吊打Java面试官-Java锁升级详解
用户态与内核态.
JDK早期,synchronized 叫做重量级锁,因为申请锁资源必须通过kernel,系统调用
; he11o. asm
;write(int fd,const void *buffer, size_ t nbytes)
section data
msg db "Hello", 0xA
1en equ $ -msg
section .text
g1obal _start
_start:
mov edx,1en
mov ecx, msg
mov ebx, 1 ; 文件描述符1 std_ _out
mov eax, 4 ;write函数 系统调用号4
int 0x80
mov ebx, 0
mov eax,1 ;exit函数系统调用号
int 0x80
CAS
compare and swap
compare and exchange
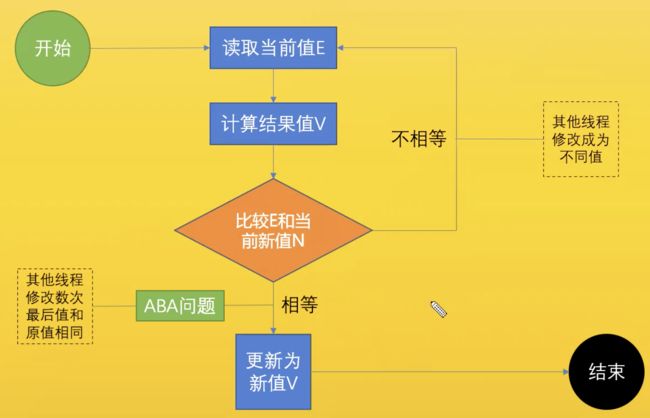
ABA 问题简单理解就是你不知道你的女朋友到底经历过几次恋爱,可以通过加版本标识解决.
cas汇编实现
lock cmpchgl就能保证原子性
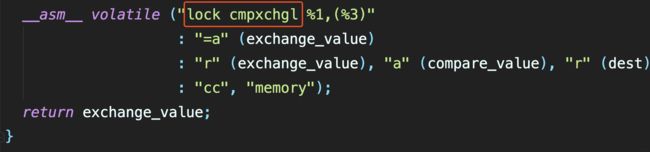
其实 cas,volatile,synchronize 底层实现都是 lock 指令.
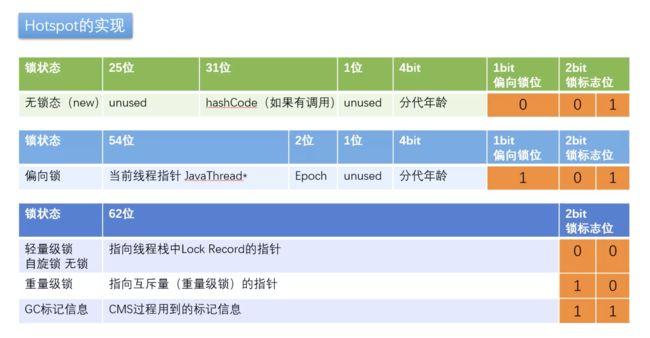
对象的内存布局
锁升级
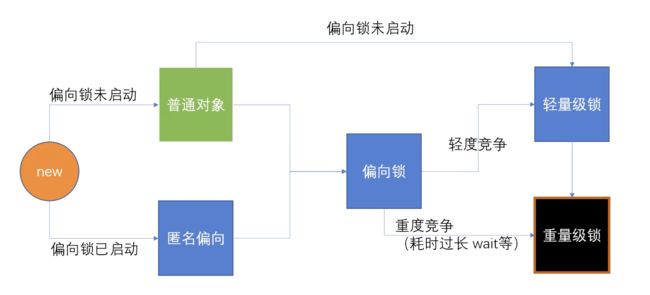
- 匿名偏向是偏向锁启动了,但还没有指定线程.
偏向锁在JDK6是默认启用的,但在应用程序启动大概 4秒后才激活
- 使用 -XX:BiasedLockingStartupDelay=0 参数关闭延迟,立即启动偏向锁
如果确定应用程序中所有锁通常情况下处于竞争状态,可以通过 XX:-UseBiasedLocking=false 参数关闭偏向锁
-X print help on non- standard options
java -XX:+PrintFlagsFinal -version
- 可以看到有七百多个参数

- java -XX:+PrintFlagsFinal —version (查看jvm 的可以配置的参数)
- java -XX:+PrintFlagsFinal —version grep BiasedLocking(查看jvm 的可以配置的参数)

- UseBiasedLocking 是否启动偏向级锁
我们知道synchronized是重量级锁,效率不怎么样,不过在JDK6中对synchronize的实现进行了各种优化,使得它显得不是那么重了,那么JVM采用了那些优化手段呢
锁优化
如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
锁主要存在四种状态:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态
他们会随着竞争的激烈而逐渐升级。
注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率
自旋锁(轻量级锁)
突然有了线程来竞争了,就不是偏向锁了,开始升级为自旋锁
竞争过程就是看谁能把自己的 id 信息放进 markword 里的 id 即可,通过 CAS 方式
和偏向锁一样不需要经过操作系统资源,只需要 jvm 即可,不需要 os 资源
线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。
同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这一段很短的时间频繁地阻塞和唤醒线程是非常不值得的。所以引入自旋锁。
所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁的线程是否会很快释放锁。
怎么等待呢?执行一段无意义的循环即可(自旋)。
自旋等待不能替代阻塞,先不说对处理器数量的要求,虽然它可以避免线程切换带来的开销,但是它占用了处理器的时间。
如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作,典型的占着茅坑不拉屎,这样反而会带来性能上的浪费。
所以说,自旋等待的时间(自旋的次数)必须要有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起。
自旋锁在JDK 1.4.2中引入,默认关闭,但是可以使用-XX:+UseSpinning开启,
在JDK1.6中默认开启。同时自旋的默认次数为10次,可以通过参数-XX:PreBlockSpin来调整;
等待的线程超过 CPU 的一半数量升级为重量级锁
如果通过参数-XX:preBlockSpin来调整自旋锁的自旋次数,会带来诸多不便。假如我将参数调整为10,但是系统很多线程都是等你刚刚退出的时候就释放了锁(假如你多自旋一两次就可以获取锁),你是不是很尴尬。于是JDK1.6引入自适应的自旋锁,让虚拟机会变得越来越聪明。
自适应自旋锁
JDK 1.6 引入了更加聪明的自旋锁,即自适应自旋锁。
所谓自适应就意味着自旋的次数不再是固定的,它由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
它怎么做呢?
线程如果自旋成功了,那么下次自旋的次数会更多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
锁消除
为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这时JVM会对这些同步锁进行锁消除。
锁消除的依据是逃逸分析的数据支持。
如果不存在竞争,为什么还需要加锁呢?所以锁消除可以节省毫无意义的请求锁的时间。
变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是对于我们程序员来说这还不清楚么?但有时候程序并不是我们所想的那样,我们虽然没有显示使用锁,但是我们在使用一些JDK的内置API时,如StringBuffer、Vector、HashTable等,这时候会存在隐形的加锁操作。比如StringBuffer的append()方法,Vector的add()方法
public void vectorTest(){
Vector vector = new Vector();
for(int i = 0 ; i < 10 ; i++){
vector.add(i + "");
}
System.out.println(vector);
}
在运行这段代码时,JVM可以明显检测到变量vector没有逃逸出方法vectorTest()之外,所以JVM可以大胆地将vector内部的加锁操作消除。
锁粗化
我们知道在使用同步锁的时候,需要让同步块的作用范围尽可能小,即仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁
在大多数的情况下,上述观点是正确的,本人也一直坚持着这个观点。但是如果一系列的连续加锁解锁操作,可能会导致不必要的性能损耗,所以引入锁粗化的概念:
就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁
如上面实例:vector每次add的时候都需要加锁操作,JVM检测到对同一个对象(vector)连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加锁解锁操作会移到for循环外
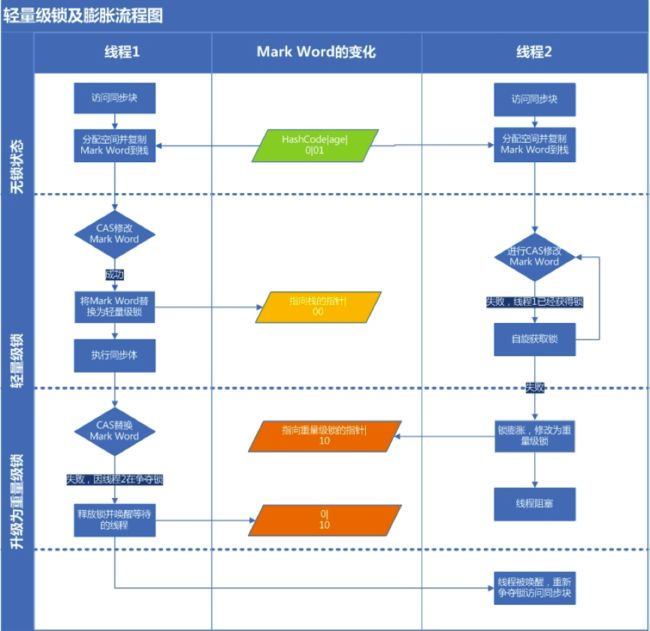
轻量级锁
主要目的是在没有多线程竞争的前提下,减少传统的重量级锁使用OS的互斥量(mutex)产生的性能消耗。
当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,其步骤如下:
###获取锁
- 判断当前对象是否处于无锁状态(hashcode、0、01)
- 是
JVM将首先在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝(官方把这份拷贝加了一个Displaced前缀,即Displaced Mark Word) - 否
执行3
- 是
- JVM利用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指正
- 成功(表示竞争到锁)
将锁标志位变成00(表示此对象处于轻量级锁状态),执行同步操作 - 失败
执行3
- 成功(表示竞争到锁)
- 判断当前对象的Mark Word是否指向当前线程的栈帧
- 是(表示当前线程已经持有当前对象的锁)
直接执行同步代码块 - 否(只能说明该锁对象已经被其他线程抢占)
轻量级锁需要膨胀为重量级锁,锁标志位变成10,后面等待的线程将会进入阻塞状态
###释放锁
轻量级锁的释放也是通过CAS操作来进行的,主要步骤如下:
- 是(表示当前线程已经持有当前对象的锁)
- 取出获取轻量级锁时保存在Displaced Mark Word中的数据
- 用CAS操作将取出的数据替换到当前对象的Mark Word中
- 成功
说明释放锁成功 - 失败
执行3
- 成功
- CAS操作替换失败,说明有其他线程尝试获取该锁,则需要在释放锁的同时需要唤醒被挂起的线程
对于轻量级锁,其性能提升的依据是
“对于绝大部分的锁,在整个生命周期内都是不会存在竞争的”
如果打破这个依据则除了互斥的开销外,还有额外的CAS操作,因此在有多线程竞争的情况下,轻量级锁比重量级锁更慢
下图是轻量级锁的获取和释放过程
偏向锁
只需要把自己的线程 id 记录到对象对的 markword 的 id 里即可.
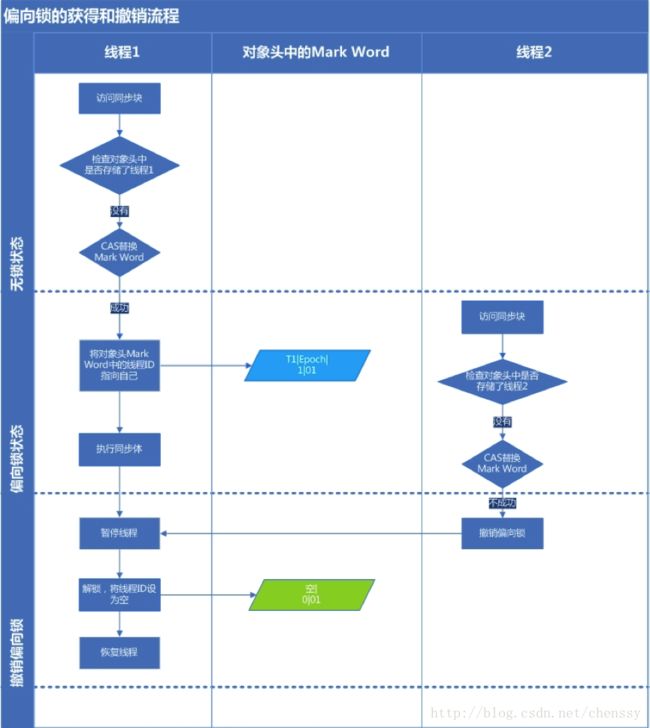
目的:在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径。
上面提到了轻量级锁的加锁解锁操作是需要依赖多次CAS原子指令的。
那么偏向锁是如何来减少不必要的CAS操作呢?
我们可以查看Mark work的结构就明白了。
只需要检查是否为偏向锁、锁标识为以及ThreadID即可,处理流程如下:
获取锁
- 检测Mark Word是否为可偏向状态,即是否为偏向锁1,锁标识位为01
- 若为可偏向状态,则测试线程ID是否为当前线程ID
- 是
执行5 - 否
执行3
- 是
- 如果线程ID不为当前线程ID,则通过CAS操作竞争锁,竞争
- 成功
将Mark Word的线程ID替换为当前线程ID, - 失败
执行4
- 成功
- CAS竞争锁失败,证明当前存在多线程竞争情况,当到达全局安全点,获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码块
- 执行同步代码块
释放锁
偏向锁的释放采用了一种只有竞争才会释放锁的机制,线程是不会主动去释放偏向锁,需要等待其他线程来竞争。
偏向锁的撤销需要等待全局安全点(这个时间点是上没有正在执行的代码)。其步骤如下:
- 暂停拥有偏向锁的线程,判断锁对象石是否还处于被锁定状态
- 撤销偏向锁,恢复到无锁状态(01)或者轻量级锁的状态
下图是偏向锁的获取和释放流程
重量级锁
重量级锁通过对象内部的监视器(monitor)实现,其中monitor的本质是依赖于底层操作系统的Mutex Lock实现,操作系统实现线程之间的切换需要从用户态到内核态的切换,切换成本非常高
class ObjectMonitor {
public:
enum {
OM_OK, // no error
OM_SYSTEM_ERROR, // operating system error
OM_ILLEGAL_MONITOR_STATE, // IllegalMonitorStateException
OM_INTERRUPTED, // Thread.interrupt()
OM_TIMED_OUT // Object.wait() timed out
};
private:
friend class ObjectSynchronizer;
friend class ObjectWaiter;
friend class VMStructs;
JVMCI_ONLY(friend class JVMCIVMStructs;)
volatile markOop _header; // displaced object header word - mark
void* volatile _object; // backward object pointer - strong root
public:
ObjectMonitor* FreeNext; // Free list linkage
private:
DEFINE_PAD_MINUS_SIZE(0, DEFAULT_CACHE_LINE_SIZE,
sizeof(volatile markOop) + sizeof(void * volatile) +
sizeof(ObjectMonitor *));
protected: // protected for JvmtiRawMonitor
void * volatile _owner; // pointer to owning thread OR BasicLock
volatile jlong _previous_owner_tid; // thread id of the previous owner of the monitor
volatile intptr_t _recursions; // recursion count, 0 for first entry
ObjectWaiter * volatile _EntryList; // Threads blocked on entry or reentry.
// The list is actually composed of WaitNodes,
// acting as proxies for Threads.
private:
ObjectWaiter * volatile _cxq; // LL of recently-arrived threads blocked on entry.
Thread * volatile _succ; // Heir presumptive thread - used for futile wakeup throttling
Thread * volatile _Responsible;
volatile int _Spinner; // for exit->spinner handoff optimization
volatile int _SpinDuration;
volatile jint _contentions; // Number of active contentions in enter(). It is used by is_busy()
// along with other fields to determine if an ObjectMonitor can be
// deflated. See ObjectSynchronizer::deflate_monitor().
protected:
ObjectWaiter * volatile _WaitSet; // LL of threads wait()ing on the monitor
volatile jint _waiters; // number of waiting threads
private:
volatile int _WaitSetLock; // protects Wait Queue - simple spinlock
public:
static void Initialize();
// Only perform a PerfData operation if the PerfData object has been
// allocated and if the PerfDataManager has not freed the PerfData
// objects which can happen at normal VM shutdown.
//
#define OM_PERFDATA_OP(f, op_str) \
do { \
if (ObjectMonitor::_sync_ ## f != NULL && \
PerfDataManager::has_PerfData()) { \
ObjectMonitor::_sync_ ## f->op_str; \
} \
} while (0)
static PerfCounter * _sync_ContendedLockAttempts;
static PerfCounter * _sync_FutileWakeups;
static PerfCounter * _sync_Parks;
static PerfCounter * _sync_Notifications;
static PerfCounter * _sync_Inflations;
static PerfCounter * _sync_Deflations;
static PerfLongVariable * _sync_MonExtant;
static int Knob_SpinLimit;
void* operator new (size_t size) throw();
void* operator new[] (size_t size) throw();
void operator delete(void* p);
void operator delete[] (void *p);
// TODO-FIXME: the "offset" routines should return a type of off_t instead of int ...
// ByteSize would also be an appropriate type.
static int header_offset_in_bytes() { return offset_of(ObjectMonitor, _header); }
static int object_offset_in_bytes() { return offset_of(ObjectMonitor, _object); }
static int owner_offset_in_bytes() { return offset_of(ObjectMonitor, _owner); }
static int recursions_offset_in_bytes() { return offset_of(ObjectMonitor, _recursions); }
static int cxq_offset_in_bytes() { return offset_of(ObjectMonitor, _cxq); }
static int succ_offset_in_bytes() { return offset_of(ObjectMonitor, _succ); }
static int EntryList_offset_in_bytes() { return offset_of(ObjectMonitor, _EntryList); }
// ObjectMonitor references can be ORed with markOopDesc::monitor_value
// as part of the ObjectMonitor tagging mechanism. When we combine an
// ObjectMonitor reference with an offset, we need to remove the tag
// value in order to generate the proper address.
//
// We can either adjust the ObjectMonitor reference and then add the
// offset or we can adjust the offset that is added to the ObjectMonitor
// reference. The latter avoids an AGI (Address Generation Interlock)
// stall so the helper macro adjusts the offset value that is returned
// to the ObjectMonitor reference manipulation code:
//
#define OM_OFFSET_NO_MONITOR_VALUE_TAG(f) \
((ObjectMonitor::f ## _offset_in_bytes()) - markOopDesc::monitor_value)
markOop header() const;
volatile markOop* header_addr();
void set_header(markOop hdr);
intptr_t is_busy() const {
// TODO-FIXME: assert _owner == null implies _recursions = 0
return _contentions|_waiters|intptr_t(_owner)|intptr_t(_cxq)|intptr_t(_EntryList);
}
const char* is_busy_to_string(stringStream* ss);
intptr_t is_entered(Thread* current) const;
void* owner() const;
void set_owner(void* owner);
jint waiters() const;
jint contentions() const;
intptr_t recursions() const { return _recursions; }
// JVM/TI GetObjectMonitorUsage() needs this:
ObjectWaiter* first_waiter() { return _WaitSet; }
ObjectWaiter* next_waiter(ObjectWaiter* o) { return o->_next; }
Thread* thread_of_waiter(ObjectWaiter* o) { return o->_thread; }
protected:
// We don't typically expect or want the ctors or dtors to run.
// normal ObjectMonitors are type-stable and immortal.
ObjectMonitor() { ::memset((void *)this, 0, sizeof(*this)); }
~ObjectMonitor() {
// TODO: Add asserts ...
// _cxq == 0 _succ == NULL _owner == NULL _waiters == 0
// _contentions == 0 _EntryList == NULL etc
}
private:
void Recycle() {
// TODO: add stronger asserts ...
// _cxq == 0 _succ == NULL _owner == NULL _waiters == 0
// _contentions == 0 EntryList == NULL
// _recursions == 0 _WaitSet == NULL
DEBUG_ONLY(stringStream ss;)
assert((is_busy() | _recursions) == 0, "freeing in-use monitor: %s, "
"recursions=" INTPTR_FORMAT, is_busy_to_string(&ss), _recursions);
_succ = NULL;
_EntryList = NULL;
_cxq = NULL;
_WaitSet = NULL;
_recursions = 0;
}
public:
void* object() const;
void* object_addr();
void set_object(void* obj);
bool check(TRAPS); // true if the thread owns the monitor.
void check_slow(TRAPS);
void clear();
void enter(TRAPS);
void exit(bool not_suspended, TRAPS);
void wait(jlong millis, bool interruptable, TRAPS);
void notify(TRAPS);
void notifyAll(TRAPS);
void print() const;
void print_on(outputStream* st) const;
// Use the following at your own risk
intptr_t complete_exit(TRAPS);
void reenter(intptr_t recursions, TRAPS);
private:
void AddWaiter(ObjectWaiter * waiter);
void INotify(Thread * Self);
ObjectWaiter * DequeueWaiter();
void DequeueSpecificWaiter(ObjectWaiter * waiter);
void EnterI(TRAPS);
void ReenterI(Thread * Self, ObjectWaiter * SelfNode);
void UnlinkAfterAcquire(Thread * Self, ObjectWaiter * SelfNode);
int TryLock(Thread * Self);
int NotRunnable(Thread * Self, Thread * Owner);
int TrySpin(Thread * Self);
void ExitEpilog(Thread * Self, ObjectWaiter * Wakee);
bool ExitSuspendEquivalent(JavaThread * Self);
};