机器学习实战+统计学习方法之理解KNN(1.实战代码的详细走读和解析)
机器学习实战2.2.1:实施KNN算法
# the program is general from 2.1.2~
#_init_py is described is a 构造函数 constructed function
'''
wrong things:
1.gourp [ [],[] ] in the outermost the []
2.dataSet.shape[0] is [] not ()
3.the functions which have to be used should be defined in front
'''
from numpy import *
import operator
def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #array,其实也是一个Tuple(元组),Tuple是不可变的List
#group=array[[[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]]
labels=['A','A','B','B'] #List
return group,labels
#KNN
def classify0(inX,dataSet,labels,k):#inX is non-classify data, dataSet has dataSetSize training data
dataSetSize=dataSet.shape[0] # just get the length of first dimension of the matrix #the shape() comes from numpy
diffMat=tile(inX, (dataSetSize,1))-dataSet # the tile() is comes from numpy, tile(A,reps) the A is input array and reps is the number that a repeat itself in every dimension
#eg. A=[1,2] then tile(A,2)=[1,2,1,2] tile(A,(2,3))=[[1,2,1,2,1,2],[1,2,1,2,1,2]] tile(A,(2,2,3))=[[[1,2,1,2,1,2][1,2,1,2,1,2]][[1,2,1,2,1,2][1,2,1,2,1,2]]]
#that's to say, the ahead number is described the high dimension
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1) #sum(array,axis=0) or sum(axis=1) axis=0 为普通相加,axis=1 为矩阵的每一行向量相加
distances=sqDistances**0.5
sortDistIndicies=distances.argsort()
#argsort(a, axis=-1, kind='quicksort', order=None) Returns the indices that would sort an array
#Perform an indirect sort along the given axis using the algorithm specified by the `kind` keyword. It returns an array of indices of the same shape as `a` that index data along the given axis in sorted order.
#eg1. x=[3,1,2] then x.argsort()=[1,2,0] (位置上对应的数为:1,2,3) eg2.x=[[0,3],[2,2]] x.argsort(x,axis=0)=[[0,1],[1,0]]#按列进行排序
#argsort()默认是升序排序,如果想实现降序只需要将a-->-a,注意返回的是索引,而不是值,如果想到得到值那就x[x.argsort()]=x[1,2,0]=[1,2,3]
classCount={}#字典
for i in range(k):#eg1. range(3)=[0,1,2] (带表从0到3,不包括3的数组) eg2. range(1,5)=[1,2,3,4](从1到5,不包括5) eg3.range(1,5,2)=[1,3](从1到5,不包括5,间隔为2)
voteIlabel=labels[sortDistIndicies[i]]#也就是距离inX近的前k个的标签值
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1 #dict.get(key, default=None),默认值大法好,比JAVA的HashMap好用,也就是如果没有这个key值,那我的默认值就是0
sortClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#按照key排序: sorted(dict.items(), key=lambda d: d[0]); 按照value排序 :sorted(dict.items(), key=lambda d: d[1]) 这是lambda表达式,在JDK1.8中也新增加了lambda表达式
#JAVA中的lambda表达式 Collections.sort(names, (o1, o2) -> o1.startsWith("N") && !o2.startsWith("N") ? -1 : 1); lambda在JDK1.8中代表匿名类的意思,可以用()->{}代表匿名类
#对于程序中的这个(来自于官方3.4的文档):sorted(iterable[, key][, reverse]) Return a new sorted list from the items in iterable。reverse is a boolean value. If set to True, then the list elements are sorted as if each comparison were reversed.
#来自于网络,是我打开的方式不对? sorted(iterable, cmp=None, key=None, reverse=False) --> new sorted list
#其中: iterable:是可迭代类型 cmp:用于比较的函数,比较什么由key决定(是一个函数)key:用列表元素的某个属性或函数进行作为关键字,有默认值,迭代集合中的一项
#reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,有默认值 返回值:是一个经过排序的可迭代类型,与iterable一样
return sortClassCount[0][0]
[g,l]=createDataSet()
result=classify0([1.2,1.5], g, l, 3)
print(result)机器学习实战2.2:使用KNN算法改进约会网站的速配对效果
生成的3个图分别是:
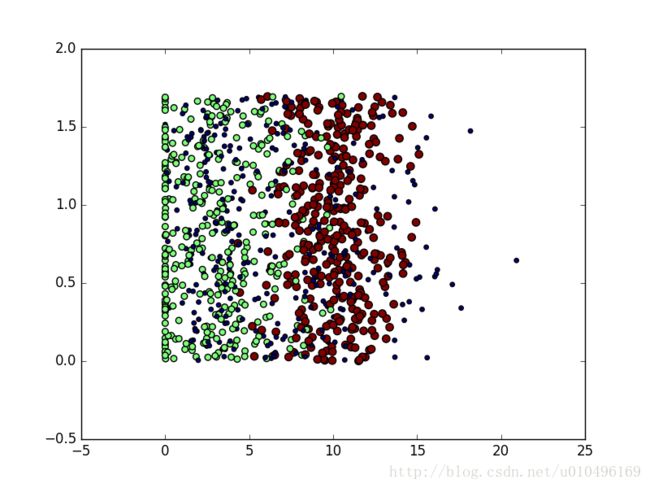
图2.4
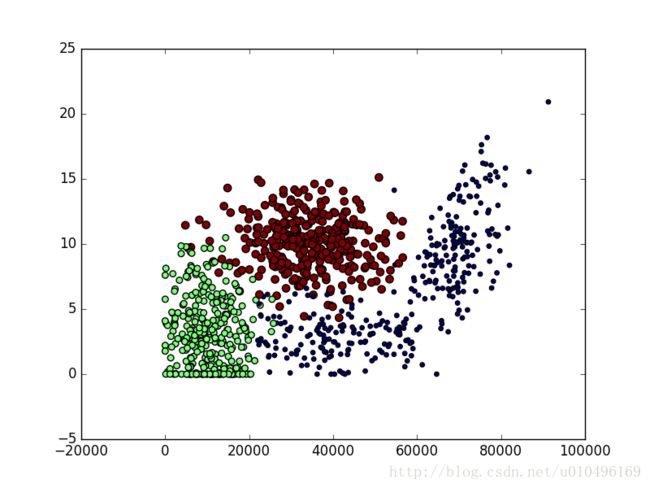
对应书上的图2.5
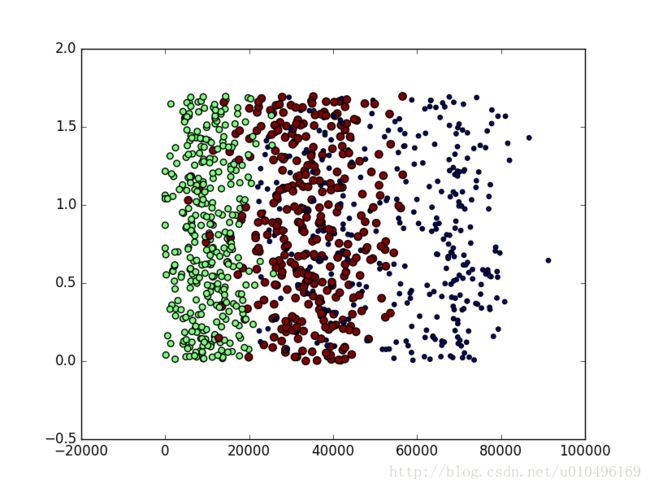
用第一列和第3列数据生成的图
#case2.2 使用KNN改进约会网站的配对效果
from asyncore import write
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
#read File
def file2matrix(filename):
fr=open(filename) #read file and return a 句柄 open(fn,mode) mode=='r':read mode=='w':write
arrayOLines=fr.readlines()
numberOfLines=len(arrayOLines) #len和shape的比较在que0409
returnMat=zeros((numberOfLines,3)) #创建多维的零数组比matlab 多了一层括号呐,不过创建一维的简单了直接zeros(num)
classLabelVector=[] #这是矩阵的意思
index=0
for line in arrayOLines:
line=line.strip() #截取回车字符,此时还是字符串
#这个地方是strip()啊,不是split(),如果用错了将会导致后面的split()不可用,因为List没有split()方法
#str.strip(rm)
#s为字符串,rm为要删除的字符序列
#s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符
#s.lstrip(rm) 删除s字符串中开头处,位于 rm删除序列的字符
#s.rstrip(rm) 删除s字符串中结尾处,位于 rm删除序列的字符
#当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')
#这里的rm删除序列是只要边(开头或结尾)上的字符在删除序列内,就删除掉,也就是不管顺序 测试在que0409
listFromLine=line.split('\t') #用tab字符将上衣得到的一个整行数据分割成一个元素列表
#split(str,num)[n]:
#str:表示为分隔符,默认为空格,但是不能为空('')。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
#经过测验,默认是空格和回车,测验在que0409
#num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
#[n]:表示选取第n个分片
#当split()里面有参数的时候就变的比较好玩了
returnMat[index,:]=listFromLine[0:3] #好像matlab,直接上例子 aa=[1,2,3,4] aa[0:3]=[1,2,3] 也就是从0到3,不包括3
classLabelVector.append(int(listFromLine[-1])) #-1表示列表的最后一列元素
index+=1
return returnMat,classLabelVector
[datingDataMat,datingLabels]=file2matrix('E:/研究生阶段/我在搞科研的路上频频回头/三管齐下的研二下/My Programe/MeLearnaBettel/Ch02/Data/datingTestSet2.txt')
#明明应该是数据集2好嘛。。⊙﹏⊙b汗
#[returnMat,classLabelVector]=file2matrix('datingTestSet.txt') # 我相对路径怎么不管用啊,尴尬了
# for x in datingLabels[0:20]:
# print(x)
# #fig=plt.figimage()
# fig=plt.figure() #默认为图表1
# #ax=fig.add_subplot(111)
# #as=plt.subplot(111) #在图表1中添加子图1,因为在这里我们只需要一个图,所以这个没有必要
# #plt.plot(datingDataMat[:,1],datingDataMat[:,2]) #这个画出来不是散点图,都是连着线的
# #plt.scatter(datingDataMat[:,1],datingDataMat[:,2]) #画出的是散点图
# plt.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels)) #色彩不等,尺寸不同的散点图
# plt.show()
# #ax=plt.subplot(211)
#plt.scatter(x, y, s=20, c='b', marker='o', cmap=None, \
# norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=Node,\
# edgecolors(应该是3.X新加的?好奇怪散点图为什么有这个选项,先不去管他), hold=Node, data)
#像题中这样在scatter(x,y,array(s),array(c))里面有array的使用方法:当s和x同大小时,表示x中的每个点对应s中的一个大小,c表是颜色,
#因为例子中只有3种不同的labels,所以图中也就有了3种不同的大小和颜色,至于为什么乘以了15,是因为这时候看出的大小和颜色比较顺眼
#接下来把书上讲到的,没讲到的图都画出来吧,其中figure(1)是图2.4, figure(2)对应书中的图2.5 ,figure(3)书上没有是用列1和列3的数据做判断的
fig=plt.figure(3)
# ax1=fig.add_subplot(111) #2.4
# ax2=fig.add_subplot(112) #2.5
# ax3=fig.add_subplot(113) #第1和3列
#ValueError: num must be 1 <= num <= 1, not 2 ,错误的原因是(111)代表了,我这里只能有一个图,所以自然不可以有第二个子图
fig=plt.figure(3) #figure(num) 中 num 的含义是图的数量
ax1=plt.subplot(311) #这样的话和matlab中的绘图还是比较像的,我这里有3个图,该子图在第一列的第一行
ax2=plt.subplot(312) #第一列的第二行
ax3=plt.subplot(313)
ax1.set_title("图2.4") #不能显示汉字。。。改改编码就可以了,不调了
plt.sca(ax1)
plt.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
plt.sca(ax2)
plt.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels))
plt.sca(ax3)
plt.scatter(datingDataMat[:,0],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
#一下的代码也可以
# fig=plt.figure(1)
# fig=plt.figure(2)
# fig=plt.figure(3)
# plt.figure(1)
# plt.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
# plt.figure(2)
# plt.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels))
# plt.figure(3)
# plt.scatter(datingDataMat[:,0],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()