卷积块注意模块
目录
Abstract:
Introduction
Related Work(Attention mechanism)
Convolutional Block Attention Module
通道注意力模块
空间注意力模块
模块安排
实验
消融研究
Channel attention
Spatial attention
Channel and Spatial attention
使用Grad-CAM进行网络可视化
Abstract:
- 给定一个中间的特征图,模块沿着通道和空间两个维度推断注意力映射
- CBAM是轻量级的和基本的模块,它可以整合进任意的CNN结构与模型一起进行端到端的训练;并且训练所需要的花费较少
- 代码是公开的
Introduction
- 为了提高CNNs的性能,近年来的研究主要考察了网络的三个重要因素:深度、宽度和基于分组的方式。从Xception和ResNeXt来看,基数不仅节省了参数的总数,而且比深度和宽度这两个因素具有更强的表示能力。
- 注意力不仅能告诉你该把注意力放在哪里,还能提高兴趣的代表性。
- 该论文的目标是通过使用注意力机制来增加代表性:专注于重要的特性,抑制不必要的特性
- 由于卷积运算通过混合跨信道和空间信息来提取信息特征,我们采用我们的模块来强调信道和空间轴上有意义的特征。为了实现这一点,我们依次应用通道和空间注意力模块。这样,每个分支都可以在通道和空间轴上分别学习“什么”和“哪里”。

- 由于我们精心设计了轻量级的模块,所以在大多数情况下,参数和计算的开销可以忽略不计。
Related Work(Attention mechanism)
众所周知,注意力在人类感知中起着重要的作用。人类视觉系统的一个重要特性是一个人不会试图一次处理整个场景。
最近,有几次尝试将注意力处理与提高CNNs在大规模分类任务中的性能相结合:
Wang et al.提出“Residual Attention Network”。使用编码器和解码器风格的注意力模块。通过改进特征映射,该网络不仅性能良好,而且对噪声输入具有鲁棒性。
Hu et al.介绍了一个利用通道之间的相关性的紧凑模块,在Squeeze-and-Excitation模块中使用全局平均池化特征来计算通道级的注意力。整个方法是与本论文相近的,本文作者建议使用最大池化特征,并且认为他们没有注意到空间注意力,这在“看哪里”扮演者重要的角色。
Convolutional Block Attention Module
给出一个中间特征图 ![]() ,
,
CBAM依次推导出一维通道注意图![]() ;2D空间注意力图
;2D空间注意力图 ![]()
 总体的流程为 :
总体的流程为 :
![]()
其中  定义为"element-wise"乘法。广播(复制)相应的注意力值:通道注意值沿空间维度广播。
定义为"element-wise"乘法。广播(复制)相应的注意力值:通道注意值沿空间维度广播。![]() 为最终的输出
为最终的输出
通道注意力模块
压缩了输入特征图的空间维度,聚集空间信息(最大池化和平均池化):周建议使用平均池化来有效地学习目标对象的范围,Hu在他们的注意力模块中采用平均池来计算空间统计。作者认为与平均池化相比,最大池化可以推断出更好的通道注意力。
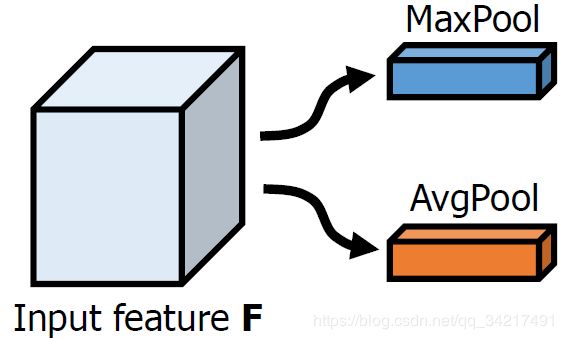
利用最大池化和平均池化聚集空间信息,得到两个不同的空间内容描述符 ![]() 和
和 ![]()
将这两个描述符转发到共享网络,以生成我们的通道注意图![]() 。共享 网络由一层隐藏层的多层感知机组成以减少参数开销。(隐藏激活大小设置为
。共享 网络由一层隐藏层的多层感知机组成以减少参数开销。(隐藏激活大小设置为![]() ,r是减速比)
,r是减速比)
将共享网络应用到每个描述符之后,我们使用“element-wise”求和来合并输出特征向量
![]()
![]()
 为sigmoid函数;
为sigmoid函数;![]() ;
;![]() ;
;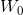 后面接的激活函数是ReLU
后面接的激活函数是ReLU
空间注意力模块
我们首先沿着通道轴应用平均池和最大池操作,并将它们连接起来以生成有效的特征描述符
在连接的特征描述符上,我们运用卷积层去产生一个“spatial attention map”,![]()
![]()
![]()
为sigmoid函数;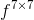 代表卷积核大小为7*7的卷积运算
代表卷积核大小为7*7的卷积运算
模块安排
空间注意力模块和通道注意力模块可以是并行排列或者顺序排列;作者在文中给出实验,认为顺序排列比并行排列来的更好,并且通道注意力在空间注意力之前会更好。
实验
消融研究
The ImageNet-1K classification dataset [1] consists of 1.2 million images for training and 50,000 for validation with 1,000 object classes. We adopt the same data augmentation scheme with [5, 36] for training and apply a single-crop evaluation with the size of 224*224 at test time. The learning rate starts from 0.1 and drops every 30 epochs. We train the networks for 90 epochs. Following [5, 36, 37], we report classification errors on the validation set.
三个步骤展开模块的研究:channel attention、spatial attention、conbine both channel attention and spatial attention
Channel attention
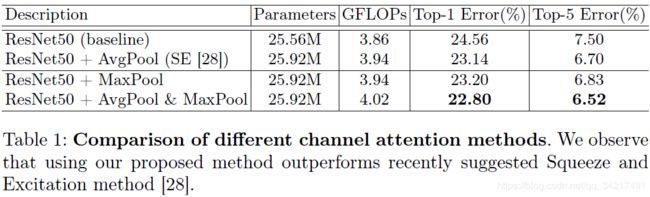
验证了同时使用平均池和最大池功能可以实现更好的注意力推断
Spatial attention
我们首先计算一个2D描述符,该描述符在所有空间位置的每个像素处编码通道信息
然后对二维描述符应用一个卷积层,得到原始的注意图。最终的注意图由sigmoid函数标准化
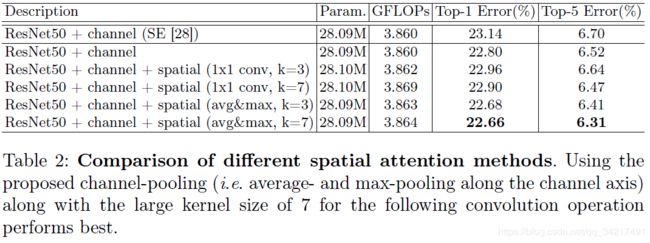
比较两种生成二维描述符的方法:跨通道轴使用平均池和最大池的通道池、使用1X1卷积减少通道维度,为1。
研究下一个卷积层的核大小的影响,kernel sizes of 3 and 7
在实验中,将spatial attention module放置在了channel attention module之后
Channel and Spatial attention
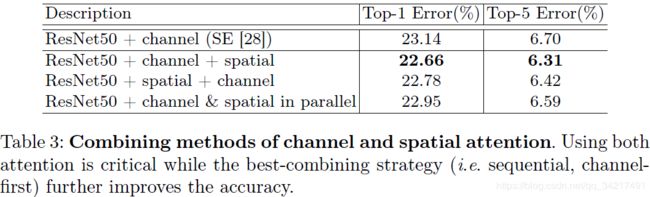
在这个实验中,我们比较了三种不同的方式来安排通道和空间注意子模块:顺序channel-spatial,顺序Spatial-channel,以及两个注意模块的并行使用。
使用Grad-CAM进行网络可视化
We compare the visualization results of CBAM-integrated network (ResNet50 + CBAM) with baseline
(ResNet50) and SE-integrated network (ResNet50 + SE). The grad-CAM visualization is calculated for the last convolutional outputs. The ground-truth label is shown on the top of each input image and P denotes the softmax score of each network for the ground-truth class.