Huffman压缩
现在来总结一下Huffman压缩,首先,还是简单说一下概念,Huffman压缩,顾名思义,是一种压缩数据的方式,得名于压缩算法中用到的Huffman树,当然Huffman是这种数据结构的发明者,当时他还是个学生,这种压缩算法的思想是文本文件的普通保存方式:不再使用7位或8位二进制表示每一个字符,而是用较少的比特表示出现频率高的字符,用较多的频率保存那些出现频率少的字符。在进行压缩之前,先来看以下几个问题:
1. 压缩和解压,这两个过程都要实现,不然没意义做压缩,怎么压缩呢,具体思想是用较少的比特表示出现频率高的字符,用较多的频率保存那些出现频率少的字符。但是每个字符具体用哪些编码来表示呢?所以第一步我们要得到每个字符的Huffman编码,之后就可以不存储8位8位的编码而用我们的Huffman编码进行存储,可能有的字符2位,有的4位,有的8位,总的位数就减少了。
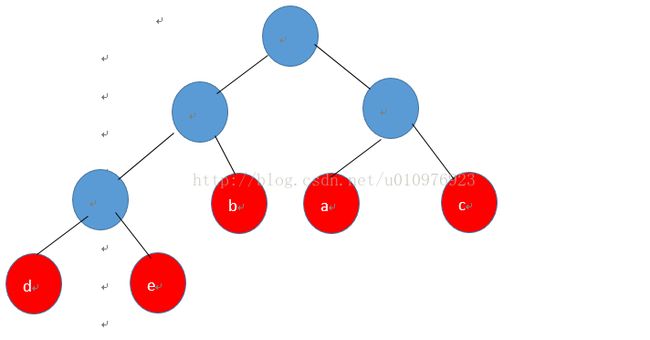
2. 好现在假设已经得到了每个字符的霍夫曼编码,也写到了文件newFile.txt中,这个文件是我们压缩之后的文件,后缀名没有意义,那我们怎么解压呢?也就是说每个字符的编码长度不等怎么进行区分呢?这里我们应该知道,Huffman编码是一种前缀编码,前缀编码也就是说任意一个字符的编码都不可能是其他字符的前缀,这种性质是由Huffman树所决定的,Huffman树是一种最优二叉树,这里我们强调一点,我们把每个字符存放在叶子节点中,每个叶子节点代表的字符肯定是不相同的,这些字符是出现在文本中的字符,也许这个文本很多字符,但至多26个,我指的是英文,先不包括符号,我们来看一个例子,看一下Huffman树是怎样的,就拿abaabcdcce这句来讲,首先有一个频率表:
| a |
b |
c |
d |
e |
| 0.3 |
0.2 |
0.3 |
0.1 |
0.1 |
对应的Huffman树是:
频率即权重,扩大10倍。
| a |
b |
c |
d |
e |
| 10 |
01 |
11 |
111 |
110 |
虽然是很简单的例子,但是也可以看到,Huffman编码确实是前缀码。
好了,最基础的问题解决之后我们看代码实现:
首先是构造Huffman树的代码:
import java.util.Comparator;
import java.util.PriorityQueue;
/**
* @author 蔡恒毅 2014-3-23
* 构建霍夫曼树以及涉及到霍夫曼树的各种操作
*/
public class HuffmanTree {
private Node root;// 霍夫曼树的树根
private static int size;
/**
* 构造一颗霍夫曼树,接受一个节点数组来进行创建,数组中每一个元素存储着字符和对应出现的次数(权值)
*
* @param data
* @return Node root
*/
public static Node buildhuffman(Node[] nodes) {
PriorityQueue pq = new PriorityQueue(nodes.length,
new Comparator() {
public int compare(Node o1, Node o2) {
return o1.getData().getWeight()
- o2.getData().getWeight();
}
});
for (int i = 0; i < nodes.length; i++) {
if (nodes[i] != null && nodes[i].getData() != null) {
if (nodes[i].getData().getWeight() > 0)
pq.add(nodes[i]);
}
}
// 创建霍夫曼树
while (pq.size() > 1) {
// 合并两颗权值最小的树
Node x = pq.poll();
Node y = pq.poll();
// 找到了两颗权值最小的树,现在开始合并。。。。
NodeData parents_data = new NodeData('X', x.getData().getWeight()
+ y.getData().getWeight());
// 指定关系
Node parents = new Node(parents_data, x, y);
pq.add(parents);
}
return pq.poll();
}
/**
* 先序读取霍夫曼的叶子节点的数据
*
* @param root
*/
public static void PrePrintTree(Node root) {
if (root != null) {
if (root.isLeaf())
System.out.print(root.getData().getData() + " "
+ root.getData().getWeight() + " ");
PrePrintTree(root.left);
PrePrintTree(root.right);
}
}
/**
* 中序读取霍夫曼的叶子节点的数据
*
* @param root
*/
public static void MidPrintTree(Node root) {
if (root != null) {
// NodeData data = root.data;//取出用户数据
// System.out.println(data);
MidPrintTree(root.left);
if (root.isLeaf())
System.out.print(root.getData().getData() + " "
+ root.getData().getWeight() + " ");
MidPrintTree(root.right);
}
}
/**
* 后序读取霍夫曼的叶子节点的数据
*
* @param root
*/
public static void HouPrintTree(Node root) {
if (root != null) {
// NodeData data = root.data;//取出用户数据
// System.out.println(data);
HouPrintTree(root.left);
if (root.isLeaf())
System.out.print(root.getData().getData() + " "
+ root.getData().getWeight() + " ");
HouPrintTree(root.right);
}
}
/**
* 根据霍夫曼树进行解码
*
* @param args
*/
// public static void decode() {
// Node root = readTree();
// int N = BinaryStdIn.readInt();
// for (int i = 0; i < N; i++) {
// // 展开编码所对应的字符
// Node x = root;
// while (!x.isLeaf()) {
// if (BinaryStdIn.readBoolean())
// x = x.right;
// else
// x = x.left;
// }
// BinaryStdOut.write(x.getData().getData());
// }
// BinaryStdOut.close();
// }
/**
* 将给定的字符数组,在这里是01串组成的字符数组,按照二进制转换为十进制的方法转换为int型
* @param cs
* @return
*/
public static int toBinary(char[] cs){
int t = 0;
for(int i = 0;i 我们再来看一下怎么把256个字符,可能没有这么多,将他们封装成节点中的数据,再封装成节点,然后再把节点构造成Huffman树,这个上面已经有了,现在我们看一下二次封装的过程:
/**
* 从外部获取文本或者其他文件,通过这个类,可以将他转换成压缩前的NodeData,
* 每个NodeData包括(data)字符和对应的(weight)出现次数
* 返回的这个数组最大是256
*/
import java.io.FileInputStream;
import java.util.Set;
/**
* @author 蔡恒毅
* 2014-3-23
*
*/
public class GetNodeData {
private static int R = 256;//ASCII字母表
// public static MyList list = new MyList();
public static int[] weight = new int[R];//weight数组里面每个元素是该下标对应字符的出现次数,也就是NodeData类的weight值
public static NodeData[] datas = new NodeData[R];
public static Node[] nodes = new Node[datas.length];
/**
* 从外部获取文件,按照一定方式将文件封装成为节点数组以便传给霍夫曼类的构造树的方法让它构造一颗霍夫曼树
* @param filename
* @return Node[]
*/
public static Node[] GetUserData(String filename){
try {
FileInputStream in = new FileInputStream(filename);
int i = in.read();
while(i!=-1){
weight[i]++;
// list.add(1);
i = in.read();
}
in.close();
} catch (Exception e) {
e.printStackTrace();
}
//进行封装,使其变成NodeData[]类型
for(int i = 0;i先是节点数据类:
/**
* 节点数据,存储叶子节点的数据和对应的权值,数据就是相应出现的字符,权值就是这个字符出现的频率
*/
import java.util.Collection;
import java.util.Iterator;
import java.util.Set;
/**
* @author 蔡恒毅
* 2014-3-23
*
*/
public class NodeData{
private char data;//出现的字符
private int weight; //出现的次数
/**
* 构造方法
* @param data
*/
public NodeData(char data,int weight){
this.data = data;
this.weight = weight;
}
/**
* 获取节点保存的字符
* @return data
*/
public char getData() {
return data;
}
public void setData(char data) {
this.data = data;
}
/**
* 获取当前节点的字符所出现的次数
* @return weight
*/
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
这是节点类:
/**
*
*/
/**
* @author 蔡恒毅 2014-3-23
*
*/
public class Node {
// 霍夫曼树中的节点
public NodeData data; // 自己本身的数据
public Node left, right;// 当前节点的左右孩子
public Node parents;// 当前节点的父节点
/**
* 构造一个新的节点的方法
*
* @param data
* @param left
* @param right
* @param parents
*/
public Node(NodeData data, Node left, Node right) {
super();
this.data = data;
this.left = left;
this.right = right;
}
public Node(char data,int weight, Node left, Node right) {
super();
this.data.setData(data);
this.data.setWeight(weight);
this.left = left;
this.right = right;
}
public Node(NodeData data) {
this.data = data;
}
public NodeData getData() {
return data;
}
public void setData(NodeData data) {
this.data = data;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
public Node getParents() {
return parents;
}
public void setParents(Node parents) {
this.parents = parents;
}
/**
* 判读当前节点是否是叶子节点
*/
public boolean isLeaf() {
return (left == null && right == null);
}
}
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
*
*/
/**
* @author 蔡恒毅
* 2014-3-26
*
*/
public class Compression {
public static Node root;
public static String[] myst;
public static String mycode;
public static void compression(String filename){
Node myNode = HuffmanTree.buildhuffman(GetNodeData.GetUserData(filename));
String[] st = Encode.buildCode(myNode);// 将哈夫曼树进行编码并且存储到String
// 数组里面,且这个数组由字符索引 这个数组就是码表
// 将每个字符的编码打印出来,这个过程是一步一步的,首先从外部得到文件,之后得到这个文件的霍夫曼编码表,压缩就是根据这个霍夫曼编码表进行
// 压缩,读到一个字符,就写入它对应的编码,这就是压缩的过程
root = myNode;
myst = st;
/**
* 以下是压缩的过程
*/
String code = "";
// 首先获取要写入的源文件,边读边写
try {
FileInputStream in = new FileInputStream(filename);//源文件
FileOutputStream out = new FileOutputStream("newFile.LS");//压缩之后的文件
int i = in.read();
//while循环体里面是边读边压缩的过程
while (i != -1) {
if (st[(char) i] != null) {
code += st[(char) i];//code是一个01字符串
}
i = in.read();
}
//执行完这里之后,code是一个长长的01串
/**对上面得到的长长的01串进行8个8个分组*/
mycode = code;
char[] temp = code.toCharArray();
String eight = "";
int int8 = (temp.length)/8;
int left = (temp.length)%8;
for(int j = 0;j<8*int8;j+=8){
for(int k = 0;k<8;k++)
eight += temp[j+k];
int t = HuffmanTree.toBinary(eight.toCharArray());
out.write(t);
eight = "";
}
/**
* 处理余数的问题
*/
for(int n = 8*int8;n这里的Huffman编码表示一个以字符为索引的字符串数组,下标代表数组,值代表对应的编码。
这里要进行一下强调,写入文件中去我们要对一长串01串进行处理,不可能a真的写进去字符串10,这样的话会越压越大,我们八个一组八个一组进行转换为int型,解压的时候再八个八个一组转换为01串,之后再根据Huffman树进行解压,那这里就会有二进制和十进制的互相转换,这个代码里已经实现了,不难理解,余数的处理也很重要,不然会有差错,因为不可能所有01串刚好是8的倍数,我们接下来看解压的过程:
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
*
*/
/**
* @author 蔡恒毅
* 2014-3-26
* 将压缩过的文件进行解压缩
*/
public class Decompress {
/**
* 获取霍夫曼树
* @param root
*/
public static void decompress(String filename){
try {
FileInputStream in = new FileInputStream(filename);//关联要解压的文件
FileOutputStream out = new FileOutputStream("Uncop.txt");//把文件解压到这里
String uncode = "";
int i = in.read();
while(i != -1){
uncode += completeBin(Integer.toBinaryString(i));
i = in.read();
}
/**
* 以下是解压的过程
*/
// char[] uncom = uncode.toCharArray();
char[] uncom = Compression.mycode.toCharArray();
int n = 0;
int q = 0;
for(int j = 0;j这就是解压的过程,解压的时候要处理的对象就是压缩文件了,我们一个字节一个字节读,把int转换为01串,也就是十进制转换二进制,之后根据Huffman树来进行解压缩,有一点需要说明,我们从第一个0或者1开始读,沿着树往下走,碰到0向左,碰到1向右,走到叶子节点就把数据读出来,这里的数据时节点数据,再读出字符就可以,然后再返回,从根节点继续读,这里已经读完一些01串了,一直这样循环就可以读完压缩文件,这是压缩前

这是压缩后

这是解压缩后:

可以看到确实压缩了,这种Huffman压缩式一种无损压缩,对于文本文件可以这样,但是一些视频,音频还是要采用有损压缩,代码主干就是这些,还有问题的希望多多指教,可以在下面评论,我会详细回答