YOLO3 darknet训练自己的数据
YOLO3 darknet训练自己的数据
文章目录
- 准备好标注工具labelImg
- 准备好训练数据集和验证数据集
- 开始标标标数据
- xml转txt
- 生成train.txt 和 val.txt
- 准备Sneaker.names文件
- 准备Sneaker.data文件
- 准备yolov3-Sneaker.cfg_train文件
- 下载预训练权重
- 开始训练
- 测试
- 总结
本文的环境是在darknet下用yolov3来训练自己的数据集,如果darknet环境未配置,请参考我之前的配置文章噢~
在win10下配置yolov3(超详细的der~)
准备好标注工具labelImg
这里我已经准备了一个标注工具,可以通过点击此链接下载使用
下载完之后解压后就可以使用了。
准备好训练数据集和验证数据集
训练集和测试集/验证集的比例一般是 3:1 或者 4:1
因为本人比较喜欢鞋,所以之前已经标注了500张yeezy的图片,已标注好的和未标注的都整理好放到百度盘了,供大家使用(大家要是够顶,就尝试体验下标500张图的快感吧!!!)。
已标注好的:点击链接下载
未标注过的:点击链接下载
把图片分到两个文件夹中:
一个是train_images(一般放在…\darknet-master\build\darknet\x64\data 下面)
一个是val_images(一般放在…\darknet-master\build\darknet\x64\data 下面)
可以看到我的图片都是井然有序的,我一开始是自己标序号,发现手动标序号不妥,因此写了个脚本处理下文件名,大家有需要的可以拿去用哈。
#批量修改文件名
#批量修改图片文件名
import os
import re
import sys
def renameall():
# fileList = os.listdir(r"E:\DATASets\gesaer") #待修改文件夹
fileList = os.listdir(r"E:\darknet\darknet-master\build\darknet\x64\data\train_images")
print("修改前:"+str(fileList)) #输出文件夹中包含的文件
currentpath = os.getcwd() #得到进程当前工作目录
os.chdir(r"E:\darknet\darknet-master\build\darknet\x64\data\train_images") #将当前工作目录修改为待修改文件夹的位置
num=1 #名称变量
for fileName in fileList: #遍历文件夹中所有文件
pat=".+\.(jpg|png|gif|JPG)" #匹配文件名正则表达式
pattern = re.findall(pat,fileName) #进行匹配
os.rename(fileName,('yeezy-350-Zebra-' + str(num)+'.'+pattern[0])) #文件重新命名 如:yeezy-350-Zebra-1
num = num+1 #改变编号,继续下一项
print("---------------------------------------------------")
os.chdir(currentpath) #改回程序运行前的工作目录
sys.stdin.flush() #刷新
print("修改后:"+str(os.listdir(r"E:\darknet\darknet-master\build\darknet\x64\data\train_images"))) #输出修改后文件夹中包含的文件
renameall()
开始标标标数据
将之前下载好的labelImg解压后,双击labelImg.exe打开。
显示以下界面。
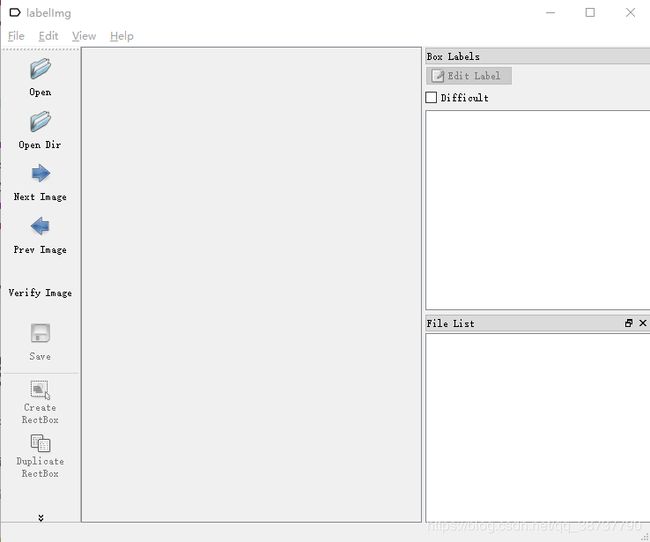
然后点击 Open Dir 按钮,打开待标签的文件夹,这里用train_images举个栗子(val_images同理哈)。
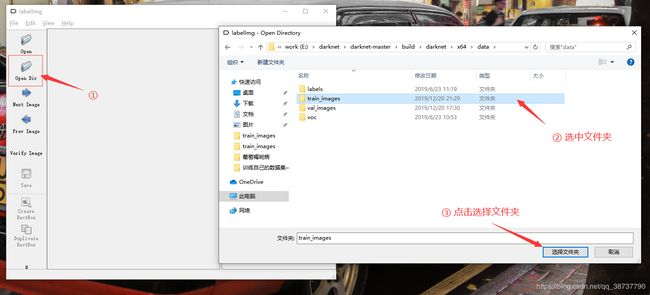
打开后如下所示。
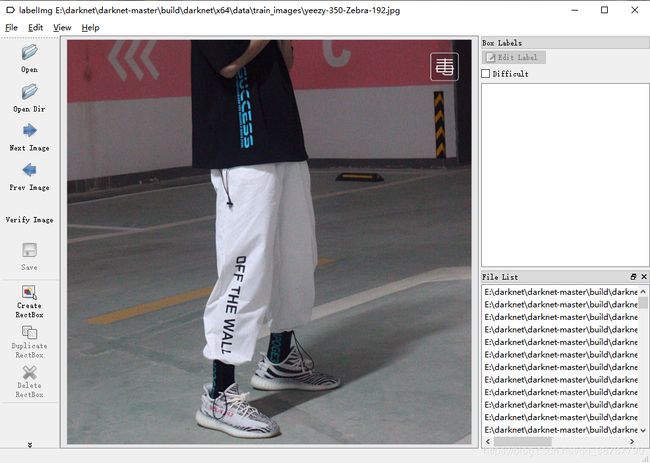
然后点击Create RectBox开始做标签(图片里有几个目标就标注几个框哈)。
比如,我要标的是白斑马(yeezy-350-Zebra),这里面有一双,那我就标两个,如果一幅图里还有别的鞋子,那就一起打上标签,然后点击Save,再点击Next Image就可以标注下一张啦~
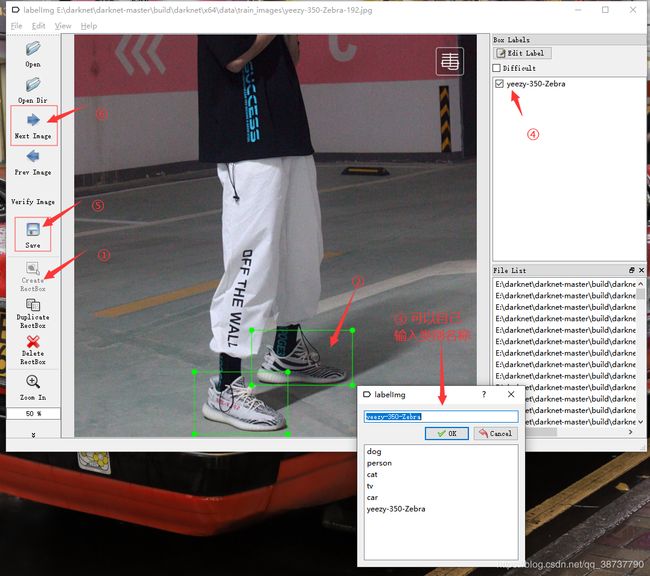
小tips:快捷键
w:创建一个矩形框
Ctrl + s:保存
d:下一张图片
a:上一张图片
Ctrl++:放大
Ctrl–:缩小
del: 删除选定的矩形框
做完标签的文件夹应是这样滴,会生成对应的 xml 文件噢。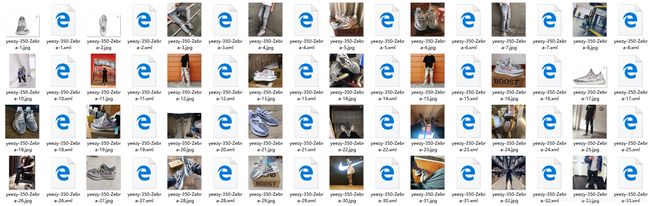
xml转txt
因为标签文件是xml的,而yolo要求的是txt(每张图要对应一个txt文件)
txt文件格式如下
< object-class > < x_center > < y_center > < width > < height >
对应的txt文件应为(举个栗子)
0 0.229 0.3605015673981191 0.063 0.10344827586206896
然后我们通过代码来将xml转txt:
注意:可以将代码在 …\darknet-master\build\darknet\x64 下
#此代码和data文件夹同目录
import glob
import xml.etree.ElementTree as ET
# 类名
class_names = ['yeezy-350-Zebra']
# xml文件路径,train_images只需改为val_images就可以处理val_images的了
path = 'data/val_images/'
# 转换一个xml文件为txt
def single_xml_to_txt(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
# 保存的txt文件路径
txt_file = xml_file.split('.')[0]+'.txt'
with open(txt_file, 'w') as txt_file:
for member in root.findall('object'):
#filename = root.find('filename').text
picture_width = int(root.find('size')[0].text)
picture_height = int(root.find('size')[1].text)
class_name = member[0].text
# 类名对应的index
class_num = class_names.index(class_name)
box_x_min = int(member[4][0].text) # 左上角横坐标
box_y_min = int(member[4][1].text) # 左上角纵坐标
box_x_max = int(member[4][2].text) # 右下角横坐标
box_y_max = int(member[4][3].text) # 右下角纵坐标
# 转成相对位置和宽高
x_center = (box_x_min + box_x_max) / (2 * picture_width)
y_center = (box_y_min + box_y_max) / (2 * picture_height)
width = (box_x_max - box_x_min) / picture_width
height = (box_y_max - box_y_min) / picture_height
print(class_num, x_center, y_center, width, height)
txt_file.write(str(class_num) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(width) + ' ' + str(height) + '\n')
# 转换文件夹下的所有xml文件为txt
def dir_xml_to_txt(path):
for xml_file in glob.glob(path + '*.xml'):
single_xml_to_txt(xml_file)
dir_xml_to_txt(path)
转换完结果如下(val_images的同理哈):
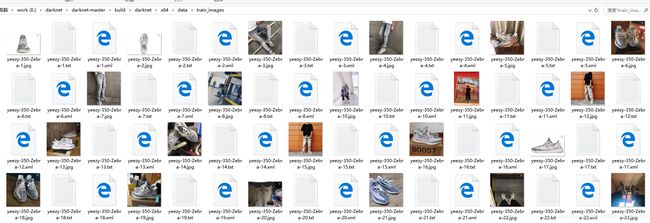
转换完成之后,xml文件暂时就没用啦,你可以删掉它,也可以将它们暂时存在某个地方。
生成train.txt 和 val.txt
一般这两个文件放在 …\darknet-master\build\darknet\x64\data 下面
train.txt文件包含train_images中所有图片的路径,每个图片一行
val.txt文件包含val_images中所有图片的路径,每个图片一行
格式如下:
data/train_images\yeezy-350-Zebra-1.jpg
data/train_images\yeezy-350-Zebra-10.jpg
生成train.txt val.txt的代码如下:
注意:可以将代码在 …\darknet-master\build\darknet\x64 下
import glob
path = 'data/'
def generate_train_and_val(image_path, txt_file):
with open(txt_file, 'w') as tf:
for jpg_file in glob.glob(image_path + '*.jpg'):
tf.write(jpg_file + '\n')
generate_train_and_val(path + 'train_images/', path + 'train.txt')
generate_train_and_val(path + 'val_images/', path + 'val.txt')
准备Sneaker.names文件
该文件(名字随意取哈,格式就是:XXXX.names)放在**…\darknet-master\build\darknet\x64\data** 下面
这个文件每一行是一个类名,因为我本次演示的只有一个类别,如果有多个类别就要注意下顺序就可以了,如下:
yeezy-350-Zebra
准备Sneaker.data文件
该文件(名字随意取哈,格式就是:XXXX.data)放在 …\darknet-master\build\darknet\x64\data 下面
classes= 1
train = data/train.txt
valid = data/val.txt
names = data/Sneaker.names
backup = backup/
classes 是类别数
准备yolov3-Sneaker.cfg_train文件
在目录 …\darknet-master\build\darknet\x64\cfg 下创建一个 yolov3-Sneaker.cfg_train 文件(名字随意取哈,格式就是:yolov3-XXXX.cfg_train),里面的内容可以复制 …\darknet-master\build\darknet\x64\cfg\yolov3.cfg 里面的内容,然后做几处修改即可。
- batch=16
- subdivisions=16
每次计算的图片数目 = batch/subdivisions,然后把结果合起来也就是一个batch更新模型一次
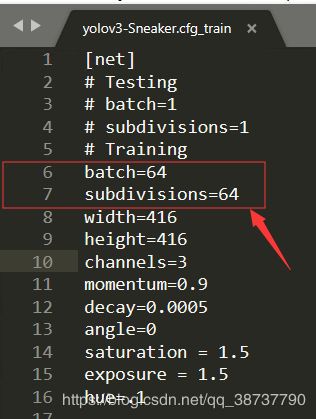
因为我用的老师电脑,配置挺高的,所以batch设置为64,subdivisions为64,可以根据自己的情况进行设置(建议一开始batch设置为16,subdivisions为16)。
否则,如果batch设置过大,则会报显存不够错误,如下图。![]()
- classes=1
classes是类别数,这里只有1类,所以设置为1,文件里一共有3处需要修改classes,一般是文件的第610、696、783行。
- filters=18
filters的计算公式为(classes + 5)x3,我们这里有1类,所以是(1+5)*3=18,文件里一共有3处需要修改,这里需要注意,文件里有多处filter,但我们只需要修改[yolo]层之前的[convolutional]层下面的filters,位置一般是文件的第603、689、776行,如下图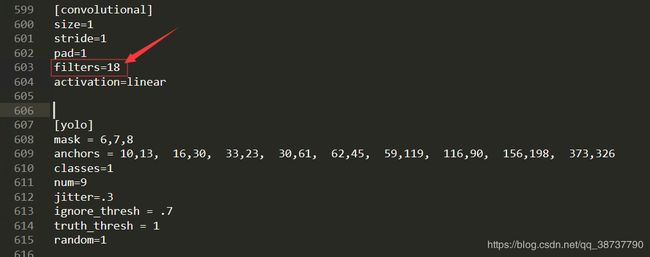

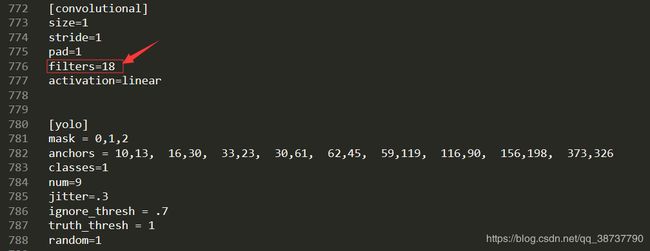
注意: 可能具体行数不一定,但注意位置改相应的地方即可。
下载预训练权重
预训练权重下载链接
下载好的与训练权重文件放在目录 …\darknet-master\build\darknet\x64 下面
开始训练
使用以下命令进行训练,在目录 …\darknet-master\build\darknet\x64 下右键—>在此处打开命令窗口(也可以打开cmd,cd到 …\darknet-master\build\darknet\x64 目录下)
darknet.exe detector train data/Sneaker.data cfg/yolov3-Sneaker.cfg_train darknet53.conv.74
每迭代100次就会在backup文件夹上生成一个模型权重,当avg loss在好几个迭代中都没有下降,此时可以停止训练了。
因为我只用了500张图片进行训练,因此迭代了1300次,准确率平均为97%,loss为0.23,并且后面loss基本稳定,就停止训练了。
测试
使用以下命令进行测试,在目录 …\darknet-master\build\darknet\x64 下右键—>在此处打开命令窗口(也可以打开cmd,cd到 …\darknet-master\build\darknet\x64 目录下)
darknet detector test data/Sneaker.data cfg/yolov3-Sneaker.cfg_test backup/yolov3-Sneaker_last.weights data/shoes.jpg
cfg/yolov3-Sneaker.cfg_test为测试的配置文件,只需要复制 cfg/yolov3-Sneaker.cfg_train 的内容然后把batch和subdivisions设置为1即可。
backup/yolov3-Sneaker_last.weights 为模型权重。
data/shoes.jpg 为测试图片的路径。
结果如下:
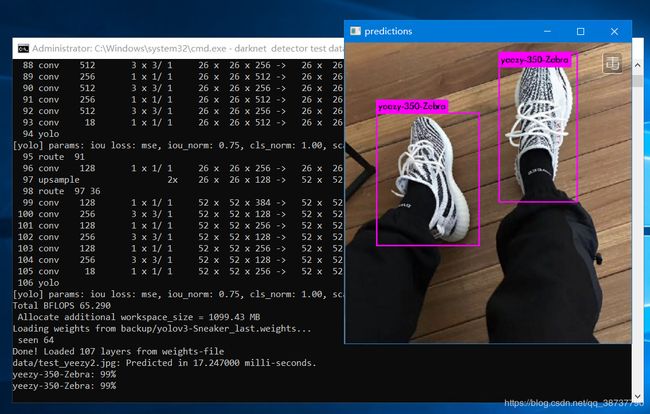
总结
本文所有的数据和代码,点击该链接获取
其实这篇训练的文章在复现的时候就已经写好存在电脑里了,但是因为有些地方有修改,加上之前比赛、项目、还有其他事情就迟迟没有上传上来。这次上传上来也是希望能给需要的朋友一些帮助,然后当时也看了很多大佬的文章,得到了很多帮助。
- YOLO3 darknet训练自己的数据
- 目标检测:YOLOv3: 训练自己的数据
如果有什么问题可以在下面留言,大家一起学习鸭鸭鸭~