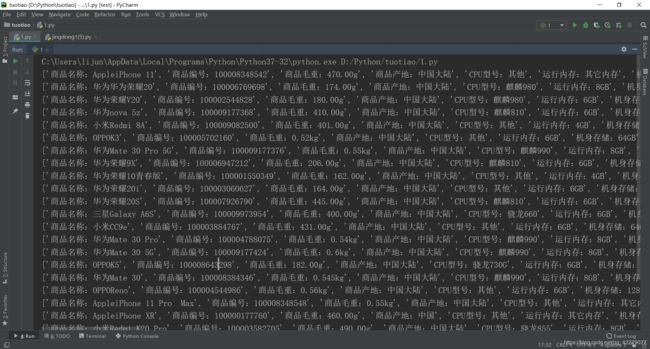
Python3爬取京东商品数据,解决赖加载问题
前言
在这里我就不再一一介绍每个步骤的具体操作了,因为在上一次爬取今日头条数据的时候都已经讲的非常清楚了,所以在这里我只会在重点上讲述这个是这么实现的,如果想要看具体步骤请先去看我今日头条的文章内容,里面有非常详细的介绍以及是怎么找到加密js代码和api接口。
Python3爬取今日头条文章视频数据,完美解决as、cp、_signature的加密方法
爬取数据
爬取京东商品信息首先需要先获取到他的商品url链接,然后才能获取到商品的信息,所以在这里我爬取的商品url链接是在分类和搜索里面的,分类和搜索两个是有区别的,分类中的商品url链接可以直接通过xpath进行提取,但是搜索中的商品url链接有赖加载机制,需要分析、破解、实现才能获取到的。
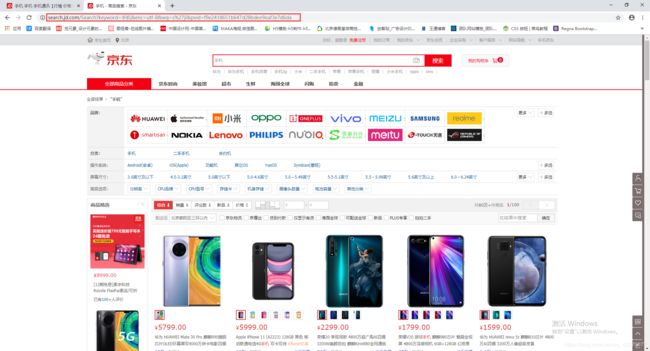
下图是两者的区别:
分类:
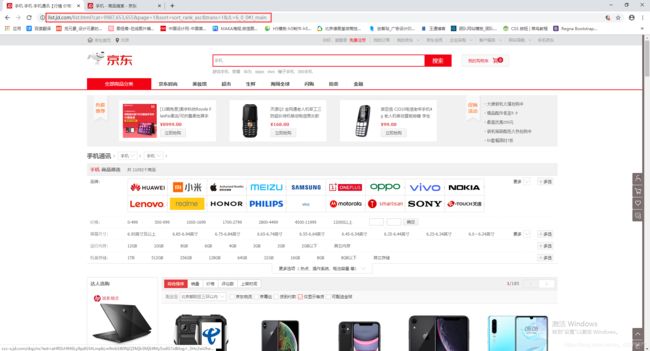
搜索:
分类区域商品信息爬取
提取商品url链接
分类区域没有赖加载机制,可以直接进行提取商品url链接。
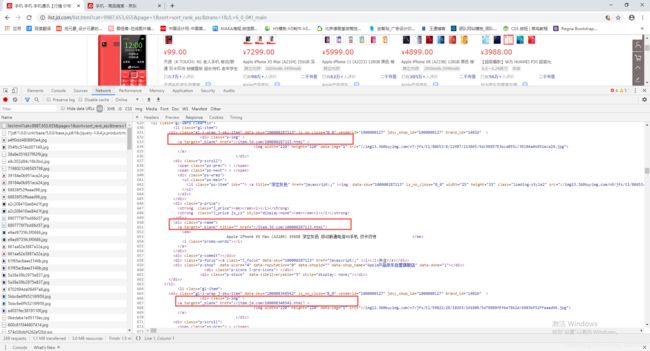
从图中可以看到商品url链接都在class属性为p-img(点击商品图片跳转的链接地址)和p-name(点击商品名称跳转的链接地址)中,这里我用p-img来进行提取,用p-name也是一样的操作。
import requests
from lxml import etree
url = "https://list.jd.com/list.html?cat=9987,653,655"
headers = {
'authority': 'list.jd.com',
'method': 'GET',
'path': '/list.html?cat=9987,653,655', #这个参数可变可不变,不影响请求结果
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jda=122270672.1342884474.1568857058.1573271812.1573438988.18; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; listck=7fecc6cf9704f1375fe8495d6f662ffd; _gcl_au=1.1.285951031.1573439265; __jdb=122270672.6.1342884474|18.1573438988; shshshsID=2ed194eabc3c4f9c0c06c4b18e4ff17e_5_1573439385602',
'if-modified-since': 'Mon, 11 Nov 2019 02:27:40 GMT',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url,headers=headers)
html = etree.HTML(response.text)
plist = ['https:'+ i for i in html.xpath('//div[@class="p-img"]/a/@href')]
print(plist)
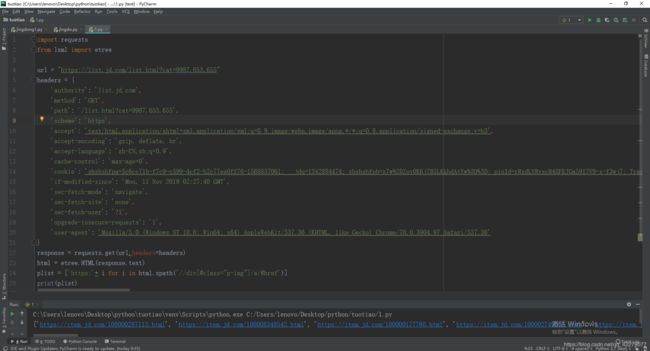
提取商品url链接的问题就解决了,可是这样提取的是单页的,这并不符合我们提取多页的商品url链接,可以尝试翻页一下,发现url链接发生变化,由https://list.jd.com/list.html变为https://list.jd.com/list.html?cat=9987,653,655&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main,当你翻到第三页发现只变化了一个page参数(https://list.jd.com/list.html?cat=9987,653,655&page=3&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main),由此得知page参数是用来翻页的,那么这样就非常好实现了。
import requests
from lxml import etree
def get_url(url,page):
url = url + "&page=" + str(page) + "&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"
headers = {
'authority': 'list.jd.com',
'method': 'GET',
'path': '/' + url.split('/')[-1],
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jda=122270672.1342884474.1568857058.1573271812.1573438988.18; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; listck=7fecc6cf9704f1375fe8495d6f662ffd; _gcl_au=1.1.285951031.1573439265; __jdb=122270672.6.1342884474|18.1573438988; shshshsID=2ed194eabc3c4f9c0c06c4b18e4ff17e_5_1573439385602',
'if-modified-since': 'Mon, 11 Nov 2019 02:27:40 GMT',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url,headers=headers)
html = etree.HTML(response.text)
plist = ['https:'+ i for i in html.xpath('//div[@class="p-img"]/a/@href')]
print(plist)
if __name__ == '__main__':
for i in range(1,185+1):
print(i)
get_url('https://list.jd.com/list.html?cat=9987,653,655',i)
商品url链接全部获取完毕后,就可以对里面进行数据的提取了。
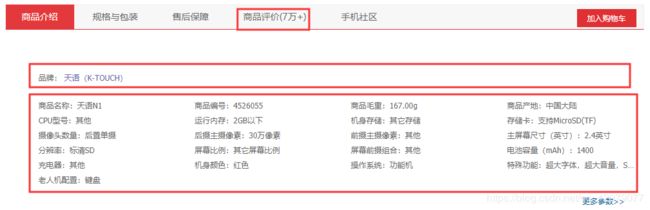
提取商品的详细信息
提取的信息有店铺名称、价格、评价数、品牌、商品信息,分析网站后发现价格和评价数是没有的,得单独请求api接口才能获取到。
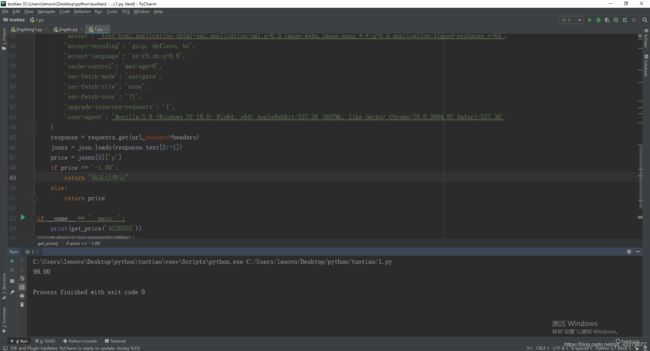
价格:
def get_price(sid):
url = 'https://p.3.cn/prices/mgets?skuIds=' + sid #sid就是商品url链接的那串数字,比如:https://item.jd.com/4526055.html,4526055就是sid
headers = {
'authority': 'p.3.cn',
'method': 'GET',
'path': '/' + url.split('/')[-1],
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url,headers=headers)
jsons = json.loads(response.text[0:-1])
price = jsons[0]['p']
if price == '-1.00':
return "商品已售完"
else:
return price
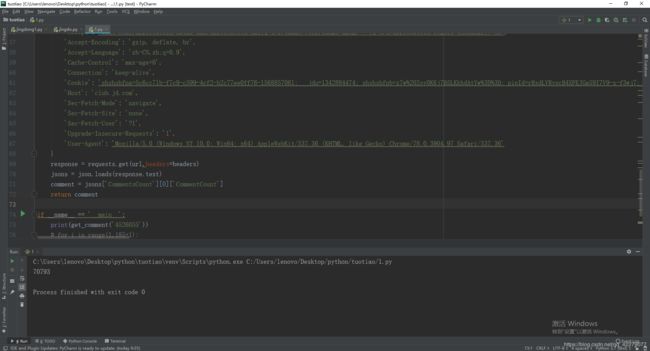
评价数:
def get_comment(sid):
url = 'https://club.jd.com/comment/productCommentSummaries.action?referenceIds=' + sid #sid就是商品url链接的那串数字,比如:https://item.jd.com/4526055.html,4526055就是sid
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; _gcl_au=1.1.285951031.1573439265; shshshsID=3a388fab20722fd601b01a37ad2f8b45_1_1573449585481; __jda=122270672.1342884474.1568857058.1573444194.1573449586.20; __jdb=122270672.1.1342884474|20.1573449586',
'Host': 'club.jd.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url,headers=headers)
jsons = json.loads(response.text)
comment = jsons['CommentsCount'][0]['CommentCount']
return comment
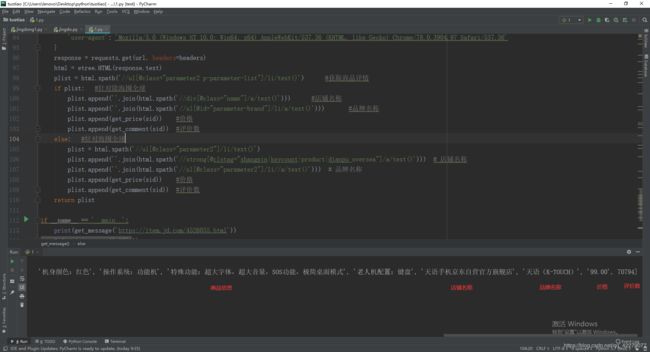
商品详细信息(包括商铺名称、品牌,价格,评价数):
def get_message(url):
hz = url.split('/')[-1]
path = '/' + hz
sid = hz.split('.')[0]
headers = {
'authority': 'item.jd.com',
'method': 'GET',
'path': path,
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jda=122270672.1342884474.1568857058.1573271812.1573438988.18; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; _gcl_au=1.1.285951031.1573439265; shshshsID=2ed194eabc3c4f9c0c06c4b18e4ff17e_6_1573440208520; __jdb=122270672.8.1342884474|18.1573438988',
'if-modified-since': 'Mon, 11 Nov 2019 02:43:25 GMT',
'referer': 'https://list.jd.com/list.html?cat=1320,5019,15053', #这个不影响结果
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
plist = html.xpath('//ul[@class="parameter2 p-parameter-list"]/li/text()') #获取商品详情
if plist: #针对除海囤全球
plist.append(''.join(html.xpath('//div[@class="name"]/a/text()'))) #店铺名称
plist.append(''.join(html.xpath('//ul[@id="parameter-brand"]/li/a/text()'))) #品牌名称
plist.append(get_price(sid)) #价格
plist.append(get_comment(sid)) #评价数
else: #针对海囤全球
plist = html.xpath('//ul[@class="parameter2"]/li/text()')
plist.append(''.join(html.xpath('//strong[@clstag="shangpin|keycount|product|dianpu_oversea"]/a/text()'))) # 店铺名称
plist.append(''.join(html.xpath('//ul[@class="parameter2"]/li//a/text()'))) # 品牌名称
plist.append(get_price(sid)) #价格
plist.append(get_comment(sid)) #评价数
return plist
分类商品的所有数据就都获取到了,下面是获取搜索商品的数据。
搜索区域商品信息爬取
提取商品url链接
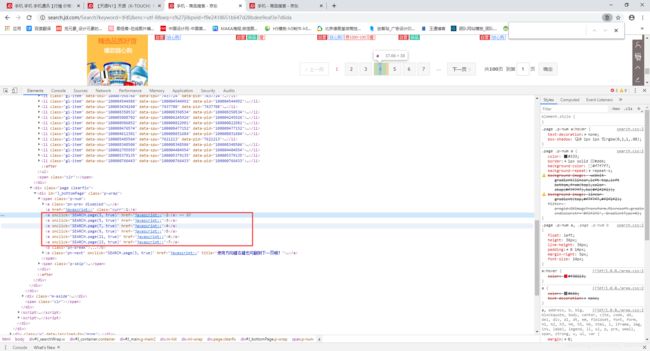
从图中可以看到搜索区域中的商品url链接只有30条(一共60条),另外30条是赖加载出来的,所以我们需要获取赖加载的另外30条。
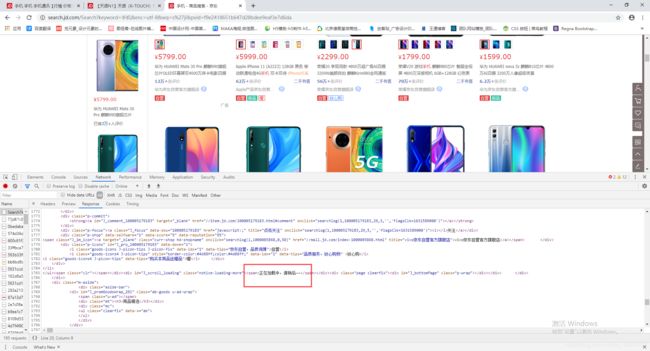
没有赖加载获取30条:
def get_url2(url):
headers = {
'authority': 'search.jd.com',
'method': 'GET',
'path': url.split('/')[-1],
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; xtest=5565.cf6b6759; qrsc=3; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; user-key=2255241e-ef8a-41f1-870a-e532de675198; cn=0; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; __jdu=1342884474; _gcl_au=1.1.1673204888.1573896089; __jdc=122270672; rkv=V0500; mt_xid=V2_52007VwMQV15RW18aTxxsVTcAQVJVWFZGFhkfVBliUUJSQVFaCk9VGVkBYlZBAA9bUV9MeRpdBW8fElJBWFtLH0kSXw1sARBiX2hSahZMGV8GZQMVVm1YVF4b; __jda=122270672.1342884474.1568857058.1574047776.1574064097.43; __jdb=122270672.1.1342884474|43.1574064097; shshshfp=a5cbf838eea824c782a9a7a3809e73ef; shshshsID=faaf14589e1a65cea0ccde2237f60357_1_1574064097380',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8')
htmls = etree.HTML(html)
url_list = []
for i in htmls.xpath('//div[@class="p-img"]/a/@href'):
if 'https' in i:
url_list.append(i)
else:
url_list.append('https:' + i)
return url_list
有赖加载获取60条:
按照我今日头条搜索JS代码的方式来看京东赖加载的JS代码是怎么实现的。这里需要你有一定的JS基础,否则你很难看懂里面的JS代码。
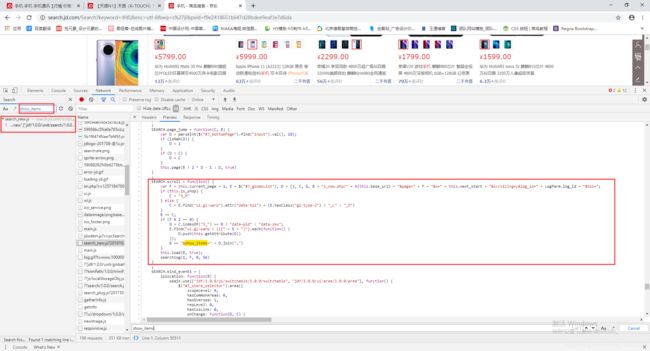
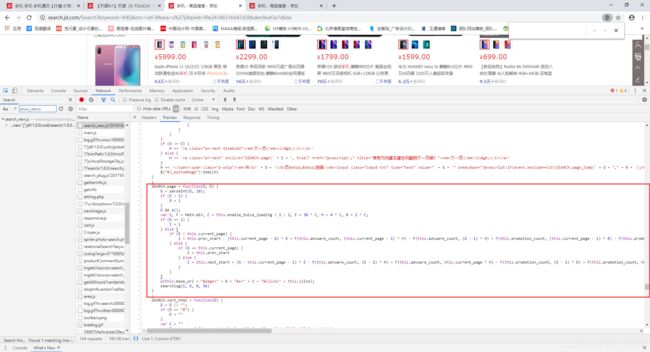
从上面代码中可以看到很多未知的变量,比如this.current_page、this.base_url、this.next_start、logParm.log_id,那么我们继续搜索。
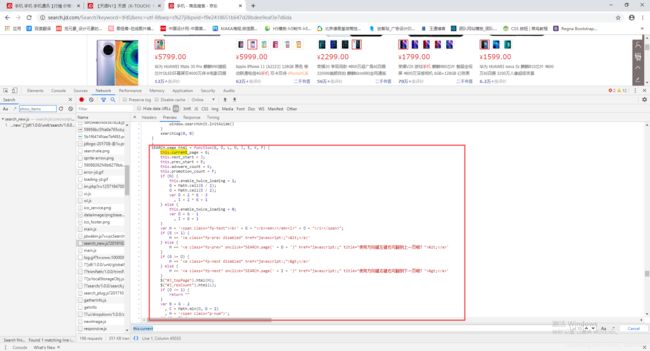
可以看到类中新定义的参数都在这里,那么page_html的参数值是从哪里传递的呢?这里我查看了整个JS代码文件,从里面找到了page_html的参数值是怎么传递的。
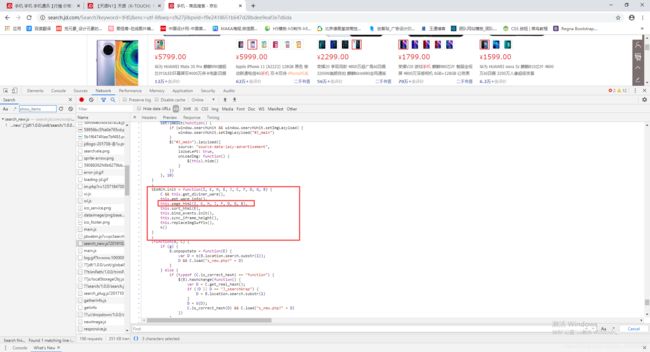
可以看到上图中的参数,你只需要重新把参数定义一下就可以了,这里很简单。我们还需要查询init的参数值是什么。
可以看见下面图片中调用了这个JS代码的SEARCH.init(),那么只需要把这个文件里面的参数值获取到,然后还原一下JS代码就可以实现访问赖加载的数据了。
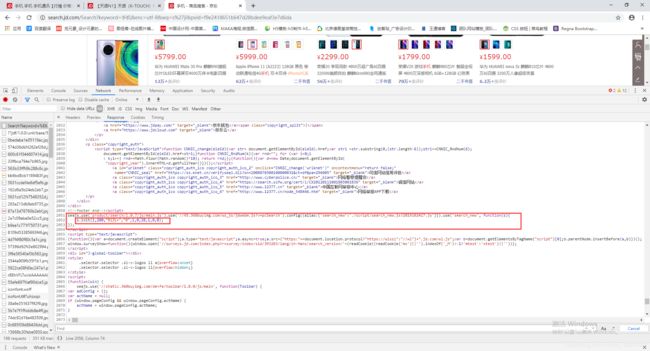
this.base_url参数的定义:
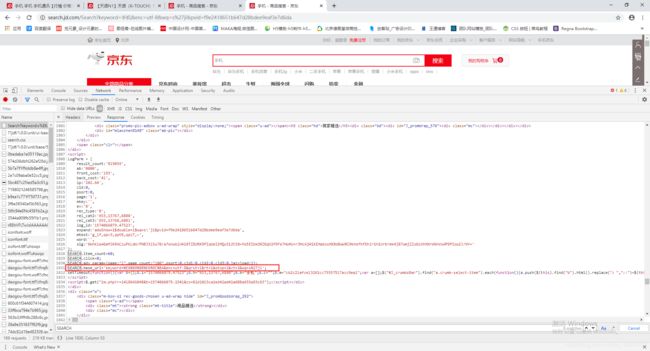
获取赖加载数据参数:
# 获取赖加载数据参数
def get_params(html_data):
#html_data:网页的源码,从里面提取出数据
html = etree.HTML(html_data)
init_script = html.xpath('//script/text()')[5]
param_script = html.xpath('//script/text()')[2]
params = re.findall(r".*log_id:'(.*?)',.*SEARCH.base_url='(.*)';.*", param_script,re.DOTALL) # re.DOTALL表示.能匹配包括\n在内的字符
init_params = re.findall(r'.*s.init\((.*?)\);.*', init_script, re.DOTALL)
init_params = str(init_params[0]).split(',')
#获取SEACH.init里的参数值
for i in range(len(init_params)):
if init_params[i].replace('"', '').isdecimal():
init_params[i] = int(init_params[i].replace('"', ''))
else:
init_params[i] = init_params[i].replace('"', '')
base_url = str(params[0][1]) #获取this.base_url参数值
param = []
param.append(init_params)
param.append(base_url)
return param
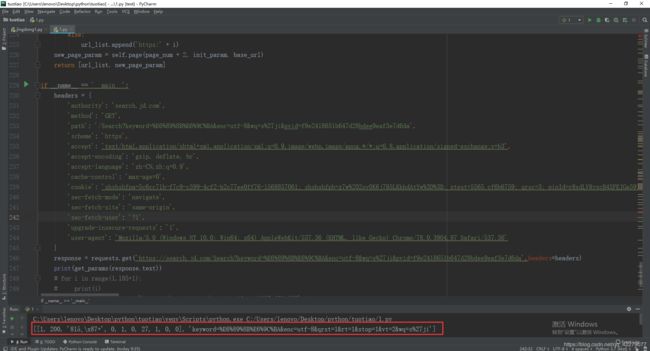
赖加载请求链接:
赖加载请求链接就是上面图片中你看到SEARCH.scroll里的代码。
JS代码:
SEARCH.scroll = function() {
var F = this.current_page + 1, E = $("#J_goodsList"), D = [], C, G, B = "s_new.php?" + b(this.base_url) + "&page=" + F + "&s=" + this.next_start + "&scrolling=y&log_id=" + LogParm.log_id + "&tpl=";
if (this.is_shop) {
C = "3_M"
} else {
C = E.find("ul.gl-warp").attr("data-tpl") + (E.hasClass("gl-type-2") ? "_L" : "_M")
}
B += C;
if (F % 2 == 0) {
G = C.indexOf("3_") == 0 ? "data-pid" : "data-sku";
E.find("ul.gl-warp > li[" + G + "]").each(function() {
D.push(this.getAttribute(G))
});
B += "&show_items=" + D.join(",")
}
this.load(B, true); //这个对我们没有用
searchlog(1, F, 0, 56) //这个对我们没有用
};
Python实现:
def scroll(init_param,html_data,base_url):
#init_param:SEARCH.init函数里的参数值,上面哪个函数已经实现了
#html_data:网页的源码,从里面提取出数据
#base_url:SEARCH.base_url,上面函数已经实现了
html = etree.HTML(html_data)
F = init_param[0] + 1
E = html.xpath('//*[@id="J_goodsList"]')[0]
B = "s_new.php?" + base_url + "&page=" + str(F) + "&s=" + str(init_param[6]) + "&scrolling=y&log_id=" + str(time.time())[0:-2] + "&tpl="
c = "_L" if E.xpath('*[@class="gl-type-2"]') else "_M"
C = E.xpath('//ul[contains(@class,"gl-warp")]/@data-tpl')[0] + c if E.xpath('//ul[contains(@class,"gl-warp")]/@data-tpl')[0] else "3_M"
B = B + C
if F % 2 == 0:
G = "data-pid" if C.find('3_') == 0 else "data-sku"
B = B + "&show_items=" + ','.join(E.xpath('//ul[contains(@class,"gl-warp")]/li[@' + G + ']/@' + G))
return B

合并代码后:
def get_url2(url):
url2 = "https://search.jd.com/"
headers = {
'authority': 'search.jd.com',
'method': 'GET',
'path': '/' + url.split('/')[-1],
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; xtest=5565.cf6b6759; qrsc=3; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; user-key=2255241e-ef8a-41f1-870a-e532de675198; cn=0; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; __jdu=1342884474; _gcl_au=1.1.1673204888.1573896089; __jdc=122270672; rkv=V0500; mt_xid=V2_52007VwMQV15RW18aTxxsVTcAQVJVWFZGFhkfVBliUUJSQVFaCk9VGVkBYlZBAA9bUV9MeRpdBW8fElJBWFtLH0kSXw1sARBiX2hSahZMGV8GZQMVVm1YVF4b; shshshfp=a5cbf838eea824c782a9a7a3809e73ef; __jda=122270672.1342884474.1568857058.1574064097.1574066075.44; __jdb=122270672.1.1342884474|44.1574066075; shshshsID=969fcf68bddac238a2163109fb55b8f7_1_1574066075519',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8')
htmls = etree.HTML(html)
url_list = []
for i in htmls.xpath('//div[@class="p-img"]/a/@href'):
if 'https' in i:
url_list.append(i)
else:
url_list.append('https:' + i)
init_param, base_url = get_params(html)
scroll_param = scroll(init_param, html, base_url)
scroll_url = url2 + scroll_param
headers = {
'authority': 'search.jd.com',
'method': 'GET',
'path': '/' + scroll_param,
'scheme': 'https',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; xtest=5565.cf6b6759; qrsc=3; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; user-key=2255241e-ef8a-41f1-870a-e532de675198; cn=0; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; __jdu=1342884474; shshshfp=a5cbf838eea824c782a9a7a3809e73ef; __jda=122270672.1342884474.1568857058.1573810050.1573882929.36; __jdc=122270672; rkv=V0500; __jdb=122270672.2.1342884474|36.1573882929; shshshsID=3dd9131907c755c9afd6391d2b1e7c01_2_1573882940497',
'referer': url,
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
response = requests.get(scroll_url, headers=headers)
html = response.content.decode('utf-8')
htmls = etree.HTML(html)
for i in htmls.xpath('//div[@class="p-img"]/a/@href'):
if 'https' in i:
url_list.append(i)
else:
url_list.append('https:' + i)
return url_list
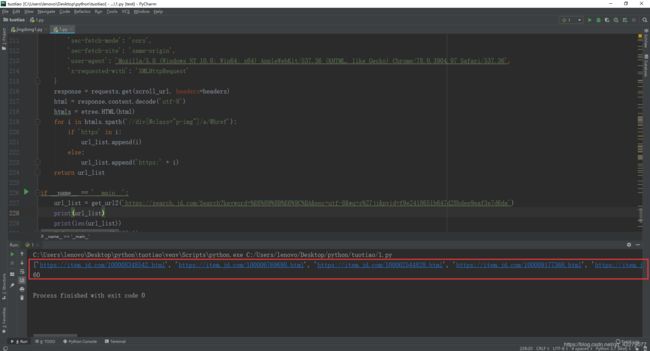
但是这个并没有实现获取多页的商品url链接。你可以尝试翻一下第二页和第三页,发现两个链接的特征,第二页:https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=s%27ji&page=3&s=58&click=0和第三页:https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=s%27ji&page=5&s=111&click=0,可以发现的是有变化的参数是page和s,所以下面实现page和s来达到获取多页的商品url链接。
这两个参数居然是变化的那么肯定有生成他的函数,所以我们查看一下下一页的函数是什么,可以看到结果。
JS代码:
SEARCH.page = function(G, D) {
G = parseInt(G, 10);
if (G < 1) {
G = 1
}
D && e();
var I, F = Math.min, C = this.enable_twice_loading ? 1 : 2, E = 30 * C, H = 4 * C, B = 2 * C;
if (G == 1) {
I = 1
} else {
if (G < this.current_page) {
I = this.prev_start - (this.current_page - G) * E + F(this.advware_count, (this.current_page - 1) * H) - F(this.advware_count, (G - 1) * H) + F(this.promotion_count, (this.current_page - 1) * B) - F(this.promotion_count, (G - 1) * B)
} else {
if (G == this.current_page) {
I = this.prev_start
} else {
I = this.next_start + (G - this.current_page - 1) * E - F(this.advware_count, (G - 1) * H) + F(this.advware_count, this.current_page * H) - F(this.promotion_count, (G - 1) * B) + F(this.promotion_count, this.current_page * B)
}
}
}
w(this.base_url + "&page=" + G + "&s=" + I + "&click=" + this.click);
searchlog(1, G, 0, 56)
}
;
Python实现:
def page(G,init_param,base_url):
#G:是page_count,主要是页码,根据规律是翻页为单数(1,3,5,7...),也就是第一页为1,第二页为3以此类推,双数是获取赖加载的(跟这里面没关系,是上面哪个代码的)
#init_param:SEARCH.init函数里的参数值,上面哪个函数已经实现了
#base_url:SEARCH.base_url,上面函数已经实现了
G = 1 if int(G) < 1 else int(G)
C = 1 if init_param[4] else 2
E = 30 * C
H = 4 * C
B = 2 * C
current_page = init_param[0]
next_start = init_param[6]
prev_start = init_param[7]
advware_count = init_param[8]
promotion_count = init_param[9]
I = 0
if G == 1:
I = 1
else:
if G < current_page:
I = prev_start - (current_page - G) * E + min(advware_count, (current_page - 1) * H) - min(advware_count, (G - 1) * H) + min(promotion_count, (current_page - 1) * B) - min(promotion_count, (G - 1) * B)
else:
if G == current_page:
I = prev_start
else:
I = next_start + (G - current_page - 1) * E - min(advware_count, (G - 1) * H) + min(advware_count, current_page * H) - min(promotion_count, (G - 1) * B) + min(promotion_count,current_page * B)
return "Search?" + base_url + "&page=" + str(G) + "&s=" + str(I) + "&click=0"
合着使用:
def get_url2(page_num, page_param):
url = "https://search.jd.com/"
page_url = url + page_param
headers = {
'authority': 'search.jd.com',
'method': 'GET',
'path': '/' + page_param,
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; xtest=5565.cf6b6759; qrsc=3; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; user-key=2255241e-ef8a-41f1-870a-e532de675198; cn=0; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; __jdu=1342884474; _gcl_au=1.1.1673204888.1573896089; mt_xid=V2_52007VwMQV15RW18aTxxsVTcAQVJVWFZGFhkfVBliUUJSQVFaCk9VGVkBYlZBAA9bUV9MeRpdBW8fElJBWFtLH0kSXw1sARBiX2hSahZMGV8GZQMVVm1YVF4b; __jda=122270672.1342884474.1568857058.1574066075.1574068886.45; __jdc=122270672; shshshfp=a5cbf838eea824c782a9a7a3809e73ef; rkv=V0500; __jdb=122270672.5.1342884474|45.1574068886; shshshsID=77f49fee8b3efadff885bbb99a9693ef_4_1574070380090',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(page_url, headers=headers)
html = response.content.decode('utf-8')
htmls = etree.HTML(html)
url_list = []
for i in htmls.xpath('//div[@class="p-img"]/a/@href'):
if 'https' in i:
url_list.append(i)
else:
url_list.append('https:' + i)
init_param, base_url = get_params(html)
scroll_param = scroll(init_param, html, base_url)
scroll_url = url + scroll_param
headers = {
'authority': 'search.jd.com',
'method': 'GET',
'path': '/' + scroll_param,
'scheme': 'https',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; xtest=5565.cf6b6759; qrsc=3; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; user-key=2255241e-ef8a-41f1-870a-e532de675198; cn=0; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; __jdu=1342884474; shshshfp=a5cbf838eea824c782a9a7a3809e73ef; __jda=122270672.1342884474.1568857058.1573810050.1573882929.36; __jdc=122270672; rkv=V0500; __jdb=122270672.2.1342884474|36.1573882929; shshshsID=3dd9131907c755c9afd6391d2b1e7c01_2_1573882940497',
'referer': page_url,
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
response = requests.get(scroll_url, headers=headers)
html = response.content.decode('utf-8')
htmls = etree.HTML(html)
for i in htmls.xpath('//div[@class="p-img"]/a/@href'):
if 'https' in i:
url_list.append(i)
else:
url_list.append('https:' + i)
new_page_param = page(page_num + 2, init_param, base_url)
return [url_list, new_page_param]
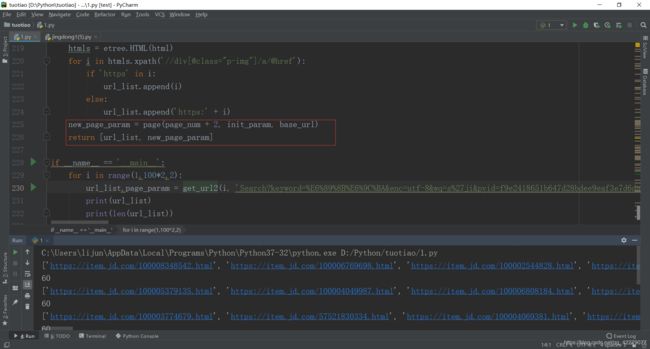
这样就做完了,下面给出个完整代码。
完整代码:
import requests,json,re,time
from lxml import etree
#获取商品url链接
def get_url(url,page):
url = url + "&page=" + str(page) + "&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"
headers = {
'authority': 'list.jd.com',
'method': 'GET',
'path': '/' + url.split('/')[-1],
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jda=122270672.1342884474.1568857058.1573271812.1573438988.18; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; listck=7fecc6cf9704f1375fe8495d6f662ffd; _gcl_au=1.1.285951031.1573439265; __jdb=122270672.6.1342884474|18.1573438988; shshshsID=2ed194eabc3c4f9c0c06c4b18e4ff17e_5_1573439385602',
'if-modified-since': 'Mon, 11 Nov 2019 02:27:40 GMT',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url,headers=headers)
html = etree.HTML(response.text)
plist = ['https:'+ i for i in html.xpath('//div[@class="p-img"]/a/@href')]
print(plist)
#获取商品价格
def get_price(sid):
url = 'https://p.3.cn/prices/mgets?skuIds=' + sid
headers = {
'authority': 'p.3.cn',
'method': 'GET',
'path': '/' + url.split('/')[-1],
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url,headers=headers)
jsons = json.loads(response.text[0:-1])
price = jsons[0]['p']
if price == '-1.00':
return "商品已售完"
else:
return price
#获取商品评价数
def get_comment(sid):
url = 'https://club.jd.com/comment/productCommentSummaries.action?referenceIds=' + sid #sid就是商品url链接的那串数字,比如:https://item.jd.com/4526055.html,4526055就是sid
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; _gcl_au=1.1.285951031.1573439265; shshshsID=3a388fab20722fd601b01a37ad2f8b45_1_1573449585481; __jda=122270672.1342884474.1568857058.1573444194.1573449586.20; __jdb=122270672.1.1342884474|20.1573449586',
'Host': 'club.jd.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url,headers=headers)
jsons = json.loads(response.text)
comment = jsons['CommentsCount'][0]['CommentCount']
return comment
#获取商品详细信息
def get_message(url):
hz = url.split('/')[-1]
path = '/' + hz
sid = hz.split('.')[0]
headers = {
'authority': 'item.jd.com',
'method': 'GET',
'path': path,
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jda=122270672.1342884474.1568857058.1573271812.1573438988.18; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; _gcl_au=1.1.285951031.1573439265; shshshsID=2ed194eabc3c4f9c0c06c4b18e4ff17e_6_1573440208520; __jdb=122270672.8.1342884474|18.1573438988',
'if-modified-since': 'Mon, 11 Nov 2019 02:43:25 GMT',
'referer': 'https://list.jd.com/list.html?cat=1320,5019,15053',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
plist = html.xpath('//ul[@class="parameter2 p-parameter-list"]/li/text()') #获取商品详情
if plist: #针对除海囤全球
plist.append(''.join(html.xpath('//div[@class="name"]/a/text()'))) #店铺名称
plist.append(''.join(html.xpath('//ul[@id="parameter-brand"]/li/a/text()'))) #品牌名称
plist.append(get_price(sid)) #价格
plist.append(get_comment(sid)) #评价数
else: #针对海囤全球
plist = html.xpath('//ul[@class="parameter2"]/li/text()')
plist.append(''.join(html.xpath('//strong[@clstag="shangpin|keycount|product|dianpu_oversea"]/a/text()'))) # 店铺名称
plist.append(''.join(html.xpath('//ul[@class="parameter2"]/li//a/text()'))) # 品牌名称
plist.append(get_price(sid)) #价格
plist.append(get_comment(sid)) #评价数
return plist
# 获取赖加载数据参数
def get_params(html_data):
html = etree.HTML(html_data)
init_script = html.xpath('//script/text()')[5]
param_script = html.xpath('//script/text()')[2]
params = re.findall(r".*log_id:'(.*?)',.*SEARCH.base_url='(.*)';.*", param_script,re.DOTALL) # re.DOTALL表示.能匹配包括\n在内的字符
init_params = re.findall(r'.*s.init\((.*?)\);.*', init_script, re.DOTALL)
init_params = str(init_params[0]).split(',')
for i in range(len(init_params)):
if init_params[i].replace('"', '').isdecimal():
init_params[i] = int(init_params[i].replace('"', ''))
else:
init_params[i] = init_params[i].replace('"', '')
base_url = str(params[0][1])
param = []
param.append(init_params)
param.append(base_url)
return param
# 赖加载请求链接
def scroll(init_param,html_data,base_url):
html = etree.HTML(html_data)
F = init_param[0] + 1
E = html.xpath('//*[@id="J_goodsList"]')[0]
B = "s_new.php?" + base_url + "&page=" + str(F) + "&s=" + str(init_param[6]) + "&scrolling=y&log_id=" + str(time.time())[0:-2] + "&tpl="
c = "_L" if E.xpath('*[@class="gl-type-2"]') else "_M"
C = E.xpath('//ul[contains(@class,"gl-warp")]/@data-tpl')[0] + c if E.xpath('//ul[contains(@class,"gl-warp")]/@data-tpl')[0] else "3_M"
B = B + C
if F % 2 == 0:
G = "data-pid" if C.find('3_') == 0 else "data-sku"
B = B + "&show_items=" + ','.join(E.xpath('//ul[contains(@class,"gl-warp")]/li[@' + G + ']/@' + G))
return B
# 翻页请求链接
def page(G,init_param,base_url):
G = 1 if int(G) < 1 else int(G)
C = 1 if init_param[4] else 2
E = 30 * C
H = 4 * C
B = 2 * C
current_page = init_param[0]
next_start = init_param[6]
prev_start = init_param[7]
advware_count = init_param[8]
promotion_count = init_param[9]
I = 0
if G == 1:
I = 1
else:
if G < current_page:
I = prev_start - (current_page - G) * E + min(advware_count, (current_page - 1) * H) - min(advware_count, (G - 1) * H) + min(promotion_count, (current_page - 1) * B) - min(promotion_count, (G - 1) * B)
else:
if G == current_page:
I = prev_start
else:
I = next_start + (G - current_page - 1) * E - min(advware_count, (G - 1) * H) + min(advware_count, current_page * H) - min(promotion_count, (G - 1) * B) + min(promotion_count,current_page * B)
return "Search?" + base_url + "&page=" + str(G) + "&s=" + str(I) + "&click=0"
# 针对有赖加载的京东页面
def get_url2(page_num, page_param):
url = "https://search.jd.com/"
page_url = url + page_param
headers = {
'authority': 'search.jd.com',
'method': 'GET',
'path': '/' + page_param,
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; xtest=5565.cf6b6759; qrsc=3; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; user-key=2255241e-ef8a-41f1-870a-e532de675198; cn=0; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; __jdu=1342884474; _gcl_au=1.1.1673204888.1573896089; mt_xid=V2_52007VwMQV15RW18aTxxsVTcAQVJVWFZGFhkfVBliUUJSQVFaCk9VGVkBYlZBAA9bUV9MeRpdBW8fElJBWFtLH0kSXw1sARBiX2hSahZMGV8GZQMVVm1YVF4b; __jda=122270672.1342884474.1568857058.1574066075.1574068886.45; __jdc=122270672; shshshfp=a5cbf838eea824c782a9a7a3809e73ef; rkv=V0500; __jdb=122270672.5.1342884474|45.1574068886; shshshsID=77f49fee8b3efadff885bbb99a9693ef_4_1574070380090',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(page_url, headers=headers)
html = response.content.decode('utf-8')
htmls = etree.HTML(html)
url_list = []
for i in htmls.xpath('//div[@class="p-img"]/a/@href'):
if 'https' in i:
url_list.append(i)
else:
url_list.append('https:' + i)
init_param, base_url = get_params(html)
scroll_param = scroll(init_param, html, base_url)
scroll_url = url + scroll_param
headers = {
'authority': 'search.jd.com',
'method': 'GET',
'path': '/' + scroll_param,
'scheme': 'https',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; xtest=5565.cf6b6759; qrsc=3; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; user-key=2255241e-ef8a-41f1-870a-e532de675198; cn=0; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; __jdu=1342884474; shshshfp=a5cbf838eea824c782a9a7a3809e73ef; __jda=122270672.1342884474.1568857058.1573810050.1573882929.36; __jdc=122270672; rkv=V0500; __jdb=122270672.2.1342884474|36.1573882929; shshshsID=3dd9131907c755c9afd6391d2b1e7c01_2_1573882940497',
'referer': page_url,
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
response = requests.get(scroll_url, headers=headers)
html = response.content.decode('utf-8')
htmls = etree.HTML(html)
for i in htmls.xpath('//div[@class="p-img"]/a/@href'):
if 'https' in i:
url_list.append(i)
else:
url_list.append('https:' + i)
new_page_param = page(page_num + 2, init_param, base_url)
return [url_list, new_page_param]
if __name__ == '__main__':
lazy = True #是否存在赖加载
t = 1
t = 1
url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=s%27ji&pvid=f9e2418651b647d28bdee9eaf3e7d6da"
for i in range(1, 100 * 2, 2):
print(i)
if lazy: # 存在赖加载就使用get_url2,否则使用get_url
url_list, page_param = get_url2(i, url.split('/')[-1]) if i == 1 else get_url2(i, page_param)
else:
url_list = get_url(url, i) if i == 1 else get_url(url, i - t)
t = t + 1
for url in url_list:
print(get_message(url))