一文带你了解关系数据库设计要领
文章目录
- 摘要
- 实体-关系模型(E-R)
- 关系表设计
- Boyce-Codd范式
- 第三范式
- 存储引擎的选择
- 何如选择?
- 字符集选择
- 如何选择?
- 数据类型的选择
- 选择原则
- 固定长度和可变长度
- char 与 varchar
- text 和 blob
- 浮点数和定点数
- 整数
- 索引设计
- 设计原则
- 示例
- 参考
摘要
本文讨论关系数据库设计相关的一些内容,涉及关系模型,表结构设计等内容,以学生选修课程讲述设计过程,在尽量讲清楚设计要领的前提下,简化设计内容。本文基于MySQL数据库为基础,适合有一定关系型数据库基础的人阅读。
实体-关系模型(E-R)
首先搞清楚什么是E-R数据模型?它有什么用?
E-R模型在将现实世界中事实的含义和相互关联映射到概念模式方面非常有用,因此,许多数据库设计工具都利用了E-R模型的概念。E-R模型所采用的三个主要概念是:实体集、关系集和属性。
- 实体:实体是世界中可以区别于其他对象的“事件”或者“物体”,例如,学校里的每个学生、学生选修的每门课程等都是一个实体。
- 属性:属性是实体集中每个成员具有的描述性性质。例如,学生的姓名,学号等。
- 实体集:实体集就是就有相同类型及属性的实体集合,比如,学校里的所有学生,学生选修的所有课程等。
- 关系:关系是多个实体间的相互关联。例如,小明选修语文课程。
- 关系集:关系集是同类关系的集合。例如,所用学生选修课程的集合。
既然知道了E-R数据模型的作用,下面就让我们来画出学生选修课程的E-R图吧。
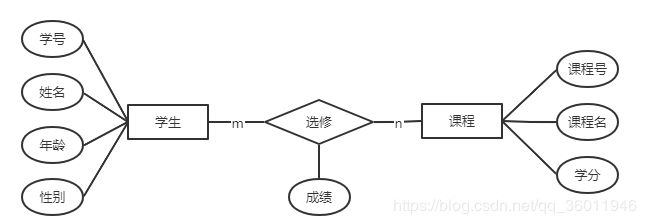
其中,(学号,姓名,年龄,性别)为学生的属性,(成绩)为选修关系的属性,(课程号,课程名,学分)为课程的属性。学生和课程之间的关系是多对多,即一个学生可以选择多门课程,一门课程可以被多个学生选修。
关系表设计
从上面的E-R图,我们一眼就能看出他们之间的联系,那该如何设计关系模式呢?
我们要知道,关系数据库设计的目的是为了生成一组关系模式,使我们能够既不必存储不必要的冗余信息,又能方便地获取信息。为了是我们方便的达到这个目的,范式设计应运而生。
Boyce-Codd范式
我们所知道的令人满意的范式之一是Boyce-Codd范式(BCNF)。如果对F+中所有形如 α→β 的函数依赖,其中 α⊆R 且 β⊆R,下面的定义至少有一个成立:
- α→β 是平凡函数依赖(即 β ⊂ α)。(一般来说,平凡函数依赖并没有讨论意义,讨论的都是非平凡函数依赖,即 β ∉⊂ α 的情况)
- α 是模式R的超码。
考虑如下关系模式及其相应的函数依赖:
-
学生 = (学号,姓名,年龄,性别)
学号 → 姓名 年龄 性别
-
课程 = (课程号,课程名,学分)
课程号 → 课程名 学分
-
选修 = (学号,课程号,成绩)
学号 课程号 → 成绩
以上模式均属于BCNF。就拿第一组关系模式来说,学生上仅有的非平凡函数依赖,箭头左侧是学号,学号是该模式的一个候选码(候选码属于超码的子集),没有破坏BCNF的定义。
其实并不是每个BCNF都能保持函数依赖的,例如:
Banker-schema = (branch-name,customer-name,banker-name)
它表示的是一个客户在某一分支机构有一个银行账户负责人。它要求满足的函数依赖集F为
-
banker-name → branch-name
-
branch-name customer-name → banker-name
显然,Banker-schema不属于BCNF,因为 banker-name 不是超码。
我们可以将它分解得到如下的BCNF:
Banker-branch-schema = (banker-name,branch-name)
Customer-banker-schema = (customer-name,banker-name)
分解后的模式只保持了banker-name → branch-name,而branch-name customer-name → banker-name的依赖没有保持。
第三范式
当我们不能同时满足以下三个设计目标:
- BCNF。
- 无损连接。
- 保持函数依赖。
我们可以放弃BCNF而接受相对较弱的第三范式(3NF)。因为3NF总能找到无损连接并保持依赖的分解。
具有函数依赖即F的关系模式R属于3NF,只要F+中所有形如 α→β 的函数依赖,其中 α⊆R 且 β⊆R,下面的定义至少有一个成立:
- α→β 是平凡函数依赖(即 β ⊂ α)。
- α 是模式R的超码。
- β - α 中的每个属性 A 都包含在R的候选码中。
回到Banker-schema的例子中,我们已经看到了没能将该关系模式转化成BCNF而又保持依赖和无损连接的分解,但改模式属于3NF。在Banker-schema中,候选码是{branch-name,customer-name},所以Banker-schema上不包含候选码的就只有banker-name。而形如 α → banker-name 的非平凡函数依赖都是以{branch-name,customer-name}作为 α 的一部分。由于{branch-name,customer-name}是候选码,所以符合3NF的定义。
每个BCNF都属于3NF,因为BCNF的约束比3NF更严格。
存储引擎的选择
关系模式一但确定,基本的数据库表结构就确定了,接下来就是表结构的详细设计了,这里先从存储引擎开始,MySQL提供的各种存储引擎都是根据不同的用例设计的。下表概述了MySQL提供的一些存储引擎。
| 特征 | MyISAM | Memory | InnoDB | Archive | NDB |
|---|---|---|---|---|---|
| B-tree索引 | √ | √ | √ | ||
| 哈希索引 | √ | √ | |||
| 全文索引 | √ | √ | |||
| 外键 | √ | √ | |||
| 锁定粒度 | 表 | 表 | 行 | 行 | 行 |
| MVCC | √ | ||||
| 储存限制 | 256TB | 内存 | 64TB | 384EB | |
| 数据压缩 | √ | √ | √ | ||
| 事务 | √ | √ | |||
| 备份/时间点恢复 | √ | √ | √ | √ | √ |
最常用的两种存储引擎:MyISAM和InnoDB。
- MyISAM:MySQL 5.5.5以前,MyISAM作为MySQL的默认存储引擎。
- InnoDB:MySQL 5.5.5以后,InnoDB作为MySQL的默认存储引擎。
何如选择?
选择标准: 根据应用特点选择合适的存储引擎,对于复杂的应用系统可以根据实际情况选择多种存储引擎进行组合。但是要知道组合使用的缺点:
InnoDB和非InnoDB存储引擎的组合对比,仅使用InnoDB存储引擎可以简化备份和恢复操作。MySQL Enterprise Backup对使用InnoDB存储引擎的所有表进行热备份。对于使用MyISAM或其他非InnoDB存储引擎的表,它会执行“热”备份,数据库会继续运行,但这些表在备份时不能修改。
下面是常用存储引擎的适用环境:
- InnoDB:事务型业务场景首选。
- MyISAM:非事务型的大多数业务场景。
- Memory:数据保存到内存中,能提供极速的访问速度。(个人觉得可以使用Redis等NoSQL数据库代替)
字符集选择
存储引擎之后就是确定字符集,字符集的选择十分重要,不管是MySQL还是Oracle,如果在数据库创建阶段没有正确选择字符集,那么在后期需要更换字符集的时候将要付出高昂的代价。
如何选择?
建议在能够完全满足应用当下和未来几年发展的前提下,尽量使用小的字符集。应为更小的字符集意味着能够节省空间、减少网络传输字节数,同时由于存储空间小间接的提升了系统的性能。
不同的数据库有不同的字符集应用级别,分别为服务器级别、库级别、表级别、字段级别,通常推荐使用库级别或者表级别。因为库级别或者表级别在保有灵活性的同时,兼顾数据间字符集的统一,这可以给开发省去很多处理字符集的麻烦。
数据类型的选择
选择原则
前提:使用合适的存储引擎。
选择原则:为了获得最佳的存储,您应该在所有情况下尝试使用最精确的类型。
固定长度和可变长度
char 与 varchar
下面这个例子说明二者的区别:
| 数值 | char(4) | 存储空间 | varchar(4) | 存储空间 |
|---|---|---|---|---|
'' |
' ' |
4字节 | '' |
1字节 |
'ab' |
'ab ' |
4字节 | 'ab' |
3字节 |
'abcd' |
'abcd' |
4字节 | 'abcd' |
5字节 |
'abcdefgh' |
'abcd' |
4字节 | 'abcd' |
5字节 |
请注意上表中最后一行的值只适用不使用严格模式时;如果 MySQL 运行在严格模式,超过列 长度的值不保存,并且会出现错误。
从 CHAR(4)和 VARCHAR(4)列检索的值并不总是相同,因为检索时从 CHAR 列删除了尾部的空 格。通过下面的例子说明该差别:
mysql> CREATE TABLE vc (v VARCHAR(4), c CHAR(4));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO vc VALUES ('ab ', 'ab ');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT CONCAT('(', v, ')'), CONCAT('(', c, ')') FROM vc;
+---------------------+---------------------+
| CONCAT('(', v, ')') | CONCAT('(', c, ')') |
+---------------------+---------------------+
| (ab ) | (ab) |
+---------------------+---------------------+
1 row in set (0.06 sec)
对于InnoDB数据表,内部的行格式没有区分固定长度和可变长度列,所有数据化行都使用指向数据列值的头指针,因此在本质上,使用固定长度的CHAR列不一定比使用可变长度的VARCHAR列要好。因为,主要的性能因数是数据行使用的存储总量。对于占用空间来说,CHAR总是大于等于VARCHAR,所以,使用VARCHAR来最小化行数据的存储总量,进而减少磁盘I/O频率。
text 和 blob
在使用text或者blob类型的字段是需要注意一下几点,以便获得更好的性能:
- 执行大量的删除和更新操作后,会留下很”空洞“,需要定期optimize table进行碎片整理;
- 避免查询大型的text和blob。查询大型的text和blob会使一页能装下的数据量减少,增加磁盘I/O压力。
- 把text和blob分离到单独的表中。这会把原来表中的数据列转变为更短的固定长度的数据行格式,这个十分有用。
浮点数和定点数
在MySQL中float、double是浮点数,decimal是定点数。
浮点数优势:在长度一定的情况下,浮点数能表示更大的数据范围。
浮点数缺点:精度问题。
友情提醒:在有关金钱交易方面浮点数慎用!!!
整数
MySQL支持SQL标准整数类型INTEGER(或INT)和SMALLINT。作为标准的扩展,MySQL还支持整数类型TINYINT、MEDIUMINT和BIGINT。下表显示了每个整数类型所需的存储空间和范围。
| Type | 存储(字节) | 有符号最小值 | Minimum Value Unsigned | 有符号最大值 | 无符号最大值 |
|---|---|---|---|---|---|
TINYINT |
1 | -128 |
0 |
127 |
255 |
SMALLINT |
2 | -32768 |
0 |
32767 |
65535 |
MEDIUMINT |
3 | -8388608 |
0 |
8388607 |
16777215 |
INT |
4 | -2147483648 |
0 |
2147483647 |
4294967295 |
BIGINT |
8 | -263 |
0 |
263-1 |
264-1 |
索引设计
设计原则
- 搜索的索引列,不一定是所要选择的列。最适合索引的列是出现在 WHERE 子 句中的列,或连接子句中指定的列,而不是出现在 SELECT 关键字后的选择列表中的列。
- 使用惟一索引。对于惟一值的列,索引的效果最好,而具有多个 重复值的列,其索引效果最差。
- 使用短索引。如果对字符串列进行索引,应该指定一个前缀长度 。例如,如果有一个 CHAR(200) 列,如果在前 10 个或 20 个字符内,多数值是惟一的, 那么就不要对整个列进行索引。
- 利用最左前缀。每个额外的索 引都要占用额外的磁盘空间,并降低写操作的性能。
- 不要过度索引。
- 考虑在列上进行的比较类型。如果是在列上做函数运算,对其进行索引将毫无意义。
示例
针对上面提到的学生选课E-R图,给出设计结果和说明:
表1-1 学生信息表(Student)
| 列名 | 数据类型 | 长度 | 是否可空 | 备注 | 键 |
|---|---|---|---|---|---|
| sno | int | 10 | N | 学号 | PK |
| sname | varchar | 40 | N | 姓名 | index |
| ssex | enum | —— | Y | 性别 | |
| sbirthday | date | —— | Y | 出生日期 |
表1-2 课程信息表(Course)
| 列名 | 数据类型 | 长度 | 是否可空 | 备注 | 键 |
|---|---|---|---|---|---|
| cno | int | 4 | N | 课程号 | PK |
| cname | varchar | 40 | N | 课程名称 | index |
| credit | int | 2 | Y | 学分 |
表1-3 选课成绩表(SC)
| 列名 | 数据类型 | 长度 | 是否可空 | 备注 | 键 |
|---|---|---|---|---|---|
| sno | int | 10 | N | 学号 | PK |
| cno | int | 4 | N | 课程号 | PK |
| Grade | double | 3 | Y | 成绩 |
- Student中
姓名的长度是40,这里把外国人也考虑进来了; - Student中
性别定义成枚举,主要是枚举意义简明; - Student中没有存
年龄,而存储的出生日期,是因为年龄并不是一成不变的,并且能够通过出生日期正确计算。 - SC中
成绩使用的是double而不采用decimal,主要是因为成绩并不需要那么高的精确度。 - SC中(sno,cno)作为联合主键而不是独立主键,由于现阶段markdown无法合拼行,所以无法编辑。
参考
[1] (美)Abraham Silberschatz等.数据库系统概念.北京:机械工业出版社,2012
[2] MySQL 5.7 Reference Manual
[3] [eimhe.com]网易技术部的MySQL中文资料.