前言
本文主要更新部分常见的Ceph OSD相关故障处理。
1.osdmap解析失败,导致osd启动失败
a.故障现象
2019-04-15 18:47:52.985665 7ff10b6c2800 10 osd.66 pg_epoch: 671640 pg[1.462a( v 671616'286461 lc 667530'286361 (66710
2'283292,671616'286461] local-les=671640 n=3485 ec=28764 les/c/f 671630/671165/0 671632/671634/671634) [66,75]/[66,104] r=0 lpr=671640 pi=665415-671633/18 crt=671616'286461 lcod 0'0 mlcod 0'0 inactive NIBBLEWISE m=33] Not blocking outgoing recovery messages -4> 2019-04-15 18:47:52.985676 7ff10b6c2800 10 osd.66 671649 load_pgs loaded pg[1.462a( v 671616'286461 lc 667530'286361
(667102'283292,671616'286461] local-les=671640 n=3485 ec=28764 les/c/f 671630/671165/0 671632/671634/671634) [66,75]/[66,104] r=0 lpr=671640 pi=665415-671633/18 crt=671616'286461 lcod 0'0 mlcod 0'0 inactive NIBBLEWISE m=33] log((667102'283292,671616'286461], crt=671616'286461) -3> 2019-04-15 18:47:52.985870 7ff10b6c2800 10 osd.66 671649 pgid 1.6303 coll 1.6303_head
2019-04-15 18:47:52.985984 7ff10b6c2800 20 osd.66 0 get_map 671651 - loading and decoding 0x7ff0cf3a2080
2019-04-15 18:47:52.986030 7ff10b6c2800 10 osd.66 0 add_map_bl 671651 0 bytes
2019-04-15 18:47:52.989844 7ff10b6c2800 -1 *** Caught signal (Aborted) **
in thread 7ff10b6c2800 thread_name:ceph-osd
ceph version 10.2.0 (3a9fba20ec743699b69bd0181dd6c54dc01c64b9)
1: (()+0x8e4fd2) [0x55c3b4a80fd2]
2: (()+0xf100) [0x7ff10a069100]
3: (gsignal()+0x37) [0x7ff10862c5f7]
4: (abort()+0x148) [0x7ff10862dce8]
5: (__gnu_cxx::__verbose_terminate_handler()+0x165) [0x7ff108f309d5]
6: (()+0x5e946) [0x7ff108f2e946]
7: (()+0x5e973) [0x7ff108f2e973]
8: (()+0x5eb93) [0x7ff108f2eb93]
9: (()+0x9e8d85) [0x55c3b4b84d85]
10: (OSDMap::decode(ceph::buffer::list::iterator&)+0x6d) [0x55c3b4b3aefd]
11: (OSDMap::decode(ceph::buffer::list&)+0x1e) [0x55c3b4b3c1de]
12: (OSDService::try_get_map(unsigned int)+0x45b) [0x55c3b45273ab]
13: (OSD::load_pgs()+0x12bc) [0x55c3b452b33c]
14: (OSD::init()+0x1f74) [0x55c3b453d0c4]
15: (main()+0x29d1) [0x55c3b44a4bf1]
16: (__libc_start_main()+0xf5) [0x7ff108618b15]b.故障分析
日志里面看到osd在解析osdmap 671651这个epoch的时候报错。
c.解决方法
到这个osd的数据目录下find找下这个epoch的osdmap所在目录:
[root@host10 osd]# find ceph-66/* -name "*671652*"
ceph-66/current/meta/DIR_4/DIR_1/DIR_E/osdmap.671652__0_C85F4E14__none
ceph-66/current/meta/DIR_B/DIR_4/DIR_1/inc\uosdmap.671652__0_10EC614B__none然后到其他正常的osd的数据目录下找到这个epoch的osdmap:
[root@host10 osd]# find ceph-26/* -name "*671652*"
ceph-26/current/meta/DIR_4/DIR_1/DIR_E/osdmap.671652__0_C85F4E14__none
ceph-26/current/meta/DIR_B/DIR_4/DIR_1/inc\uosdmap.671652__0_10EC614B__none最后cp正常的osd的osdmap去覆盖出问题的osd的osdmap,然后启动可以正常启动osd了。
2.osdmap内存占用过大,导致osd进程起不来
a.故障现象
osd进程启动不成功,dmesg可以看到类似下面的输出:
Jan 5 16:01:28 ceph02 kernel: [171428.546446] Out of memory: Kill process 6712 (ceph-osd) score 36 or sacrifice child
Jan 5 16:01:28 ceph02 kernel: [171428.546669] Killed process 6712 (ceph-osd) total-vm:1700052kB, anon-rss:822856kB, file-rss:14048kb.故障分析
当时的操作是将一个down机很久的机器启动,但是该主机上的osd节点epoch和当前epoch相差2w左右,导致osdmap过多而占用内存过大,从而被OS杀掉。
c.解决方法
设置如下参数,降低内存中osdmap的数量
osd_map_cache_size = 20
osd_map_max_advance = 10
osd_mon_report_interval_min = 10
osd_pg_stat_report_interval_max = 10
paxos_service_trim_min = 10
mon_min_osdmap_epochs = 203.osdmap不存在,导致osd启动失败
a.故障现象
osd启动失败,查看osd日志,有以下关键信息:
7f3a77ce2800 0 osd.256 23801 crush map has features 2268850290688, adjusting msgr requires for clients
7f3a77ce2800 0 osd.256 23801 crush map has features 2543728197632 was 8705, adjusting msgr requires for mons
7f3a77ce2800 0 osd.256 23801 crush map has features 20135914242048, adjusting msgr requires for osds
7f3a77ce2800 0 osd.256 23801 load_pgs
7f3a77ce2800 -1 osd.256 23801 load_pgs: have pgid 0.18 at epoch 27601, but missing map. Crashing.
0> 2016-08-13 13:35:41.172996 7f3a77ce2800 -1 osd/OSD.cc: In function 'void OSD::load_pgs()' thread 7f3a77ce2800 time 2016-08-13 13:35:41.167042
osd/OSD.cc: 2840: FAILED assert(0 == "Missing map in load_pgs")
ceph version 6.0.0.s16-94 (762b8d4154bcb91d1bfcabcaf74e756d313596ab)
1: (OSD::load_pgs()+0x3616) [0x6749b6]
2: (OSD::init()+0x173e) [0x688dbe]
3: (main()+0x384f) [0x62f7ef]
4: (__libc_start_main()+0xfd) [0x33c901ed1d]
5: /usr/bin/ceph-osd() [0x62aef9]
NOTE: a copy of the executable, or `objdump -rdS ` is needed to interpret this. b.故障分析
根据堆栈信息可以看出,是在启动osd,加载pg时,读不到相应epoch的osdmap,从而导致osd崩溃。
c.解决方法
1.看下其他osd节点有没有这个epoch的osdmap,如果有,就从其他节点拷贝到/var/lib/ceph/osd/ceph-$osdid/current/meta下的相关目录。
如果没有,可以尝试下面的方法:
ceph osd getmap $epoch -o /tmp/osdmap.$epoch
osdmaptool --print /tmp/osdmap.$epoch
cp /tmp/osdmap.$epoch /var/lib/ceph/osd/ceph-$osdid/current/meta参见:1.osdmap解析失败,导致osd启动失败
4.osd journal读取失败,导致osd启动失败
a.故障现象
启动osd报错,日志如下:
2019-04-16 09:14:11.564612 7f0dd5287800 3 journal journal_replay: r = 0, op_seq now 52521981
2019-04-16 09:14:11.564642 7f0dd5287800 2 journal read_entry 3229810688 : seq 52521982 1099 bytes
2019-04-16 09:14:11.564649 7f0dd5287800 3 journal journal_replay: applying op seq 52521982
2019-04-16 09:14:11.567968 7f0dd5287800 3 journal journal_replay: r = 0, op_seq now 52521982
2019-04-16 09:14:11.572512 7f0dd5287800 2 journal read_entry 3229814784 : seq 52521983 4196212 bytes
2019-04-16 09:14:11.572523 7f0dd5287800 3 journal journal_replay: applying op seq 52521983
2019-04-16 09:14:11.614784 7f0dd5287800 3 journal journal_replay: r = 0, op_seq now 52521983
2019-04-16 09:14:11.615111 7f0dd5287800 2 journal read_entry 3234017280 : seq 52521984 1099 bytes
2019-04-16 09:14:11.615119 7f0dd5287800 3 journal journal_replay: applying op seq 52521984
2019-04-16 09:14:11.619353 7f0dd5287800 3 journal journal_replay: r = 0, op_seq now 52521984
2019-04-16 09:14:11.619370 7f0dd5287800 -1 journal Unable to read past sequence 52521985 but header indicates the jou
rnal has committed up through 52522295, journal is corrupt 0> 2019-04-16 09:14:11.622636 7f0dd5287800 -1 os/filestore/FileJournal.cc: In function 'bool FileJournal::read_entry(cep
h::bufferlist&, uint64_t&, bool*)' thread 7f0dd5287800 time 2019-04-16 09:14:11.619375os/filestore/FileJournal.cc: 2031: FAILED assert(0)
ceph version 10.2.0 (3a9fba20ec743699b69bd0181dd6c54dc01c64b9)
1: (ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x8b) [0x55e3dff0afab]
2: (FileJournal::read_entry(ceph::buffer::list&, unsigned long&, bool*)+0x8f1) [0x55e3dfcc5091]
3: (JournalingObjectStore::journal_replay(unsigned long)+0x1d5) [0x55e3dfc19f05]
4: (FileStore::mount()+0x3bf6) [0x55e3dfbf2346]
5: (OSD::init()+0x27d) [0x55e3df8ce3cd]
6: (main()+0x29d1) [0x55e3df837bf1]
7: (__libc_start_main()+0xf5) [0x7f0dd21ddb15]b.故障分析
osd日志里面看到因为osd在重放journal的时候无法读取52521985这个序号的journal,导致osd进程退出。
c.解决方法
方法一:把osd的journal_ignore_corruption参数设置为true后,osd启动成功。
方法二:删除journal分区,重新做journal,进行链接,启动osd服务;
方法三:修改 /var/lib/ceph/osd/ceph-25/current/commit_op_seq ,值大小大于105894263(报错日志中,has committed up through 105894263),这里设置105894264,然后执行systemctl start ceph-osd@25 即可。该方法是判断105894251-105894263中的数据损坏,osd启动,进行replay时候无法读取该段数值报错(默认修改前commit_op_seq是105894250),这里绕过该段数值重新设置seq思路解决。
涉及bug:https://tracker.ceph.com/issues/6003
5.osd启动失败,日志提示object_map sync got (1) Operation not permitted
a.故障现象
使用vdbench工具往cephfs挂载点写入数据过程中,osd down掉,重启osd也启动不了,osd日志:
2018-11-01 11:01:50.482203 b6867000 5 osd.10 pg_epoch: 975 pg[2.25( v 954'2580 (0'0,954'2580] local-les=959 n=3 ec=66 les/c/f 959/959/0 975/975/714) [9,5,10]/[9,5] r=-1 lpr=0 pi=708-974/40 crt=954'2580 lcod 0'0 inactive NOTIFY NIBBLEWISE] enter Reset
-8> 2018-11-01 11:01:50.483487 b6867000 5 osd.10 pg_epoch: 975 pg[0.10b(unlocked)] enter Initial
-7> 2018-11-01 11:01:50.520894 b6867000 5 osd.10 pg_epoch: 975 pg[0.10b( v 937'6036 (150'3000,937'6036] local-les=959 n=798 ec=77 les/c/f 959/959/0 975/975/736) [6,10]/[6] r=-1 lpr=0 pi=721-974/19 crt=937'6036 lcod 0'0 inactive NOTIFY NIBBLEWISE] exit Initial 0.037408 0 0.000000
-6> 2018-11-01 11:01:50.520972 b6867000 5 osd.10 pg_epoch: 975 pg[0.10b( v 937'6036 (150'3000,937'6036] local-les=959 n=798 ec=77 les/c/f 959/959/0 975/975/736) [6,10]/[6] r=-1 lpr=0 pi=721-974/19 crt=937'6036 lcod 0'0 inactive NOTIFY NIBBLEWISE] enter Reset
-5> 2018-11-01 11:01:50.522519 b6867000 5 osd.10 pg_epoch: 975 pg[1.15b(unlocked)] enter Initial
-4> 2018-11-01 11:01:50.560698 b6867000 5 osd.10 pg_epoch: 975 pg[1.15b( v 959'27450 (873'24391,959'27450] local-les=959 n=4307 ec=63 les/c/f 959/959/0 975/975/973) [10,1]/[1] r=-1 lpr=0 pi=958-974/8 crt=959'27450 lcod 0'0 inactive NOTIFY NIBBLEWISE] exit Initial 0.038179 0 0.000000
-3> 2018-11-01 11:01:50.560773 b6867000 5 osd.10 pg_epoch: 975 pg[1.15b( v 959'27450 (873'24391,959'27450] local-les=959 n=4307 ec=63 les/c/f 959/959/0 975/975/973) [10,1]/[1] r=-1 lpr=0 pi=958-974/8 crt=959'27450 lcod 0'0 inactive NOTIFY NIBBLEWISE] enter Reset
-2> 2018-11-01 11:01:50.562743 b6867000 5 osd.10 pg_epoch: 975 pg[2.5d(unlocked)] enter Initial
-1> 2018-11-01 11:01:50.581308 af60eb10 -1 filestore(/var/lib/vcfs/osd/vcfs-10) object_map sync got (1) Operation not permitted
0> 2018-11-01 11:01:50.583579 af60eb10 -1 os/filestore/FileStore.cc: In function 'void FileStore::sync_entry()' thread af60eb10 time 2018-11-01 11:01:50.581359
os/filestore/FileStore.cc: 3796: FAILED assert(0 == "object_map sync returned error")b.故障分析
上面日志中有object_map sync got (1) Operation not permitted关键字,开始以为是权限问题,然后检查了osd数据目录中所有文件的权限,没问题。然后怀疑是leveldb的问题,因为osd的omap是保存在leveldb中的
c.解决方法
使用下面的方法修复leveldb
$ python
…
>>> import leveldb
>>> leveldb.RepairDB('/var/lib/ceph/osd/ceph-$ID/current/omap')修复完leveldb之后,重启osd,osd可以正常启动了。
6.osd启动失败,日志提示object_map sync returned error
a.故障现象
osd.42 异常,出现assert, 关键信息:
1. os/filestore/FileStore.cc: 3778: FAILED assert(0 == "object_map sync returned error")
2. leveldb: xxx IO error :/var/lib/ceph/osd/ceph-42/current/omap/xxx.sst :Structure needs cleaning相关截图如下:
osd assert 日志:
sst相关日志: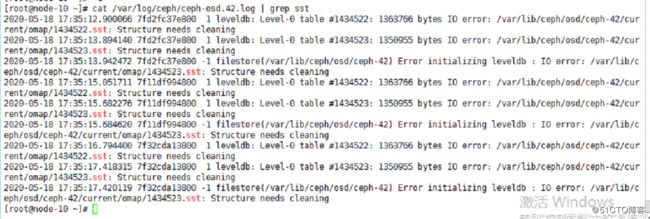
message CPU报错日志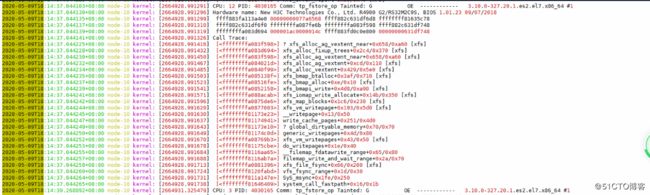
b.故障原因
CPU 发生call trace,导致数据库leveldb文件的objectmap sync写入sdb磁盘失败(sst文件损坏),osd尝试启动发现这些sst文件不存在或者不完整引发assert。
c.故障修复
先umount 挂载目录,再xfs_repair 修复。
1) 使用xfs_repair /dev/sdb1 ,操作完毕,启动osd,发现依然报错 xxx.sst :Structure needs cleaning,查看对应的omap目录下,对应的sst文件不存在。(修复时间几个小时)
2) 基于1),使用 xfs_repair -L /dev/sdb1 修复完后可以成功拉起(修复时间十几分钟)。分析:
猜测sst文件虽然不存在,但是可能相关元数据信息存在,但是无法删除,启动时候读取,找不到然后失败。这里采用 xfs_repair -L /dev/sdb1 ,-L选项有可能会弄丢数据,这里应该使用-L丢弃损坏的sst文件,然后启动osd,从其他副本上获取完整的数据,达到重新启动目的。
转载:https://ypdai.github.io/2018/04/11/osd%E5%B8%B8%E8%A7%81%E6%95%85%E9%9A%9C%E5%8F%8A%E5%A4%84%E7%90%86%E6%80%BB%E7%BB%93/