哈夫曼压缩与解压缩(c语言版)
目录
哈夫曼压缩与解压缩(c语言版)
一:引言
二:主要原理
三:主要技术点
四:实现过程
1.压缩:
2.解压缩:
五:详细分析,及代码实现
哈夫曼压缩与解压缩(c语言版)
一:引言
学过数据结构的同学,应该都听过哈夫曼树,和哈夫曼压缩算法,今天小编向大家讲解哈夫曼压缩与压缩的过程以及代码也算是记录一下自己所学所做的东西。
哈夫曼压缩,其实效率不是很高,一般情况下压缩率13%左右,特殊情况下效率很高(频率高的字符的情况)。但是尝试自己去完成它,对你的代码能力有很大的提升。下面开始讲解
二:主要原理
1.哈夫曼树 :
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近(频率越高的结点离根越进)。
以 下数组为例,构建哈夫曼树
int a[] = {0,1,2,3,4,5,6,7,8}
我们可以发现以下规律
1:9个数构成的哈夫曼树一共有17个结点,也就是可以n个数可以生产2*n-1个结点
2:数字越大的数离根节点越近,越小的数离根节点越近。
2.如何利用haffman编码实现文件压缩:
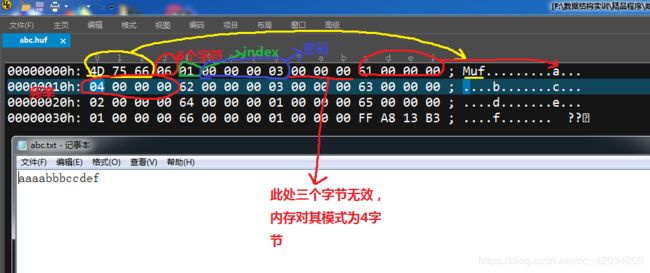
比如abc.txt文件中有以下字符:aaaabbbccde,
1.进行字符统计
aaaabbbccde
a : 4次
b : 3次
c : 2次
d : 1次
e : 1次
2.用统计结果构建哈夫曼树
3.用哈夫曼树生成哈夫曼编码(从根结点开始,路径左边记为0,右边记为1):
a的编码:1
b的编码:01
c的编码:000
d的编码:0011
e的编码:0010
4.哈夫曼编码代替字符,进行压缩。
源文件内容为:aaaabbbccde
将源文件用对应的哈夫曼编码(haffman code)替换,则有:11110101 01000000 00110010 (总共3个字节)
由此可见,源文件一共有11个字符,占11字节的内存,但是经过用haffman code替换之后,只占3个字节,这样就能达到压缩的目的
三:主要技术点
1.哈夫曼树算法(哈夫曼压缩的基本算法,如何不懂该算法,小编建议先学习下该算法)
2.哈希算法(字符统计时候会用到)
3.位运算(涉及到将指定位,置0或置1)
4.内存对齐模式(小编在这里踩过坑,非常重要)
5.存储模式(大端存储,小端存储,能看懂文件16进制的形式)
6.主函数带参(很简单)
7.设置压缩密码,解压输入密码解压(小编自己加的内容)
四:实现过程
1.压缩:
1.遍历文件每个字节,统计所有的字符和其频率,
2.构建哈夫曼树
3.遍历树,给叶子节点生成哈夫曼编码
4.将字符和其频率,以及密码,写入新文件。
5.再次遍历文件每个字节,将该字节内容用哈夫曼编码代表,将哈夫曼编码写入文件。
2.解压缩:
1.从文件中将将字符和其频率读出来,生成一张表。读之前可以先验证输入密码是否正确
2.用改表构建哈夫曼树。
3.遍历哈夫曼树,给叶子节点生成哈夫曼编码
4遍历文件每个bit位,按照哈夫曼编码,得到数个bit所对应得到字符,将该字符写入文件。
五:详细分析,及代码实现
三个必要的位运算,(这三个方法是他人提供)
//判断指定位是否为0,若index位为0,则GET_BYTE值为假,否则为真
#define GET_BYTE(value, index) (((value) & (1 << ((index) ^ 7))) != 0)
//将指定位,置为1
#define SET_BYTE(value, index) ((value) |= (1 << ((index) ^ 7)))
//将指定位,置为0
#define CLR_BYTE(value, index) ((value) &= (~(1 << ((index) ^ 7))))1.字符统计
结构体定义
typedef struct huffman{
int character;
int freq;
}HUFFMAN;统计过程及哈希算法
//count初值为0,传过来用于统计多少种字符,goalfile,为文件名称
HUFFMAN *freqhuf(int *count, char *goalfile){
int freq[256] = {0};
int i;
int index;
HUFFMAN *result;
FILE *fpIn;
int ch;
fpIn = fopen(goalfile, "rb");
ch = fgetc(fpIn);
//统计所有字符,这里巧妙的采用哈希算法,用字符的ASCII码值作为下标,
//freq[ASCII]的值,作为该字符的频率,很巧妙的形成字符和其频率的映射关系
while (!feof(fpIn)) {
freq[ch]++;
ch = fgetc(fpIn);
}
fclose(fpIn);
//统计多少种字符
for(i = 0; i < 256; i++){
if(freq[i] != 0){
(*count)++;
}
}
//将统计的结果,字符和其频率生成数组返回出去。
result = (HUFFMAN *)calloc((2*(*count) - 1), sizeof(HUFFMAN));
for(i = 0,index = 0; i < 256; i++){
if(freq[i] != 0){
result[index].character = i;
result[index++].freq = freq[i];
}
}
return result;
}2.构建哈夫曼树
//哈夫曼树的节点
typedef struct huff{
//字符及其频率
HUFFMAN freq;
//左孩子
int left;
//右孩子
int right;
//是否用过0表示没有用过1表示用过
int use;
//该节点对于的哈夫曼编码字符串
char *code;
}Huff;
//创建哈夫曼树
Huff *bulidhuftree(HUFFMAN *information, int *count){
int i;
int degree = 2*(*count) - 1;
Huff *result;
int temp;
//将生成的哈夫曼树放在result里返回
result = (Huff *)calloc(sizeof(Huff), degree);
//填充基本字符及其频度
for(i = 0; i < *count; i++){
result[i].freq.freq = information[i].freq;
result[i].freq.character= information[i].character;
result[i].left = -1;
result[i].right = -1;
result[i].use = 0;
result[i].code = (char*)malloc(sizeof(char)*(*count));
}
//根据基本字符及其频度填充哈夫曼表
for(i = *count; i < degree; i++){
result[i].use = 1;
result[i].freq.character = '#';
result[i].right = searchmin(result, *count);
result[i].left = searchmin(result, *count);
result[i].freq.freq = result[result[i].right].freq.freq + result[result[i].left].freq.freq;
temp = searchmin(result, ++(*count));
if(temp == -1){
break;
}
result[temp].use = 0;
result[i].use = 0;
}
return result;
}
//查找到频率最小的字符的下标
int searchmin(Huff *freq, int count){
int i;
int minindex = -1;
for(i = 0; i < count; i++){
if(freq[i].use == 0){
minindex = i;
break;
}
}
if(minindex == -1){
return -1;
}
for(i = 0; i < count; i++){
if((freq[i].freq.freq <= freq[minindex].freq.freq) && freq[i].use == 0){
minindex = i;
}
}
freq[minindex].use = 1;
return minindex;
}3.构建哈夫曼编码
根节点所在的下标,index为字符串下标,str为字符串,
void bulidhuftreecode(int root, int index, Huff *freq, char *str){
//采用递归,此处是哈夫曼压缩最难得地方,建议大家根据代码遍历跟踪一遍
if(freq[root].left != -1 && freq[root].right != -1){
str[index] = '1';
bulidhuftreecode(freq[root].left, index+1, freq, str);
str[index] = '0';
bulidhuftreecode(freq[root].right, index+1, freq, str);
}
else{
str[index] = 0;
strcpy(freq[root].code, str);
}
}4.写入压缩文件头信息(密码,字符数量,压缩文件标志),写入所有字符和其频率。
typedef unsigned char u8;
//压缩文件的头信息
typedef struct message{
//前三个字节用M,u,f代表哈夫曼文件,不是这三个字符代表该文件不是压缩文件
u8 ishuf[3];
//字符数量
u8 count;
//最后一个字符所对应的下标
u8 lastindex;
//密码(密码可以用自己学过的加密方式加密,这里我没有用加密算法)
int password;
}MESSAGE;
//创建压缩文件
void creatcodefile(Huff *freq, int count, char *goalfile, char *resultfile, HUFFMAN *storefreq){
FILE *fpOut;
FILE *fpIn;
unsigned char value;
int i;
int index = 0;
const char *hufCode;
int arr[256];
int ch;
int password;
MESSAGE headcode = {'M', 'u', 'f'};
//将密码存入文件头信息
printf("请设置压缩密码,以便解压时候用:\n");
scanf("%d", &headcode.password);
printf("压缩中!请稍等。\n");
fpOut = fopen(resultfile, "wb");
fpIn = fopen(goalfile, "rb");
headcode.count = (u8)(count + 1)/2;
headcode.lastindex = howlongchar(freq, count);
//将文件头信息写入文件
fwrite(&headcode, sizeof(MESSAGE), 1, fpOut);
//将字符和其频率写入文件
fwrite(storefreq, sizeof(HUFFMAN), (count + 1)/2, fpOut);
for(i = 0; i < (count + 1)/2; i++){
arr[freq[i].freq.character] = i;
}
//遍历源文件,将每个字符按其哈夫曼编码写入新文件
ch = fgetc(fpIn);
while(!feof(fpIn)){
hufCode = freq[arr[ch]].code;
for(i = 0; hufCode[i]; i++){
if(hufCode[i] == '0'){
CLR_BYTE(value, index);
}
if(hufCode[i] == '1'){
SET_BYTE(value, index);
}
if(++index >= 8){
index = 0;
fwrite(&value, 1, 1, fpOut);
}
}
ch = fgetc(fpIn);
}
if(index){
fwrite(&value, 1, 1, fpOut);
}
fclose(fpIn);
fclose(fpOut);
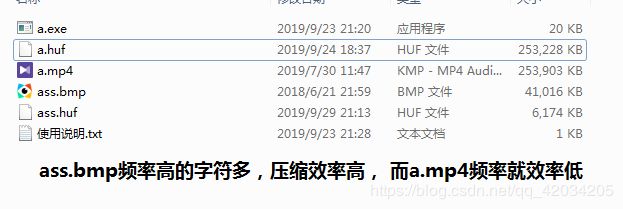
}压缩后的文件展示
主函数代码,以及其他辅助方法。
//得到哈夫曼文件最后一个字节第几个是有效位
int howlongchar(Huff *freq, int count){
int i;
int sum = 0;
for(i = 0; i < (count + 1)/2; i++){
sum = sum + strlen(freq[i].code);
sum &= 0xFF;
}
return sum % 8 == 0 ? 8 : sum % 8;
}
int main(int argc, char *argv[]) {
int count = 0;
HUFFMAN *information;
Huff *freq;
char *str;
char resultfile[50];
char goalfile[50];
FILE *fp;
int i;
fp = fopen(argv[1], "r");
if(fp == NULL){
printf("不存在该文件!");
return 0;
}
fclose(fp);
fp = fopen(argv[2], "w");
fclose(fp);
strcpy(goalfile, argv[1]);
strcpy(resultfile, argv[2]);
//统计字符
information = freqhuf(&count, goalfile);
//临时数组存每个字符code
str = (char*)malloc(sizeof(char)*(count+1));
//构建哈夫曼树
freq = bulidhuftree(information, &count);
//构建哈夫曼编码
bulidhuftreecode(count - 1, 0, freq, str);
//创建压缩文件
creatcodefile(freq, count, goalfile, resultfile, information);
//释放内存
free(information);
free(str);
for(i = 0; i < count; i++){
free(freq[i].code);
}
free(freq);
printf("压缩成功!");
return 0;
}解压缩:基本与压缩原理相似
1.从文件中将将字符和其频率读出来,生成一张表。读之前可以先验证输入密码是否正确
HUFFMAN *freqhuf(int *count, char *goalfile, int *lastindex){
int i;
HUFFMAN *result;
FILE *fpIn;
fpIn = fopen(goalfile, "rb");
if(fseek(fpIn, 3L, SEEK_SET) == 0){
fread(count, sizeof(char), 1, fpIn);
fread(lastindex, sizeof(char), 1, fpIn);
}
result = (HUFFMAN *)calloc(sizeof(HUFFMAN), *count);
if(fseek(fpIn, 12L, SEEK_SET) == 0){
fread(result, sizeof(HUFFMAN), *count, fpIn);
}
fclose(fpIn);
return result;
}2、初始化哈夫曼表
和压缩过程一样。
3、生成哈夫曼树
和压缩过程一样。
4、生成哈夫曼编码
和压缩过程一样。
5、从压缩文件中读取二进制信息,还原文件
void creatsourcefile(Huff *freq, int count, char *goalfile, char *resultfile, int lastindex){
FILE *fpOut;
FILE *fpIn;
long temp;
u8 value;
int index = 0;
int root;
long bitecount;
int fininsh = 0;
fpIn = fopen(goalfile, "rb");
fseek(fpIn, 0L, SEEK_END);
bitecount = ftell(fpIn);
fclose(fpIn);
root = count - 1;
temp = (long)(count + 1)/2;
fpOut = fopen(resultfile, "wb");
fpIn = fopen(goalfile, "rb");
if(fseek(fpIn, temp * 8 + 12, SEEK_SET) == 0){
printf("解码中!");
fread(&value, sizeof(char), 1, fpIn);
while(!fininsh){
if(GET_BYTE(value, index) == 0){
root = freq[root].right;
}
if(GET_BYTE(value, index) == 1){
root = freq[root].left;
}
if(freq[root].right == -1 && freq[root].right == -1){
fwrite(&freq[root].freq.character, sizeof(char), 1, fpOut);
root = count - 1;
}
if(++index >= 8){
index = 0;
fread(&value, sizeof(char), 1, fpIn);
}
if(ftell(fpIn) == bitecount){
if(index >= lastindex){
fininsh = 1;
}
}
}
printf("解码成功!\n");
}
else{
printf("解码失败!\n");
}
}主函数
int main(int argc, char *argv[]) {
int count = 0;
HUFFMAN *information;
Huff *freq;
char *str;
char resultfile[50];
char goalfile[50];
FILE *fp;
char Huf[3];
int lastindex = 0;
int i;
int password;
int unpassword;
fp = fopen(argv[1], "rb");
if(fp == NULL){
printf("不存在该文件!");
return 0;
}
fread(&Huf, sizeof(char), 3, fp);
if(Huf[0] != 'M' || Huf[1] != 'u' || Huf[2] != 'f'){
printf("该文件不是哈夫曼压缩的文件!");
return 0;
}
if(fseek(fp, 8L, SEEK_SET) == 0){
fread(&password, sizeof(int), 1, fp);
printf("请输入解压密码:");
scanf("%d", &unpassword);
if(password != unpassword){
printf("密码错误!");
return 0;
}
}
fclose(fp);
fp = fopen(argv[2], "w");
fclose(fp);
strcpy(goalfile, argv[1]);
strcpy(resultfile, argv[2]);
information = freqhuf(&count, goalfile, &lastindex);
str = (char*)malloc(sizeof(char)*(count+1)); //临时数组存每个字符code
freq = bulidhuftree(information, &count);
bulidhuftreecode(count - 1, 0, freq, str);
free(str);
creatsourcefile(freq, count, goalfile, resultfile, lastindex);
free(information);
for(i = 0; i < count; i++){
free(freq[i].code);
}
free(freq);
free(str);
return 0;
}