KNN(K近邻分类器)Python3实现
K近邻分类器(KNN)
KNN:通过计算待分类数据点与已有数据集中的所有数据点的距离。取距离最小的前K个点,根据少数服从多数的原则,将这个数据点划分为出现次数最多的那个类别。
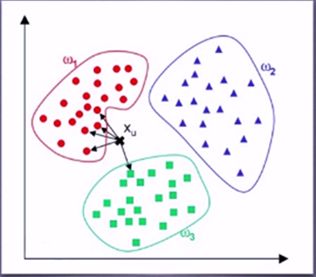
例如:图中的X点,通过计算X于所以分类点的欧式距离,然后进行排序,选择最近的前5个点做投票。可以发现X离W1分类区域点的数量最多,那么我们就认为X的分类为W1.
下面说一下代码的实现思路:
kNN算法的思想非常的朴素,它选取k个离测试点最近的样本点,输出在这k个样本点中数量最多的标签(label)。我们假设每一个样本有m个特征值(property),则一个样本的可以用一个m维向量表示: X =(x1,x2,... , xm ), 同样地,测试点的特征值也可表示成:Y =(y1,y2,... , ym )。那我们怎么定义这两者之间的“距离”呢?
在二维空间中,有:d2 = ( x1 - y1 )2 + ( x2 - y2 )2 , 在三维空间中,两点的距离被定义为:d2 = ( x1 - y1 )2 + ( x2 - y2 )2 + ( x3 - y3 )2 。我们可以据此推广到m维空间中,定义m维空间的距离:d2 = ( x1 - y1 )2 + ( x2 - y2 )2 + ...... + ( xm - ym )2 。要实现kNN算法,我们只需要计算出每一个样本点与测试点的距离,选取距离最近的k个样本,获取他们的标签(label) ,然后找出k个样本中数量最多的标签,返回该标签。
代码:(只是按照KNN的思想的大体实现,具体使用的话还需要进一步完善)
import numpy as np
def KNN(X_train,y_train,X_test,k):
#修改列表为numpy类型
X_train=np.array(X_train)
y_train = np.array(y_train)
X_test = np.array(X_test)
#获得训练、测试数据的长度
X_train_len=len(X_train)
X_test_len=len(X_test)
pre_lable=[] #存储预测标签
'''
依次遍历测试数据,计算每个测试数据与训练数据的距离值,排序,
根据前K个投票选举出预测结果
'''
for test_len in range(X_test_len): #计算测试的第一组数据
dis=[]
for train_len in range(X_train_len):
temp_dis=abs(sum(X_train[train_len,:]-X_test[test_len,:]))#计算距离
dis.append(temp_dis**0.5)
'''
print(dis)
train
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
test
[[1 2 3 4]
[5 6 7 8]]
dis
[0.0, 4.0, 5.656854249492381,0.0, 4.0, 5.656854249492381]
[4.0, 0.0, 4.0,4.0, 0.0, 4.0]
'''
dis=np.array(dis)
sort_id=dis.argsort()
# 按照升序进行快速排序,返回的是原数组的下标。
# 比如,x = [30, 10, 20, 40]
# 升序排序后应该是[10,20,30,40],他们的原下标是[1,2,0,3]
# 那么,numpy.argsort(x) = [1, 2, 0, 3]
'''
print(sort_id)
[0 3 1 4 2 5]
[1 4 0 2 3 5]
'''
'''
dicc1=[]
dicc2=[]
flag=1
for i in range(k):
for len1 in range(len(dicc1)):
print(len1)
if(len(dicc1)==0):
break
if(y_train[sort_id[i]]==dicc1[len1]):
dicc2[len1]=dicc2[len1]+1
flag=0
if(flag==1):
dicc1.append(y_train[sort_id[i]])
dicc2.append(1)
flag=1
print("test>>>")
print(dicc1)
print(dicc2)
max=0
temp=0
for i in range(len(dicc2)):
if(max max:
max = v
maxIndex = index
pre_lable.append(maxIndex)
print(X_train)
print("test")
print(X_test)
print("---------")
print(y_train)
print("pre")
print(pre_lable)
'''
C:\python_64\python.exe F:/Githouse/ML_learning/KNN.py
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
test
[[1 2 3 4]
[5 6 7 8]]
---------
[1 2 3 1 2 3]
pre
[1, 2]
'''
if __name__=="__main__":
'''
X_train=[[1,2,3,4],
[5,6,7,8],
[9,10,11,12]]
y_train=[1,2,3]
X_test=[[1,2,3,4], #那么预测数据应为 1、2
[5,6,7,8]]
'''
X_train = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]]
y_train = [1, 2, 3,1,2,3]
X_test = [[1, 2, 3, 4], # 那么预测数据应为 1、2
[5, 6, 7, 8]]
KNN(X_train,y_train,X_test,2) Sklearn库:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn import datasets
from sklearn import metrics
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
# print(iris_x)
X_train, X_test, y_train, y_test = train_test_split(iris_x, iris_y,
test_size=0.2,
random_state=42)
# 定义模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# knn.fit(X_train,y_train.ravel())
# 预测
y_pred_on_train = knn.predict(X_test)
# 输出
print(y_pred_on_train)
print("------------")
print(y_test)
acc = metrics.accuracy_score(y_test, y_pred_on_train)
print(acc)
from sklearn import neighbors
from sklearn import datasets
# 调用KNN的分类器
knn = neighbors.KNeighborsClassifier()
# 加载数据库
iris = datasets.load_iris()
# 打印数据集 包含一个四维的特征值和其对应的标签
print(iris)
knn.fit(iris.data, iris.target)
# 预测[0.1, 0.2, 0.3, 0.4]属于哪一类
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
# 打印出预测的标签
print(predictedLabel)