【技术分享】BERT系列(二)-- BERT在序列标注上的应用
本文原作者:梁源,经授权后发布。
原文链接:https://cloud.tencent.com/developer/article/1454904
序列标注是NLP中一项重要的任务,它主要包括分词,词性标注,命名实体识别等子任务。通过对预训练后的BERT模型进 行finetune,并与CRF进行结合,可以很好地解决序列标注问题。上篇文章对BERT官方源码进行了介绍,本篇文章将介绍 如何通过BERT解决序列标注问题。同时本篇文章将BERT+CRF模型与其他模型进行了对比,并且对BERT在序列标注上任务上存在的问题进行了分析。
1. 序列标注简介
所谓序列标注,就是对一个一维线性输入序列,给线性序列中的每个元素打上标签集合中的某个标签。所以,其本质上是对线性序列中每个元素根据上下文进行分类的问题。 中文的序列标注问题,往往可以把一个汉字看做线性序列的一个元素,而不同任务其标签集合代表的含义可能不太相同,但是相同的问题都是:如何根据汉字的上下文给汉字打上一个合适的标签。无论是分词,还是词性标注,或者是命名实体标注,道理都是相通的。 在深度学习流行起来之前,常见的序列标注问题的解决方案都是借助HMM模型,最大熵模型,CRF模型。尤其是CRF,它是解决序列标注问题的主流方法。随着深度学习的发展,RNN在序列标注问题上取得了巨大的成功,Bi-LSTM+CRF模型,在该任务上表现的十分出色。但是当我们把Bi-LSTM升级为BERT,在序列标注上的准确率和训练效率上都达到了新的高度。同时发现,BERT+CRF模型可以同时解决中文分词和词性标注两个任务,下面我们就通过这两个子任务分析BERT在序列标注上的应用。
2. BERT+CRF 模型原理
BERT通过”Fill in the blank task” 以及 “Next sentence prediction” 两个任务进行预训练。在预训练模型的基础上稍加修改就可以处理多个下游任务。如下图所示,中文文本的序列标注问题,每个序列的第一个token始终是特殊分类嵌入([CLS]),剩下的每一个token代表一个汉字。BERT的input embeddings 是token embeddings, segmentation embeddings 和position embeddings的总和。其中token embeddings是词(字)向量,segment embeddings 用来区分两种句子,只有一个句子的任务(如序列标注),可以用来区分真正的句子以及句子padding的内容,而position embedding保留了每个token的位置信息。BERT的output 是每个token的encoding vector。只需要在BERT的基础上增加一层全连接层并确定全连接层的输出维度,便可把embedding vector映射到标集合。词性标注问题的标签集合即中文中所有词性的集合。


BERT模型+FC layer(全连接层)已经可以解决序列标注问题,以词性标注为例,BERT的encoding vector通过FC layer映射到标签集合后,单个token的output vector再经过Softmax处理,每一维度的数值就表示该token的词性为某一词性的概率。基于此数据便可计算loss并训练模型。但根据Bi-LSTM+CRF 模型的启发,我们在BERT+FC layer 的基础上增加CRF layer。 CRF是一种经典的概率图模型,具体数学原理不在此处展开。要声明的是,CRF层可以加入一些约束来保证最终的预测结果是有效的。这些约束可以在训练数据时被CRF层自动学习得到。具体的约束条件我们会在后面提及。有了这些有用的约束,错误的预测序列会大大减小。
3. BERT+CRF 模型工作流程
我们以词性标注为例具体讲解工作流程。
3.1 数据集
在词性标注任务中,主要采用1998年人民日报标注预料库(PRF)。该数据集共有19438条数据,格式如下图所示:“__label__” 为分隔符,分隔符的左侧为文本信息,右侧为标注的词性信息。根据6:2:2的比例将数据集分为train, eval 以及 test dataset。
![]()
3.2 数据预处理
在英文文本中单词为最小单位,且每个单词均有一一对应的词性信息,所以无需过多的预处理。但对中文文本,BERT模型的最小输入单位为单个汉字, 但是词性信息是根据词语进行标注的,为了满足BERT的要求,我们需要对数据进行预处理,将原文本拆分成一系列的汉字,并对每个汉字进行词性标注。这种分词处理有多种体系,这里使用 ”BIO“,其中 “B” 表示该汉字是词汇开始字符,同时也可以表示单字词;“I” 表示该汉字是词汇的中间字符;“O” 表示该汉字不在词汇当中。”O” 在词性标注任务当中不会出现,但是在命名实体标注中有意义。经过预处理后的数据如下图所示。此外根据BERT模型的要求,需要预先设定最大序列长度(max_seq_length),根据此参数对序列进行padding。
![]()
3.3 模型训练
3.3.1算法参数介绍
- bert_dir :预训练模型的存放路径,其中包括的重要数据有:
- vocab.txt: 提供的词表用于输入数据的token embedding 的查找。
- bert_config.json: 提供预训练模型的配置信息
- init_checkpoint: 预训练模型的checkpoint
- max_seq_length: 最大序列长度,长度小于该值得序列将进行padding处理,大于该值得序列将进行截断
- num_epochs: 训练的epoch数
- learning_rate: 学习率
3.3.2 其他细节介绍
- 在进行数据分割的时候, 要保证所有词性标签在训练数据(training dataset) 中均有出现,否则未出现标签同样不会出在后续的预测当中。
- 需要将vocab.txt中不包括,但是出现在数据集中的汉字用 [UNK] 来替换,否则在训练过程中因无法获得token embedding信息而报错。
3.4 模型预测
同模型训练一样,待预测的句子需要被拆分为一系列单字后输入到训练好的模型当中,模型的输出为每一个单字对应的预测词性。因为这种形式不方便人来查看,所以增加一个后处理的步骤, 把B开头,后面跟着I的汉字拼接在一起,直到碰见下一个B标签位置,这样就等于分出了一个单词词语。整个预测流程如下图所示:

在第二章节提到过增加的CRF层可以学习到一些约束,这些约束可能有:
- 句子的开头应该是 ”B-“, 而不是“I-”。
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-n I-n” 是正确的,而“B-n I-v”则是错误的,同时“I-n I-v”也是错误的。
在训练数据足够大的时候,CRF层可以更好的学习到这些约束,但是无法保证在预测时不出错,因为在模型预测的后处理环节,同样需要考虑上述约束,不符合约束的token,以“ERROR” 来代替预测结果。如下图所示:
![]()
4. 模型比较及分析
4.1 模型比较
为了展示出BERT+CRF的优势,我们将其与CRF, Bi-LSTM+CRF进行比较,模型训练均采用单块Tesla P40。获得如下结果:

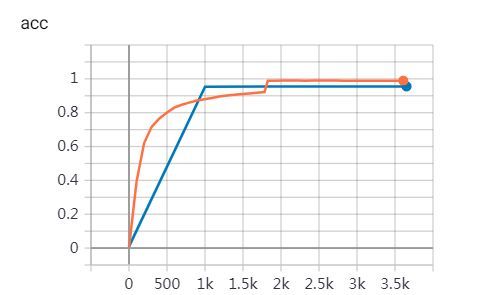
我们将以上5种模型进行比较,其中embedding的意思是input token使用预训练好的word embedding。可以看出BERT+CRF模型的正确率最高,相较于BERT-LSTM+CRF主流模型,提升了51.8%,训练用时缩短了78%。当我们查看准确率曲线时不难发现,完成一个epoch后,eval数据集的准确率已经超过90%,可见BERT+CRF模型的训练效率和表现均十分出色。
4.2 优缺点分析
优点
- Google官方提供了包括不同语种及不同尺寸的多个版本的预训练模型,极大的适应了下游任务,并节约了训练成本。
- BERT+CRF 相较于其他模型训练速度更快,准确率更高。可以很好地胜任中文文本的序列标注任务。
- 模型可以同时完成多任务:从上述例子可以看出,模型在处理词性标注任务的同时, 也解决了中文分词的任务,一举两得。
缺点
- 必须设置max_seq_length参数。对BERT来讲,我们需要预先确定max_seq_length参数,未达到此长度的数据将做padding处理,而超过此长度的数据将被截断, 造成信息丢失。这一点上不及Bi-LSTM灵活。
- 对硬件要求高。训练模型会占用较大的显存,尤其是为了适应文本增大max_seq_length时,显存占用会进一步加大,因此可能会增加预处理工作,比如预先对训练及预测文本进行分割,从而约束最大长度。
- 评价指标难以计算。对于词性标注任务,目前只能计算和比较字级别(token level)的准确率。但是当根据约束条件将字合并成词后,由于存在 ”ERROR“ 标签,合成词后的序列同原始序列相比会发生错位,导致词级别(term level)的评价指标难以计算。这是中文文本词性标注的问题的通病,同样存在于其他模型上,需要进一步研究解决方法。
5. 总结
BERT是一个十分强大的NLP模型,BERT+CRF 可以高质量的完成序列标注任务。目前该模块已经成功部署到最新版本的腾讯智能钛平台上,有兴趣的同学可以在平台上搭建自己的模型进行训练和预测。我们希望听到你们宝贵的意见和建议。谢谢阅读。
系列文章传送门
腾讯智能钛机器学习平台:【技术分享】BERT系列(一)——BERT源码分析及使用方法zhuanlan.zhihu.com
更多优质技术文章请关注官方微信公众号:

长按/扫描关注我们
专业AI开发者社区,期待您的光临!
智能钛AI开发者 - 云+社区 - 腾讯云cloud.tencent.com