小白理解k-svd算法
小白理解k-svd字典学习
一、字典学习
字典学习也可简单称之为稀疏编码,字典学习偏向于学习字典D。从矩阵分解角度,看字典学习过程:给定样本数据集Y,Y的每一列表示一个样本;字典学习的目标是把Y矩阵分解成D、X矩阵:
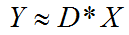
同时满足约束条件:X尽可能稀疏,同时D的每一列是一个归一化向量。
D称之为字典,D的每一列称之为原子;X称之为编码矢量、特征、系数矩阵;字典学习可以有三种目标函数形式
(1)第一种形式:
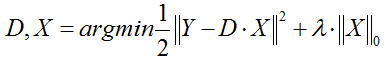
这种形式因为L0难以求解,所以很多时候用L1正则项替代近似。
(2)第二种形式:
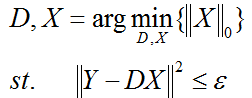
ε是重构误差所允许的最大值。
(3)第三种形式:
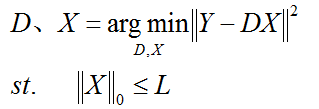
L是一个常数,稀疏度约束参数,上面三种形式相互等价。
因为目标函数中存在两个未知变量D、X,K-svd是字典学习的一种经典算法,其求解方法跟lasso差不多,固定其中一个,然后更新另外一个变量,交替迭代更新。
如果D的列数少于Y的行数,就相当于欠完备字典,类似于PCA降维;如果D的列数大于Y的行数,称之为超完备字典;如果刚好等于,那么就称之为完备字典。假设现在有了一个N*T的过完备字典 D(比如前面所述图像傅里叶变换的所有频率的波),一个要表示的对象y(要还原的图像),求一套系数x,使得y=Dx,这里y是一个已知的长为N的列向量,x是一个未知的长为T的列向量,解方程。
这是一个T个未知数,N个方程的方程组,T>N,所以是有无穷多解的,线性代数中这样的方程很熟悉了。
上面我就随便举了个N=5, T=8的例子,用来随便感受下。
 ⎥
⎥
这里可以引出一个名词,ill-posed problem(不适定问题),即有多个满足条件的解,无法判断哪个解更加合适,这是更“落地”的应用场景,inverse problem(逆问题),比如图像去噪,从噪声图中提取干净图。于是需要做一个约束。
增加限制条件,要求x尽可能稀疏,怎么“稀疏”呢?就是x的0尽可能多,即norm(x, 0)(零范数:非0元素个数)尽可能小。这样就有唯一解了吗?也还不是,如何能“约束”出各位合适的解,如何解,正是稀疏表示所研究的重点问题。比如后来有证明D满足一定条件情况下x满足norm(x,1)即可还原原始数据等,这有不少大神开启这个领域的故事这里就不讲了。
二、k-svd字典学习算法概述
给定训练数据Y,Y的每一列表示一个样本,我们的目标是求解字典D的每一列(原子)。关于它为什么叫做k-svd,当然是其中综合了k-means 和SVD 的思想。k-means 常用于聚类分类 ,具体的步骤如下:
(1)在样本集中随机挑选k个样本作为质心,即随机初始化k个原子,此步骤可视为字典的初始化。
(2)通过计算样本与质心之间的距离,样本类别化为最近的质心所对应的类别,就是,离谁近,则化为谁的类。此步骤可视为稀疏矩阵的初始化,只不过对应系数矩阵的每一列只有一项不为0,其余均为0,不为0的一项的索引便是我们样本对应的类别。
(3)通过划分好的类别来重新计算每类样本的质心。此步便是原子矩阵的优化。
(4)根据新计算得来的质心重新分类(原子矩阵,即字典的每个列向量则可看做是一个质心)。此步便是稀疏矩阵的优化。
(5)直至两步质心(原子矩阵)相差少于规定的阈值,便停止优化。
k-svd 字典学习的步骤如下:
1、随机初始化字典D(类似k-means一样初始化)
从样本集Y中随机挑选k个样本,作为D的原子;并且初始化编码矩阵X为0矩阵。
2、固定字典,求取每个样本的稀疏编码
编码过程采用如下公式:
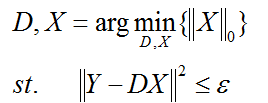
ε是重构误差所允许的最大值。
假设我们的单个样本是向量y,为了简单起见我们就假设原子只有这4个,也就是字典D=[α1、α2、α3、α4],且D是已经知道的;我们的目标是计算y的编码x,使得x尽量的稀疏。
(1)首先从α1、α2、α3、α4中找出与向量y最近的那个向量,也就是分别计算点乘:
α1*y、α2*y、α3*y、α4*y
然后求取最大值对应的原子α。
(2)假设α2*y最大,那么我们就用α2,作为我们的第一个原子,然后我们的初次编码向量就为:
x1=(0,b,0,0)
b是一个未知参数。
(3)求解系数b:
y-b*α2=0
方程只有一个未知参数b,是一个高度超静定方程,求解最小二乘问题。
(4)然后我们用x1与α2相乘重构出数据,然后计算残差向量:
y’=y-b*α2
如果残差向量y’满足重构误差阈值范围ε,那么就结束,否则就进入下一步;
(5)计算剩余的字典α1、α3、α4与残差向量y’的最近的向量,也就是计算
α1*y’、α3*y’、α4*y’
然后求取最大值对应的向量α,假设α3*y’为最大值,那么就令新的编码向量为:
x2=(0,b,c,0)
b、c是未知参数。
(6)求解系数b、c,于是我们可以列出方程:
y-b*α2-c*α3=0
方程中有两个未知参数b、c,我们可以进行求解最小二乘方程,求得b、c。
(7)更新残差向量y’:
y’=y-b*α2-c*α3
如果y’的模长满足阈值范围,那么就结束,否则就继续循环,就这样一直循环下去。
3、逐列更新字典、并更新对应的非零编码
通过上面那一步,我们已经知道样本的编码。接着我们的目标是更新字典、同时还要更新编码。K-svd采用逐列更新的方法更新字典,就是当更新第k列原子的时候,其它的原子固定不变。假设我们当前要更新第k个原子αk,令编码矩阵X对应的第k行为xk,则目标函数为:
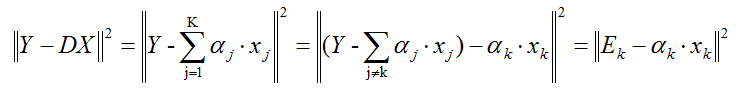
上面的方程,我们需要注意的是xk不是把X一整行都拿出来更新(因为xk中有的是零、有的是非零元素,如果全部抽取出来,那么后面计算的时候xk就不再保持以前的稀疏性了),所以我们只能抽取出非零的元素形成新的非零向量,然后Ek只保留xk对应的非零元素项。
K-SVD和MOD最大的不同在于,每次只更新字典的一个原子(即D的一列),而不是每次用一个x更新整个D。
回忆下前面的y=Dx,但是学一个字典,当然不能只用一个数据,现在来升级版:
Y = DX
哈?小写变大写?意思是一组y和其对应的一组x,那么Y和X指的矩阵。
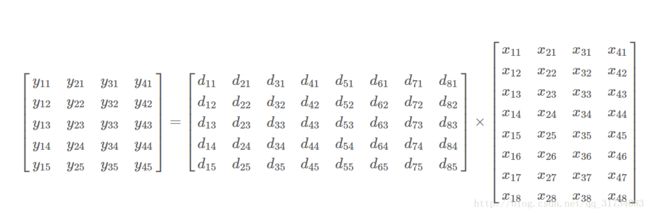
现在要更新字典D的第k个原子,也就是第k列,它能影响到的是Y的第k行,同样对应D的第k列的系数,也是X的第k行。
目标函数的转化:
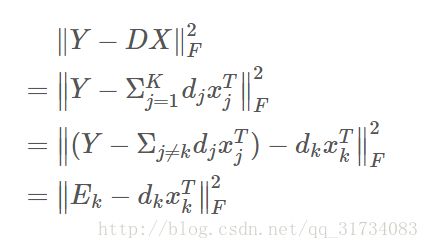
Ek 是去掉原子 dk 的 D 中的误差,于是目标函数转化为 D 的其他列固定,要更新的 dk 使全局误差( ∥Y−DX∥ )最小化。 即可得到字典的第k个原子。求解这里的 Dk, xkT ,就用到对 E 的SVD分解了。
但是直接分解 E 得到的 xkT 并不稀疏。
更新字典和稀疏系数是迭代进行的,在“本次”迭代中,找到“上次”迭代中哪些Y用到了字典D的原子k,也就是X的第k行哪些元素不为0,x1k, x2k, x3k, x4k 里,假设 x1k, x3k 不为0,那么对应的Y的1,3列就是用到了D的原子k的信号(Y的每列是一个信号)。现在把它们拆出来:
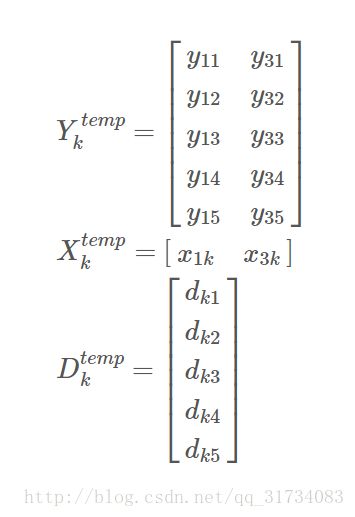
这样得到只保留非零位置的X、D计算目标函数后得到的只保留对应位置的 Ektemp ,对这个 Ektemp 再做SVD分解,Ektemp = UΣVT, U 的第一列即为新的 $\widetilde{d}_{k}$, V 的第一列与 Σ(1, 1) 的乘积为新的 $\widetilde{x}^{T}_{k}$ 。
逐列更新得到新字典 $\widetilde{D}$
然后算法就在1和2之间一直迭代更新,直到收敛。
参考文献
http://blog.csgrandeur.com/blogs/20170323-ksvd-and-denoising
http://blog.csdn.net/hjimce/article/details/50810129
https://blog.csdn.net/weixin_41469272/article/details/81944385?utm_source=copy
字典学习的K - SVD 算法分析
K-SVD: An Algorithm for Designing Overcomplete
Dictionaries for Sparse Representation Dictionaries for Sparse Representation