【数据挖掘导论】——数据类型
数据类型
数据集的不同表现在很多方面。例如:描述数据对象的属性可有具有不同的类型——定量的或者定性的。并且数据集可能还具有特定的性质,如包含时间序列或者彼此相关联。这因为如此,数据的类型决定我们应使用何种工具和技术来分析数据。此外,数据挖掘的研究也是为了适应新的应用领域和新的数据类型。
数据的质量
数据通常远非完美,尽管大部分的数据挖掘技术都容忍不完美的数据,但注重理解和提高数据质量将是改进精确分析结果的重要途径之一。
使数据适合挖掘的预处理步骤
通常,原始数据必须经过加工才能适合分析。而加工处理一方面是提高数据的质量,另一方面让数据更好的适应特定的数据挖掘技术或者工具。
根据数据联系分析数据
数据分析的一种方法是找出数据对象之间的联系,之后使用这些联系而不是数据对象本身进行其余的分析。
通常,数据集可以看作数据对象的集合。数据对象可以是:记录,点,向量,模式等。数据对象用一组刻画对象基本特性的属性描述,如:变量,字段,特征或者维。
属性与度量
什么是属性:
属性(attribute)是对象的性质或者特性,它因对象而异或随着时间变化而变化。追根溯源,属性并非数字或符号。然而为了讨论和分析对象的特性,我们赋予了它们数字和符号。为了用一种明确定义的方式做到这点,我们需要测量标度。
测量标度(mreasurement scale)是将数值或符号值与对象的属性相关联的规则(函数)。形式上,测量过程是使用测量标度将一个值与一个特定对象的特定属性相关联。虽然说的有些抽象。但在生活中,我们无时无刻的进行测量过程,如:上公交车,会看有没有剩余的座位能坐等。这些情况下,都是对象属性的物理值被映射到数值或符号值。
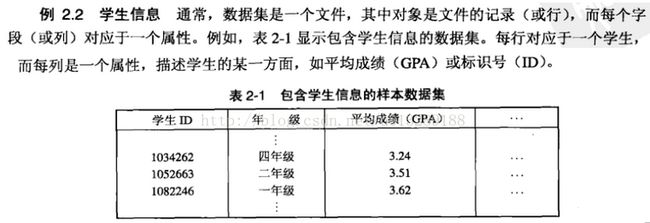
属性的类型
从前面得知,属性的性质不必与用来度量它的值的性质相同。即,用来代表属性的值可能具有不同与属性本身的性质,反之亦然。

属性的类型告诉我们,属性的那些性质反映在用于测量它的值中。知道属性的类型的重要性,因为它告诉我们测量值的那些性质与属性的基本性质一致,从而使我,恶魔得以避免计算雇员的平均ID这也愚蠢的行为,需要注意的是,通常将属性的类型称作测量标度的类型。
属性的不同类型
一种指定属性类型的有用方法是:确定对应属性基本性质的数值的性质。如:长度的属性可以有数值的许多性质,按长度比较对象,确定对象的排序,以及长度的差与比例都是有意义的。数值如下的操作通常用来描述属性:

给定这些性质,我们可以定义出四种属性类型:标称(nominal),序数(ordinal),区间(interval),比率(ratio)。
属性的类型也可以用不改变属性意义的变换来描述,如:长度可用米或者英尺来度量。下表给出上表的四种属性类型的允许变换:

用值的个数描述属性
区分属性的一种独立的方法就是根据属性可能取值的个数来判断
离散的(discrete)离散属性具有有限个或无限个可数个值。通常离散属性应整数变量表示。二元属性(binary attribute)是离散属性的一种特殊情况,只接受两个值:真假,是否,01等。二元属性用布尔变量表示。
连续的(continuous)连续属性是取实数值的属性。如温度,高度等。通常,连续属性用浮点变量表示。
从理论上讲,任何测量标度类型(标称的,序数的,区间的,比率的)都可以与基于属性值个数的任意类型(二元的,离散的,连续的)组合。有些组合并不常出现,或者没有什么意义。
非对称属性
对于非对称属性(asymmetric attribute),出现非零属性值才是重要的。如:对于一个,每个对象都是学生的数据集。每个属性记录学生是否选修大学的某个课程。对于某个学生,选修某个属性的课程,值为1,否则为0。由于学生只能选所有可选的课程的一部分,因此这种数据集的大部分值为0,因此关注非零值将更有意义。只有非零值才重要的二元属性是非对称的二元属性。
数据集的类型
数据集的类型有很多,一般我们将数据集分为三组:记录数据,基于图形的数据和有序数据。
数据集的一般特性
维度(dimensionality)数据集的维度是数据集中的对象具有的属性数目,分为底,中,高维度。在分析数据的时候,最好将数据的维度降低。因为在分析高维度数据的时候,会陷入所谓的
维灾难(curse of dimensionality)。因此,数据预处理的一个重要的动机就是减少维度,称为
维归约(dimensionality reduction)
稀疏性(sparsity)有些数据集,如具有非对称特征的数据集,一个对象的大部分属性上的值都是0,在许多情况下,非零项还不到1%。事实上,稀疏性是一个优点,因为只有非零值才需要存储和处理。这将大大节省计算时间和存储空间。
分辨率(resolution)常常可以在不同的分辨率下得到数据,且在不同的分辨率下数据的性质也不同。如:在几米的分辨率下,地表看起来很不平坦,但在数十公里的分辨率下却相对平坦。
记录数据
许多数据挖掘任务都是假定数据集是记录(数据对象)的汇集,每个记录包含固定的数据字段(属性)集。下面介绍不同类型的记录数据:

事务数据或购物篮数据
事务数据(transaction data)是一种特殊类型的记录数据,其中每个记录(数据)涉及一系列的项。考虑顾客一次购物所买的商品集合构成一个事务,而所有购买的商品作为项。这种类型的数据称作
购物篮数据(market basket data)。
数据矩阵
如果一个数据集族中所有数据对象都具有相同的数值属性集,则数据对象可以看作多维空间的点(向量),其中每个维代表对象的一个不同属性。这样的数据对象集可以用一个m*n的矩阵表示,其中m行,一个对象一行;n列,一个属性一列。这种矩阵称作
数据矩阵(data matrix)或
模式矩阵(pattern matrix)。
稀疏数据矩阵
稀疏数据矩阵是数据矩阵的一种特殊的情况,其中属性的类型相同并且是非对称的,即只有非零值才是重要的。事务数据是仅含0-1元素的稀疏数据矩阵的例子。另一个常见的便是文档数据。文档集合的表示通常称作
文档-词矩阵(document-term matrix),如图2-2d,文档是该矩阵的行,词是该矩阵的列。
基于图形的数据
有时图形可以有效的表示数据,但有两种特殊的情况:图形捕获数据对象之间的联系;数据对象本身用图形表示。
担忧对象之间联系的数据
对象之间的联系常常携带重要的信息。这种情况下,数据常常用图形表示。一般把数据对象映射到图的结点,而对象之间的联系用对象之间的链或方向,权值等表示。如相互链接的网页。
具有图形对象的数据
如果对象具有结构,即对象包含具有联系的子对象,则这样的对象常常用图形表示。如化学物的结构用图形表示。
有序数据
对于某些数据类型,属性涉及到时间或空间序的联系。如下:
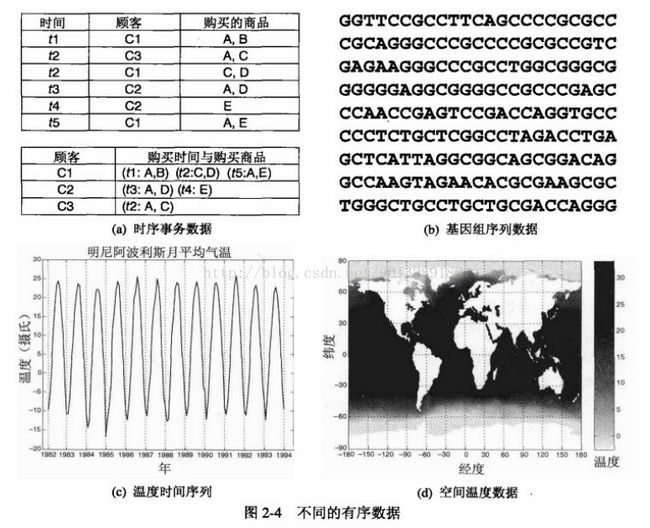
时序数据
时序数据(sequential data)也称
时间数据(temporal data),可以看作记录数据的扩充,其中每一个记录包含一个与之相关联的时间。时间也可以与每个属性相关,如:每个记录可以是一位顾客的购物历史,包含不同时间购买的商品列表。使用这些信息,我们也许可能发现:买了iPhone的人是不会在关注那些低端的android机的。
序列数据
序列数据(sequence data)是一个数据集合,它是各个实体的序列,如:词或字母的序列,基因组序列等
时间序列数据
时间序列数据(time series data)是一种特殊的时序数据,其中每个记录都是一个
时间序列(time series),即一段时间以来的测量序列。如图2-4c,记录的是一个地方1982年到1994年月平均的时间序列。需要注意的是:在分析时间数据时,需要考虑时
间自相关(temporal autocorrelation),即如果两个测量的时间很近,则这些测量的值通常非常的相似。
空间数据
某些数据也许还会拥有空间属性,如位置或区域。空间数据的例子有很多,比如:从不同地方收集气象数据。空间数据的一个重要的特点就是空间
自相关性(spatial autocorrelation),即物理上靠近的对象趋向于其他方面也相似。
处理非记录数据
大部分数据挖掘算法都是为记录数据或其变体(事务数据,数据矩阵)设计的。通过对象中提取特征,并使用这些特征创建对应与每个对象的记录,针对记录数据的技术也可以用与非记录数据。如化学结构的数据,给定一个常见的子结构集合,每个化合物都可以用一个具有二元属性的记录表示,这些二元属性指出化合物是否包含特定的子结构,这也的表示实际上是事务数据集,其中事务是化合物,而项是子结构。