
SQL 逻辑处理顺序
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- 表达式
- DISTINCT
- ORDER BY
- OFFSET-FETCH
注:在over()子句中指定的order by子句不应该与显示排序混淆,并且并且它不会改变结果的关系本质。
根据窗口函数的执行顺序的位置便可以知道:窗口函数是基于结果集进行运算的。它将计算出的结果合并到输出的结果集上。
1.2 语法相关
<窗口函数>
OVER ([PARTITION BY <列清单>]
ORDER BY <排序用列清单>)
over:窗口函数关键字partition by:对结果集进行分组order by:设定结果集的分组数据排序
**可作为窗口函数的函数分类: **
聚合函数:① 聚合函数(SUM、AVG、COUNT、MAX、MIN)
内置函数:② RANK、DENSE_RANK、ROW_NUMBER 等专用窗口函
1.3 入门案例
聚合函数后接 over属性的窗口函数表示在一个查询结果集上应用聚合函数。
描述: 查询每名学生学习成绩并且显示课程的平均分。
-- 创建成绩表
create table score(
id serial PRIMARY key,
subject character(32),
stu_name character(32),
grade NUMERIC(3,0)
);
-- 插入数据
INSERT INTO SCORE(subject,stu_name,grade) values
('语文','小王',80),
('语文','小张',70),
('语文','小李',80),
('英语','小王',90),
('英语','小张',70),
('英语','小李',50),
('数学','小王',100),
('数学','小张',70),
('数学','小李',65)
使用 group by 和 窗口函数

但是:我在写sql查询的时候,不小心在窗口函数增加了排序字段。导致结果不是我想要的。如下图所示:

思考:在窗口函数中使用order by 导致最后数据并非所希望的;
问题一:那什么时候应该用order by;
问题二:聚合函数类型的窗口函数中使用order by是什么意思呢。
尝试寻找规律
(一) 去除窗口函数中的 order by 和 最外层的 order by
 顺序可能不一致,数据行能够对应上,最终数据也是正确的。
顺序可能不一致,数据行能够对应上,最终数据也是正确的。
(二) 去除最外层的 order by 。 顺序不一致,记录相等,但最后结果不正确。
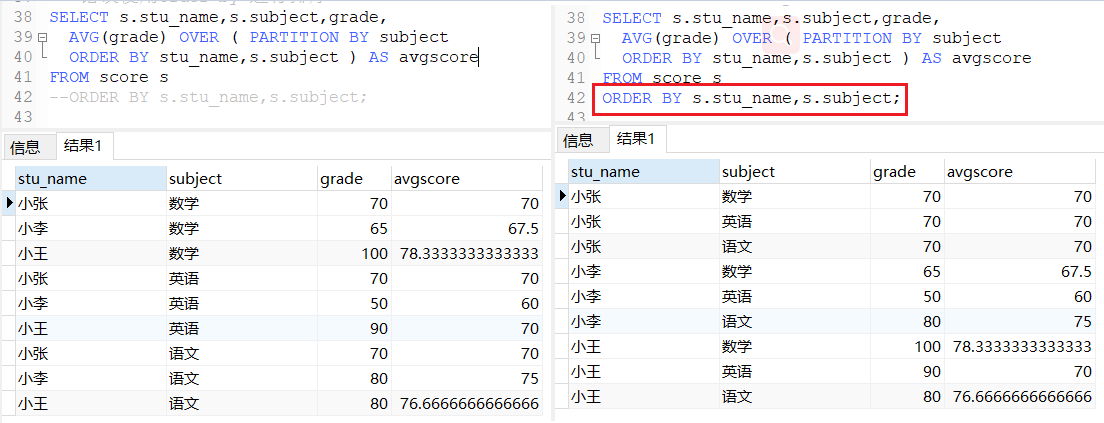
(三) 单独使用 subject进行排序,结果是正确的。

通过这种方式去探索可能不是一个好的主意;另辟蹊径 (参考《sql基础教程》)
1.4 作为窗口函数使用的聚合函数
先准备数据;
CREATE TABLE Product
(product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER ,
purchase_price INTEGER ,
regist_date DATE ,
PRIMARY KEY (product_id));
INSERT INTO Product VALUES ('0001', 'T恤' ,'衣服', 1000, 500, '2009-09-20');
INSERT INTO Product VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO Product VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO Product VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO Product VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO Product VALUES ('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO Product VALUES ('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO Product VALUES ('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');
先用 SUM 函数作为窗口函数使用 的例子
SELECT product_id, product_name, sale_price,
SUM (sale_price) OVER (ORDER BY product_id) AS current_sum
FROM Product;
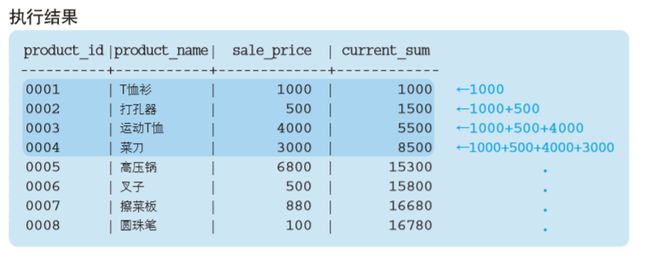
但是我们得到的并不仅仅是合计值,而是按照 ORDER BY 子句指定 的 product_id的升序进行排列,计算出商品编号“小于自己”的商品 的销售单价的合计值。因此,计算该合计值的逻辑就像金字塔堆积那样,一行一行逐渐添加计算对象。在按照时间序列的顺序,计算各个时间的销 售额总额等的时候,通常都会使用这种称为累计的统计方法
使用其他聚合函数时的操作逻辑也和本例相同
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id) AS current_avg
FROM Product;

从结果中可以看到,current_avg 的计算方法确实是计算平 均值的方法,但作为统计对象的却只是“排在自己之上”的记录。像这样 以“自身记录(当前记录)”作为基准进行统计,就是将聚合函数当作窗口函数使用时的最大特征。
两个order by
OVER 子句中的 ORDER BY只是用来决定 窗口函数按照什么样的顺序进行计算的,对结果的排列顺序并没有影响; 而需要在select的最后指定排序,不然整个结果集不确定顺序。主意:这两个order by的作用和意思完全不同。
通过上面的学习,先前不是自己想要的记录的语句被解释清楚了。

1.5 理解:partition by 与 order by
PARTITION BY 在横向上对表进行分组,而 ORDER BY 决定了纵向排序的规则

窗口函数兼具之前我们学过的GROUP BY 子句的分组功能以及 ORDER BY子句的排序功能。但是,PARTITION BY子句并不具备 GROUP BY子句的汇总功
通过 PARTITION BY 分组后的记录集合称为窗口。此处的窗口并 非“窗户”的意思,而是代表范围。这也是“窗口函数”名称的由来
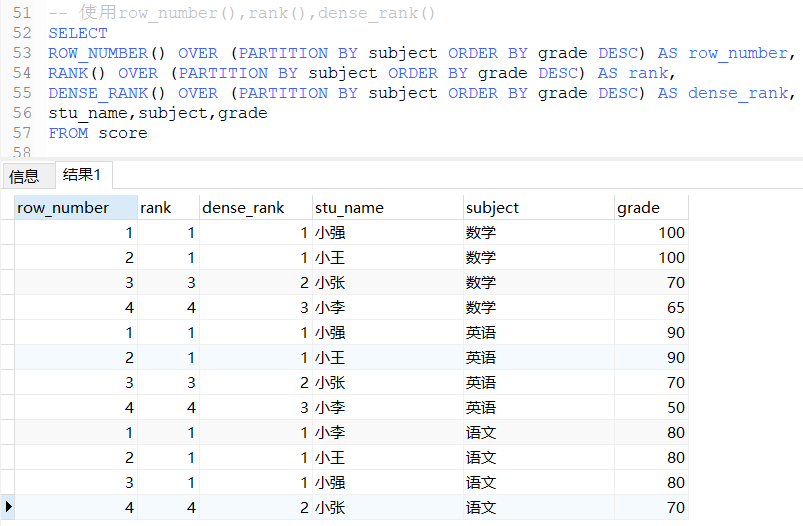
1.6 内置函数之 RANK、DENSE_RANK、ROW_NUMBER
RANK函数 计算排序时,如果存在相同位次的记录,则会跳过之后的位次。(行号产生间隙)
有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
DENSE_RANK函数 同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
ROW_NUMBER函数 赋予唯一的连续位次。(可用于做分页的行号)
有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……
案例: 在插入几条数据,验证三个函数
INSERT INTO SCORE(subject,stu_name,grade) values
('语文','小强',80),
('英语','小强',90),
('数学','小强',100)
扩展ROW_NUMBER
可以对ROW_NUMBER 做扩展,因为其标注的行号是从0开始。可以不指定partition by 参数。这样ROW_NUMBER窗口函数显示所有记录的行号。

另外:如果order by 能够确定每一行都唯一(如,按照主键排序);则可以用行号做分页查询。
1.7 内置函数 firt_value() 、last_value()、nth_value()
first_value()用来取结果集每一个分组的第一行数据的字段值。last_value()用来取结果集每一个分组的最后一行数据的字段值。nth_value()用来取结果集每一个分组的指定行数的字段值。(如果不存在返回null)
-- 学科分组,分数排序降序,取最高值
SELECT first_value(grade) OVER(PARTITION BY subject ORDER BY grade DESC),*
FROM score;
SELECT nth_value(grade,1) OVER(PARTITION BY subject ORDER BY grade DESC),*
FROM score;
--
-- last_value 添加 order by 不起作用?(pg9.6)
SELECT last_value(grade) OVER(PARTITION BY subject ORDER BY grade DESC),*
FROM score;
思考: last_value 语句不起作用?

补充 窗口函数别名的使用
如果SQL中需要多次使用窗口函数,可以使用窗口函数别名,语法如下:
SELECT ...FROM ... WINDOW window_name AS (window_definition)
例如:

1.8 lag()
获取行偏移offset那行某个字段的数据
语法格式
lag(value anyelement) [,offset integer [, default anyelement ]])
其中offset 默认值为1 default默认值为null

1.9 计算移动平均
窗口函数就是将表以窗口为单位进行分割,并在其中进行排序的函数。
其实其中还包含在窗口中指定更加详细的汇总范围的备选功能,该备选功 能中的汇总范围称为框架
SELECT product_id, product_name,sale_price,
AVG (sale_price) OVER (
ORDER BY
product_id ROWS 2 PRECEDING
) AS moving_avg
FROM
Product

指定框架(汇总范围)
我们将上述结果与之前的结果进行比较,可以发现商品编号为“0004” 的“菜刀”以下的记录和窗口函数的计算结果并不相同。这是因为我们指 定了框架,将汇总对象限定为了“最靠近的 3行”。
这里我们使用了 ROWS(“行”)和 PRECEDING(“之前”)两个关键 字,将框架指定为“截止到之前 ~ 行”,因此“ROWS 2 PRECEDING" 这样的统计方法称为移动平均
使用关键字FOLLOWING(“之后”)替换 PRECEDING,就可以指 定“截止到之后 ~ 行”作为框架了

将当前记录的前后行作为汇总对象
如果希望将当前记录的前后行作为汇总对象时,同时使用 PRECEDING(“之前”)和 FOLLOWING(“之后”)关 键字来实现
SELECT
product_id,
product_name,
sale_price,
AVG (sale_price) OVER (
ORDER BY product_id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS moving_avg
FROM
Product;

参考
- 《sql基础教程》
- 《postgresql实战》
- 《sql server 2012 T-sql基础教程》