【MySQL】3.表操作-表联结
MySQL基础-表操作-表联结
文章目录
- MySQL基础-表操作-表联结
- 表操作
- 创建表
- 更新表
- 删除表
- 插入数据
- 从一个表复制到另一个表
- 更新数据
- 删除数据
- 组合查询
- 使用子查询
- 表联结
- 创建联结
- 内联结、INNER JOIN
- 创建高级联结
- 自联结(self-join)
- 自然联结(natural join)
- 外联结(outer join)
- 作业
表操作
创建表
create table 表名(列名1 数据类型,
列名2 数据类型,
···)
-
使用NULL值
每个表列要么是null列,要么是not NULL列:
CREATE TABLE Orders
(
order_num INTEGER NOT NULL, -- 用逗号隔开
order_date DATETIME NOT NULL,
quantity INTEGER NOT NULL DEFAULT 1, -- 指定默认值
cust_id CHAR(10) NOT NULL
);
-
指定默认值
在插入行时如果不给出值,DBMS将自动采用默认值,用DEFAULT指定。
更新表
ALTER TABLE 要更改的表名 操作;
给已有表增加列:
ALTER TABLE Vendors
ADD vend_phone CHAR(20);
删除表
DROP TABLE CustCopy; -- 删除整个表
插入数据
INSERT用来将行插入(或添加)到数据库表,插入有几种方式:
- 插入完整的行
INSERT INTO Customers
VALUES('1000000006', -- 存储在列中的数据在values子句中给出,必须每列一个值
'Toy Land',
'123 Any Street',
NULL); -- 如果某列没有值,使用NULL值
上面的SQL语句高度依赖与表中列的定义次序,还依赖于其容易获得的次序信息。但有时表结构变动后并不能保持完全相同的次序,因此这种语法是很不安全的。下面这种方式是更为安全的做法:
INSERT INTO Customers(cust_id,
cust_name,
cust_address,
cust_city)
VALUES('1000000006',
'Toy Land',
'123 Any Street',
'New York');
一条语句插入多行:
insert into persons
(id_p, lastname , firstName, city )
values
(200,'haha' , 'deng' , 'shenzhen'),
(201,'haha2' , 'deng' , 'GD'),
(202,'haha3' , 'deng' , 'Beijing');
- 插入部分行
利用上述方法还可以只给某些列提供值,给其他列不提供值。
- 插入检索出的数据
利用它将SELECT语句的结果插入表中,由一条INSERT语句和一条SELECT语句组成。假如想把另一表的顾客合并到customers表中:
INSERT INTO Customers(cust_id,
cust_contact,
cust_email,
cust_name)
SELECT cust_id,
cust_contact,
cust_email,
cust_name)
FROM CustNew;
insert通常只能插入一行,而insert select是个例外,它可以用一条insert插入多行。
从一个表复制到另一个表
这种数据插入不适用insert语句,使用select into语句将数据复制到一个新表。
SELECT * -- 使用*,填充相同的列,如果只想复制部分的列,可以明确给出列名
INTO CustCopy -- 创建一个名为custcopy的新表
FROM Customers;
MariaDB、MySQL、Oracle、PostgreSQL 和 SQLite 使用的语法稍有不同:
CREATE TABLE CustCopy AS
SELECT * FROM Customers;
更新数据
基本的UPDATE语句由三部分组成:要更新的表、列名和他们的新值、确定要更新哪些行的过滤条件
客户 1000000005 现在有了电子邮件地址,因此他的记录需要更新,语句如下:
UPDATE Customers
SET cust_contact = 'Sam Roberts', -- SET 命令用来将新值赋给被更新的列
cust_email = '[email protected]' -- 更新多个列只需要一条set语句
WHERE cust_id = '1000000005';
要删除某个列的值,可以设置它为NULL:
UPDATE Customers
SET cust_email = NULL
WHERE cust_id = '1000000005';
删除数据
使用delete语句删除数据,两种方式:1. 从表中删除特定的行;2. 从表中删除所有行。要删除指定的列,使用update语句。
DELETE FROM Customers
WHERE cust_id = '1000000006';
组合查询
-
并(union)或复合查询:SQL允许执行多个查询(多条SELECT语句),并将结果作为一个查询结果集返回。
使用组合查询的情况:
-
在一个查询中从不同的表返回数据;
-
对一个表执行多个查询,按一个查询返回数据。
创建UNION涉及编写多条SELECT语句,首先来看单条语句:
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI');

SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All';
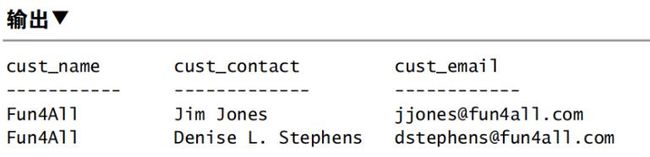
组合这两条语句:
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All';
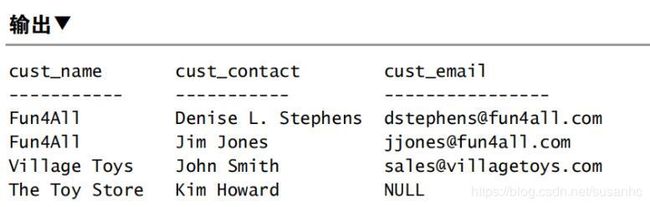
注意:union中的每个查询必须包含相同的列、表达式或聚集函数。
-
包含或取消重复的行
从上面的例子可以看出,union取消了重复的行。如果要包含所有的行,则应当使用UNION ALL:
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION ALL
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All';
这样输出就是5行了。
-
对组合查询结果排序
union组合查询,只能使用一条ORDER BY子句,必须位于最后一条SELECT子句之后。
使用子查询
SQL还允许创建子查询,即嵌套在其他查询中的查询。
-
利用子查询进行过滤
SELECT cust_id FROM Orders WHERE order_num IN (SELECT order_num FROM OrderItems WHERE prod_id = 'RGAN01');子查询总是从内向外处理。
注意:作为子查询的SELECT语句只能查询单个列。
-
作为计算字段使用子查询
SELECT cust_name, cust_state, (SELECT COUNT(*) FROM Orders WHERE Orders.cust_id = Customers.cust_id) AS orders FROM Customers ORDER BY cust_name;
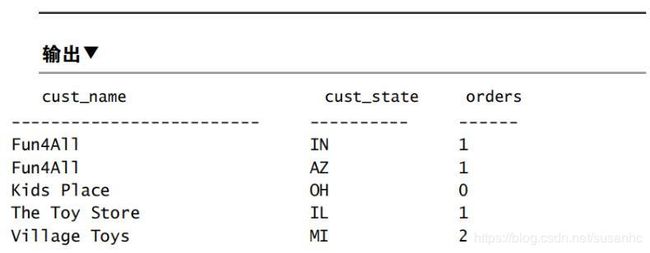
子查询中的where子句与前面使用的where子句稍有不同,它使用了完全限定名,而不只是列名。指定表名和列名(Orders.cust_id 、Customers.cust_id)上面的where子句表明:比较Orders表中的cust_id和当前正从Customers表中检索的cust_id。
用一个句点分割表名和列名,在有可能混淆表名和列名时必须这样做。在这个例子中,有两个cust_id列:一个在Customers中,另一个在Orders中。如果不采用完全限定名,DBMS会认为要对orders表中的cust_id自身进行比较。
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM Orders
WHERE cust_id = cust_id) AS orders
FROM Customers
ORDER BY cust_name;
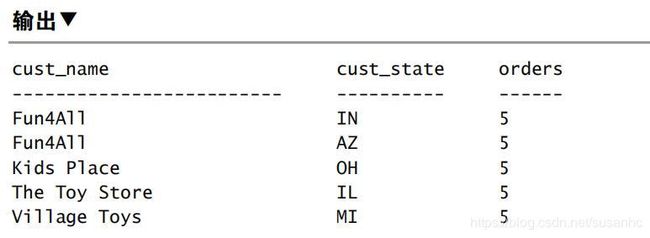
表联结
-
关系表
相同的数据出现多次决不是一件好事,这是关系数据库设计的基础。关系表的设计就是要把信息分解成多个表,一类数据一个表。各表通过某些共同的值互相关联(所以才叫关系数据库)。
-
使用联结
如果数据存储在多个表中,使用联结用一条 SELECT 语句就检索出数据。
创建联结
指定要联结的所有表以及关联它们的方式即可。
SELECT vend_name, prod_name, prod_price
FROM Vendors, Products -- 列出来两个表
WHERE Vendors.vend_id = Products.vend_id;
-
笛卡尔积
由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
内联结、INNER JOIN
基于两个表之间的相等测试,被称为内联结。可以对这种联结使用稍微不同的语法,明确指定联结的类型。
SELECT vend_name, prod_name, prod_price
FROM Vendors INNER JOIN Products
ON Vendors.vend_id = Products.vend_id;
这条语句和上边的where语句输出数据一样。两个表之间的关系是以 INNER JOIN 指定的部分 FROM 子句。联结条件用特定的 ON 子句而不是 WHERE 子句给出。
-
联结多个表
SELECT prod_name, vend_name, prod_price, quantity FROM OrderItems, Products, Vendors WHERE Products.vend_id = Vendors.vend_id AND OrderItems.prod_id = Products.prod_id AND order_num = 20007;
创建高级联结
-
使用别名
SELECT cust_name, cust_contact FROM Customers AS C, Orders AS O, OrderItems AS OI -- 三个表各自设置一个别名 WHERE C.cust_id = O.cust_id AND OI.order_num = O.order_num AND prod_id = 'RGAN01'
自联结(self-join)
自联结通常作为外部语句,用来替代从相同的表中检索数据的使用子查询的语句。下面看一个例子:给Jim jones同一公司的所有顾客发送一封邮件:
SELECT cust_id, cust_name, cust_contact
FROM Customers
WHERE cust_name = (SELECT cust_name
FROM Customers
WHERE cust_contact = 'Jim Jones');
采用自联结:
SELECT c1.cust_id, c1.cust_name, c1.cust_contact -- 使用c1前缀给出列的全名,否则不知道是那个列
FROM Customers AS c1, Customers AS c2 -- 同一个表使用两个别名
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'Jim Jones';
自然联结(natural join)
对表进行联结,应该至少有一列不止出现在一个表中。标准的联结返回所有数据,相同的列甚至多次出现。自然联结排除多次出现,使每一列只返回一次。
自然联结要求你只能选择那些唯一的列,一般通过对一个表使用通配符(select*),而对其他表的列使用明确的子集来完成。
SELECT C.*, O.order_num, O.order_date,
OI.prod_id, OI.quantity, OI.item_price
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01';
通配符只对第一个表使用,所有其他列明确列出,所以没有重复的列被检索出来。
外联结(outer join)
许多联结将一个表中的行与另一个表中的行相关联,但有时候需要包含没有关联行的那些行。例如要完成以下工作:
- 对每个顾客下的订单进行计数,包括那些至今尚未下订单的顾客;
- 列出所有产品以及订购数量,包括没有人订购的产品;
- 计算平均销售规模,包括那些至少尚未下订单的顾客。
要检索包括没有订单顾客在内的所有顾客,可如下进行:
SELECT Customers.cust_id, Orders.order_num
FROM Customers LEFT OUTER JOIN Orders
ON Customers.cust_id = Orders.cust_id;
与内联结关联两个表中的行不同的是,外联结还包括没有关联行的行。必须使用RIGHT 或LEFT关键字——RIGHT指的是OUTER JOIN右边的表,LEFT指的是OUTER JOIN左边的表。
全外连结(FULL OUTER JOIN):检索两个表中的所有行并关联那些可以关联的行。
作业
项目五:组合两张表 (难度:简单)
在数据库中创建表1和表2,并各插入三行数据(自己造)
表1: Person
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
±------------±--------+
PersonId 是上表主键
表2: Address
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
±------------±--------+
AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:FirstName, LastName, City, State
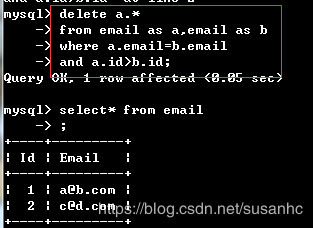
项目六:删除重复的邮箱(难度:简单)
编写一个 SQL 查询,来删除 email 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
±—±--------+
| Id | Email |
±—±--------+
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
±—±--------+
Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Person表应返回以下几行:
±—±-----------------+
| Id | Email |
±—±-----------------+
| 1 | [email protected] |
| 2 | [email protected] |
±—±-----------------+