【ML】 李宏毅机器学习笔记
我的github链接 - 课程相关代码:
https://github.com/YidaoXianren/Machine-Learning-course-note
0. Introduction
- Machine Learning: define a set of function, goodness of function, pick the best function
- Regression输出的是一个标量,Classification输出的是(1)是或否(Binary Classification) (2) Multi-class Classification
- 选不同的function set其实就是选不同的model,model里面最简单的就是linear model;此外还有很多nonlinear model,如deep learning, SVM, decision tree, kNN...... 以上都是supervised learning - 需要搜集很多training data
- Semi-supervised learning(半监督学习) - 有些有有些没有label
- Transfer Learning - data not related to the task considered
- Unsupervised Learning(非监督学习)
- Structured Learning - Beyond Classification (输出的是一个有结构性的object)
- Reinforcement Learning - 没有监督知道,只有一个好or坏的评分机制(learning from critics)
- 蓝色: scenario; 红色: task - 要解的问题; 绿色: method.

1. Regression
- output a scalar
- Step1: Model:
 w and b are parameters, w: weight, b: bias
w and b are parameters, w: weight, b: bias - Linear Model:
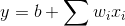
- Step2: Goodness of Function - Loss function L: input is a function, output is how bad it is (损失函数)
- first version of Loss Function:
 or
or 
- Step3: Best Function -
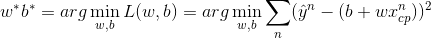
- Gradient Descent (梯度下降法) - 只要loss func对与它的参数是可微分的就可以用,不需要一定是线性方程
- - Pick an initial value
 ; - Compute
; - Compute  ; -
; -  , where
, where  is learning rate. Continue this step until finding gradient that is equal to zero.
is learning rate. Continue this step until finding gradient that is equal to zero. - For two parameters:
 ; - Pick initial value:
; - Pick initial value:  ; - Compute
; - Compute  ; -
; - 
 。Continue this step until finding gradient that is equal to zero.
。Continue this step until finding gradient that is equal to zero. - 以上方法得出来的结果
 满足:
满足:
- gradient descent缺点:可能会卡在saddle point或者local minima
- 对于linear regression, 由于它是convex的函数,所以不存在上述缺点。
- Liner Regression - Gradient descent formula summary:
- 复杂的模型在test data上不一定有更好的表现,有可能是overfitting(过拟合)
- overfit的解决方法:1. 增加input数据集 2. regularization
- Regularization (正则化)
-

- 不但要选择一个loss小的function,还要选择一个平滑的function(正则化使函数更平滑, 因为w比较小) - smoother function is more likely to be correct
 大,找出来的function就比较smooth。反之,找出来的则不太smooth. 在由小到大变化的过程中,函数不止要考虑loss最小化还要考虑weights最小化,所以对training error最小化的考虑就会相对(于没有正则化的时候)减小,因此training error会随着增大而增大。test error则先减小再增大。
大,找出来的function就比较smooth。反之,找出来的则不太smooth. 在由小到大变化的过程中,函数不止要考虑loss最小化还要考虑weights最小化,所以对training error最小化的考虑就会相对(于没有正则化的时候)减小,因此training error会随着增大而增大。test error则先减小再增大。



2. Error
- Bias:
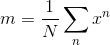 ; Variance:
; Variance:  ;
; ![E[s^2] = \frac{N-1}{N}\sigma^2 \neq \sigma^2](http://img.e-com-net.com/image/info8/960a33d633cc4226b7fdf3e3e8025520.gif) ; want low bias & low variance
; want low bias & low variance - when using low degree(simple) models, variance is small, while complicate model leads to large variance. 简单的模型受采样数据的影响较小
- Bias: If we average all the
 , it is close to
, it is close to  . 是每次训练的最佳函数(model)解(注:每次训练包含多个数据样本-sample data),而是真实的函数(model)。
. 是每次训练的最佳函数(model)解(注:每次训练包含多个数据样本-sample data),而是真实的函数(model)。 - simple models have larger bias & smaller variance, while complicate models have smaller bias & larger variance.
- 如果error来自于variance很大,说明现在的模型是overfitting;如果error来自bias很大,说明现在的模型是underfitting
- 如果模型没法fit training data,说明此时bias很大;如果模型很fit training data, 但是很不fit test data,说明此时variance很大
- For large bias: add more feature, make a more complicate model
- For large variance: get more data, or regularization (所有曲线都会变得比较平滑)
- Cross Validation: Training Set, Validation Set, Testing Set (Public, Private)
- N-fold Cross Validation - 交叉验证: 可以先分成training set和validation set, train的用来训练model, validation的用来挑选model。选定model之后再用整个data set (training set+validation set)来重新train这个model的参数
3. Gradient Descent
- L: loss function,
 : parameters
: parameters - 假设有两个变量
 , 则:
, 则: ![\theta^0 = \left[ \begin{matrix} \theta^0_1 \\ \theta^0_2 \end{matrix} \right]](http://img.e-com-net.com/image/info8/30009735ac6a4fa69c57bf38c2b95ab2.gif) ;
;  ; -->
; --> 这里:
![\triangledown L(\theta)= \left[ \begin{matrix} \partial L(\theta_1)/\partial \theta_1 \\ \partial L(\theta_2)/\partial \theta_2 \end{matrix} \right]](http://img.e-com-net.com/image/info8/3470b344138c404ca9e3c2f6b9adb69e.gif)
- 设置learning rate:
- 可以绘制loss vs. No. of parameters updates(同一个循环的参数迭代次数)的曲线,观察变化趋势;
- Reduce the learning rate by some factor every few epochs - e.g. 1/t decay:
 ;
; - Give different learning rates to different parameters - Adagrad - divide the learning rate of each parameter by the root mean square of its previous derivatives

 can be elimated... then it comes to the following form:
can be elimated... then it comes to the following form: -
Adagrad 更新法则:
 ,
,  为当下的梯度值(偏微分) - 造成反差效果
为当下的梯度值(偏微分) - 造成反差效果 -
The best step is
 . Adagrad实际上是在模拟这样一个运算。但是又比直接算二次微分节省时间。
. Adagrad实际上是在模拟这样一个运算。但是又比直接算二次微分节省时间。
- Stochastic Gradient Descent (让training更快):
- Gradient Descent的loss function是对全部example而言,加总的所有loss (update after seeing all examples)。而SGD是随机选一个example,然后计算这一个example的loss,然后更新参数(update for each example)


- Feature Scaling (归一化)
- 如果不做归一化,不同参数的scale不一样可能导致同样是稍微改变一个权重的大小,对于scale小的变量而言变化很小,而对于scale大的变量而言变化很大。
- 由于做update的时候是沿着等高线垂直方向更新的,归一化之后的更新效率会高一些。
- 做feature scaling:
- for each dimension i: compute mean (
 ) and standard deviation (
) and standard deviation ( ).
). - change each data using:
 - after this step, the means of all dimensions are 0, and variance are all 1
- after this step, the means of all dimensions are 0, and variance are all 1
- for each dimension i: compute mean (

- 可以从泰勒级数的角度理解gradient descent - learning rate够小,泰勒级数才能约等于只有一次项,才能保证每次都能往loss最小的方向移动
- Gradient Descent可能不work的情况:
- Stuck at local minima
- Stuck at saddle point
- Very slow at the plateau
- 解析解(Analytical solution) = 封闭解(Closed-form solution): 根据严格的公式推导,给出任意自变量可以得到因变量的问题的解。 数值解(Numerical solution):用数值分析,各种逼近的方法得到的近似解。
4. Classification: Probabilistic Generative Model
- Generative model
- Given x, which class does it belong to:

- Estimating the probabilities from training data. Consider
 as class 1, and
as class 1, and  as class 2.
as class 2. - Generative Model:

- Assume the points are sampled from a Gaussian distribution
- Gaussian distribution:

- Input - vector x; Output - probability of sampling x. 函数的形状取决于mean (
 ) and covariance matrix (
) and covariance matrix ( )
) - 思路:假设examples都是在一个高斯分布中取样出来的点,通过这些点计算出mean和covariance matrix,找到这个高斯分布,再用这个高斯分布函数来计算新进来的点(是不是这一类)的概率
- 任意一个组合的mean和covariance matrix都可以表示出平面上的任意一个点,只是似然值不一样,有极大似然值(maximum likelihood)的那个就假设为这个类的高斯分布函数的参数
- Likelihood of a Gaussian with mean and covariance matrix = the probability of the Gaussian samples
- 似然值等于所有这个类的点的概率的乘积

- 拥有极大似然值的一组mean和covariance matrix为:
- 使不同class共用同一个covariance,likelihood:

 和
和 都和之前一样,分别算自己类样本的平均数。
都和之前一样,分别算自己类样本的平均数。
- 如果用同一个covariace matrix,训练出来的boundary是线性的
- Probability Distribution
- For binary features, you can use Bernoulli distributions instead.
- If assume all dimension are independent, then it is Naive Bayes Classifier.
- For binary features, you can use Bernoulli distributions instead.
- Posterior Probability
- 描述概率算出来的模型和logistic regression的联系,下图中在covariance matrix一致时又可以写成wx+b的形式。
- Sigmoid function形式的导出

- Bayes - 先验,后验,似然
- 贝叶斯公式: P(y|x) = (P(x|y)*P(y))/P(x)
- P(y|x) 为后验概率, P(x|y)为条件概率or似然概率,P(y)和P(x)为先验概率
- 所以贝叶斯公式也可以表述为:后檐概率=(似然度*先验概率)/标准化常量。 即:后验概率与先验概率和似然度的乘积成正比。



5. Logistic Regression
- want to find
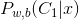 , if it is larger than or equal to 0.5, then output C1; otherwise, output C2.
, if it is larger than or equal to 0.5, then output C1; otherwise, output C2. - Assume the data is generated based on
 , then the probability of generating the data is
, then the probability of generating the data is  , where
, where  is training data. Then the most likely
is training data. Then the most likely  and
and  is the one with largest
is the one with largest 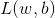 :
: 
-
![w^*, b^* = arg \min_{w,b} \sum_n-[\hat y^nlnf_{w,b}(x^n) + (1-\hat y^n)ln(1-f_{w,b}(x^n))]](http://img.e-com-net.com/image/info8/d6a01056cb1f45e58077015016824937.gif) - the sum is cross entropy between two Bernoulli distribution (交叉熵).
- the sum is cross entropy between two Bernoulli distribution (交叉熵). - 交叉熵 - cross entropy
- assume distribution p:
 ;
; 
- assume distribution q:
 ;
; 
- Then the cross entropy is:

- cross entropy实际上就是在maximize likelihood
- assume distribution p:

- 注:上图的C是交叉熵
- Logistic regression的step2只能用交叉熵不能用square error, 因为后者不管
 等于1还是0,算出来的偏微分
等于1还是0,算出来的偏微分 都等于0,无法更新。
都等于0,无法更新。 - Discriminative v.s. Generative
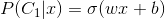
- Discriminative: 直接用logistic regression的方法算出w和b
- Generative: 算出高斯分布的参数,再推导出对应的w和b (or其他概率论的方式)
- 假设不一样,所以算出来的结果是不一样的 - 在dataset一样的前提下,discriminative算出的结果准确率往往要比generative的高
- Naive Bayes里面假设每个事件都是independent的,比如00|01|10 & 11的分类,样本不均的时候可能会分错,因为model可能会脑补不存在的情况
- generative模型的好处:基于概率分布的假设,所需的training data比较少; 对noise比较robust;Priors and class-dependent probabilities can be estimated from different sources
- Multi-class Classification - Softmax (待更新 - 参数更新公式)
- Limitation of Logistic Regression
- 异或问题无法直接解决 - 可以用feature transformation转成可以解决的问题(not always easy...)
- Cascading logistic regression models (把多个logistic regression堆叠起来,一些用来feature transformation,一些用来classification) - 其实就是深度学习(deep learning)
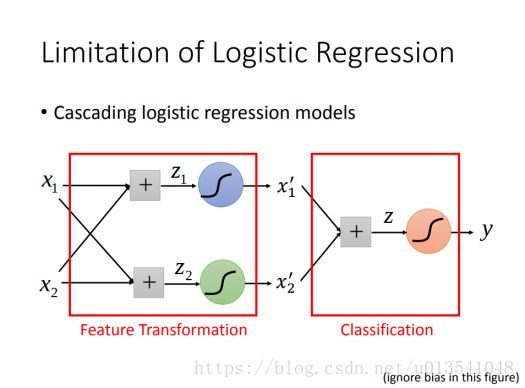


6. Deep Learning
- Given network structure, define a function set.
- Machine learning有一些问题不可分的时候需要做feature transformation。而deep learning就只需要设计一个structure,确定多少层,每层多少个neurons
- Universality Theorem: Any continuous function f can be realized by a network with one hidden layer given enough hidden neurons
7. Backpropagation
- Chain rule
- Forward Pass:每个神经元输出值对输入值的偏微分

- Backward Pass: 每个神经元从远端过来的偏微分
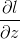
- 最后,有:

8. Keras
- 例子: https://keras.io/
- mnist数据集下载地址: http://yann.lecun.com/exdb/mnist/


-


- dense - 指的是添加的是一个fully connected的layer
- activation function: softplus, softsign, sigmoid, tanh, hard_sigmoid, linear, softmax.
- loss function: categorical crossentropy
- optimizer: adam, SGD, RMSprop, Adagrad, Adadelta, Adamax, Nadam
- Mini-batch:
- 一:将全部训练集分成许多组,每组内随即分配example
- 二:随机初始化一组网络参数
- 三:选择第一组batch计算它的total loss,根据这个loss更新一次网络参数
- 四:重复步骤三直到所有的mini-batch都选择完了(完成一个步骤四称为一个epoch)
- *batch size = 1的话就相当于是Stochastic gradient descent(SGD), smaller batch size means more updates in one epoch. batch size主要是为了提速 -- 同样多的数据,大的batch size完成一次epoch需要的时间远小于小的batch size。batch size = 10 is more stable, converge faster.
- *very large batch size can yield worse performance - 很容易卡到local minima. (SGD 或者小batch size能缓解这个问题是因为每次更新时的随机batch有助于跳出gradient为0的区域)
9. Deep Neuron Networks Troubleshooting
- 先看看在training set上训练的结果好不好,如果结果也不好,可能是卡在了local minima等地方,要回去看看前面设置的参数;如果training结果好testing结果不好,说明是overfitting;如果两个都好,就是一个好的可以用的DNN。*区别于machine learning(SVM with rbf kernel, decision, knn with k=1), deep learning在training set不一定能得到100%准确率
- Network叠很深不一定会更好,可能会有Vanishing Gradient Problem(梯度消失)的问题:接近input的几层gradient非常小,接近output的几层gradient非常大,所以当learning rate都一样的时候,前面几层的学习速度(参数更新速度)非常慢,而后面几层学习速度快很多 - 所以前面还是随机的时候(还没怎么更新),后面的已经收敛了,因此不会在更新,卡在了一个performance很差的situation。- 该现象是来自于sigmoid function(这个activation func),它会使input衰减,把正负无穷大的input压到0-1之间,所以当层数很多的时候就会越来越小,导致前面几层的gradient非常小。
- 解决方案1: 改成dynamic (adaptive)的learning rate
- 解决方案2: 直接改activation func为ReLU (Rectified Linear Unit)
- 换成ReLU的原因:1. 比sigmoid计算快(没有指数运算) 2. 有生物学上的理由 3. ReLU是由无限的sigmoid叠起来形成的 4. 能够解决梯度消失的问题
- 当用ReLU的时候,由于小于0的output都变成了0,就相当于对后面的网络没有影响,这样就只保留下了input大于0的unit和他们有链接的unit, 所以整个网络就变成了一个线性的网络(thinner linear network),所以就没有小的gradient。 - 注:这里指的线性是局部线性(在某次input的附近范围线性),但是整体上还是非线性的 - 分段线性。
- 变形:Leaky ReLU; Parametric ReLU; Exponential Linear Unit (ELU)
- Maxout: 每一个neuron有一个自动学出来的activation function(特指piecewise linear convex function) - 分为几段取决于把几个element放在一个group。(比如ReLU就是其中一种,两个element放一个group,所以分成了两段)

- Maxout是可以train的,当给定input的时候,我们就知道每一层里面哪个是max的值,所以可以简化成一个thin and linear的网络(只保留了max的unit),所以用gradient descent直接算就可以了。 - 注!每个example放进来生成的简化网络是不一样的,因为每次局部的max都不一样。所以当全部example都跑完,一开始那个network的全部参数都会被训练到。
- Adaptive learning rate
- Adagrad
- RMSProp (Adagrad的变形)
- Momentum: momentum of last step minus gradient at present

- 考虑前一次的移动方向,其实就是考虑过去所有的移动方向
- Adam: RMSProp + Momentum
- Overfitting解决方法:
- Early Stopping:overfit的时候随着epoch的增加training的error会越来越小,但是testing的会先减小后变大,所以可以让它停在testing error最小的epoch那里(这里用validation set代替testing set)。
- Regularization
- Find a set of weight not only minimizing original cost(e.g. minimize square error, cross entropy) but also close to zero
- L2 regularization
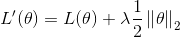

- L2 regularization:
 Gradient:
Gradient: 
- 更新规则:
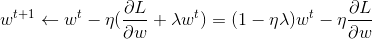
- 第一项小于1,所以每次更新w的值都会越来越接近于0,但是由于有后面偏微分这项的存在,所以并不会最终变成0,除非是对于L影响不大的w,这些w由于影响不大,偏微分接近0,所以自然就慢慢变成了0,从而达到减少参数数量的效果。 - 所以L2 regularization也叫做weight decay。
- L1 regularization

- L1 regularization:
 Gradient:
Gradient: 
- 更新规则:

- 最后一项不管w是大于0还是小于0总是让w不断的趋近与0。
- L1和L2正则化的比较:L2对数值大的weight的惩罚力度比较大(因为每次更新是直接消w*一个固定的值),而L1对所有weight都一视同仁(因为每次更新消的都是sign,正负1*一个固定的值); L1做出来参数间的差距可以拉的很大,有一些会很接近于0,而L2做出来整体上比较靠近,但是很难有非常靠近0的参数。
- Regularization在DNN中作用不是很大,因为一开始就是从接近0的地方初始化参数的。而且Regularization跟early stopping的作用有些重叠,所以有early stopping就不太需要regularization.
- Dropout:
- 每次在update之前: each neuron has p% to dropout - 同这些neurons链接的线也消失,使整个网络变得很thin, then using the new thinner network for training. (注!for each mini-batch, we resample the dropout neurons)
- 在testing的时候,没有dropout。另外,如果训练的时候每个weight的dropout rate是p%,则每个weight要乘以1 - p%
- Dropout is a kind of ensemble(训练很多种不同的network然后加权平均)
- Adagrad
- Practice - mnist:
- 如果training data不够fit,可以尝试改大hidden layer的neuron数量
- cross entropy在分类问题上比mse好很多。
- 要用GPU加速,batch size一定要开大一些才行(如10000)
- batch size从100调到10000正确率就降低了(因为相当于更新的次数少了)
- batch size从100调到1速度就会变得很慢,因为GPU不能发挥并行运算的效能
- 如果加深network的层数,会有梯度消失,performance不会变好。
- 如果把sigmoid都变成ReLU,准确率就升高了。
- 如果一开始没有做normalization,维持0-255的input区间,也无法训练成功
- 注!要养成先看一遍training set的习惯,如笔者的数据集本身就是0-1的,再按照视频做多一次normalization就无法训练出来
- 把optimizer从SGD改成Adam可以让收敛速度更快 - 体现在accuracy变化上
- 添加了noise之后的testing data准确率不高(此时training set的准确率很高),可以用dropout - 注!加了dropout之后在training上的performance是会变差的,但在testing set上performance会变好
- 注:Keras上每个步骤输出的acc是指在当下training的epoch的准确率

10. Convolutional Neural Network (CNN)
- Why CNN for image:
- Some patterns are much smaller than the whole image: a neuron does not have to see the whole image to discover the pattern. (convolution)
- The same patterns appear in different regions. (convolution)
- Subsampling the pixels will not change the object. (max pooling)
- CNN - Convolution
- Filter matrix中的data都是train出来的参数(根据training data),但是filter matrix的size和一共有多少个filter是自己设计的。
- stride = 步长 = 每次filter移动的距离
- Filter走完生成的新的image叫做feature map
- Convolution就是fully connected的进化版 - 把每个filter中的各个元素当成一个个weight分别和每个局部图的pixel相乘。 -不过举例如果filter是3x3的就只连接9个input,不是fully connected. 并且由于整张image用的是同一个filter来卷积,相当于share weights
- 做完之后each filter is a channel
- CNN - Max Pooling (下采样)
- nxn的一个范围内保留最大的一个pixel值
- 下采样也可以用average pooling
- CNN - Flatten
- 把每一个channel里面的pixel值全部拉出来,拉成一个nx1的vector
- 做完以上处理之后就可以放进fully connected的network里面做gradient descent了
- CNN - Example (注意参数数量)
- CNN - What does CNN learn
- Degree of the activation of the k-th filter:
 (assume the output of the k-th filter is a 11x11 matrix.)
(assume the output of the k-th filter is a 11x11 matrix.) - 假设X是input图像,利用偏导
 和gradient descent算出来的图像就是每个filter最兴奋的图像,即特征(pattern)。这里有
和gradient descent算出来的图像就是每个filter最兴奋的图像,即特征(pattern)。这里有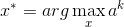
- DNN很容易被欺骗(如雪花噪点),可以通过增加一些额外的constraint来防止这种情况发生:
- 偏微分求出对正确class贡献最大的pixel并表示出来
- 用灰色框遮掉某一部分看是不是无法辨识出来,从而看出哪部分最有利于class判定
- 风格迁移:
- A Neural Algorithm of Artistic Style
- https://arxiv.org/abs/1508.06576
- Shallow(Fat+Short) v.s. Deep(Thin+Fall) - 要保证neurons数量一致才可以比较:deep的比较好
- 在做deep的时候其实就是在做modularization(结构化,模组化的架构),某个output class的例子太少的时候如果直接一层train会比较weak,而用modularization分类归纳就容易很多(share by following neurons as modulus) - can be trained by little data. - use previous layer as module to build classifiers.
- 单层网络可以完成全部function,但是是很没有效率的。
- 所以deep的可以用比较少的data和参数,也比较不容易overfitting
- deep可以处理更复杂的问题
- 语音 - 模组化
- Determine the state each acoustic feature belongs to
- Gaussian Mixture Model (GMM)
- In HMM-GMM, all the phonemes are modeled independently - not efficient.
- DNN input - one acoustic feature; DNN output - probability of each state
- end to end learning
- what each function should do is learned automatically
- only provide input and output and let each layer learnt by itself - do not need to deal too much with original data, just replace them by a new layer.
- Degree of the activation of the k-th filter:


11. Semi-supervised learning
- semi-supervised 就是有部分训练集没有label,并且通常没有label的data比有label的多。
- Trasductive learning: unlabeled data is the testing data; Inductive learning: unlabeled data is not the testing data.
- semi的准确率很大程度取决于对于未知的data假设的label是否准确
- Semi-supervised Learning for Generative Model
- The unlabeled data
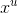 help re-estimate
help re-estimate  (可能看了unlabeled的之后知道概率分布的均值和方差在其他地方) - 进而影响decision boundary
(可能看了unlabeled的之后知道概率分布的均值和方差在其他地方) - 进而影响decision boundary - 算法最后总能收敛,但是怎么样初始化会影响到收敛的结果
 类似EM算法
类似EM算法 注意考虑了unlabeled data的最大似然的公式
注意考虑了unlabeled data的最大似然的公式
- The unlabeled data
- Low-density Separation Assumption
- low-density: 在两个类的boundary附近density是最低的,数据点最少
- Self-training
 不能用在regression上
不能用在regression上- 跟generative training相似,但是Self-training用的是hard label, 而前者用的是soft label(属于两种类都可能,只是概率不一样)
- 如果用neural network, 只能用hard label,soft label相当于反复自证,无法更新。hard label - It looks like class 1, then it is class 1.
- Entropy-based Regularization
- Entropy of
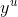 (class of an unlabeled data): evaluate how concentrate the distribution is:
(class of an unlabeled data): evaluate how concentrate the distribution is:  , 要让它越小越好。 (信息熵) - 这里的m指的是class
, 要让它越小越好。 (信息熵) - 这里的m指的是class - 所以一开始loss function只考虑labelled data的交叉熵越小越好(第一项),现在就可以添加一项,让unlabelled data的信息熵也越小越好(第二项):

- Entropy of
- Semi-supervised SVM
- 枚举出所有unlabelled data的分类可能,每一种都做一下svm
- 再看那一种可能性能够让margin最大,又minimize error,又少分类错误
- 存在一个问题是如果数据过多很难处理,需要做一些approximation
- Smoothness Assumption
- Assumption: "similar" x has the same

- More precisely: x is not uniform, if x1 and x2 are close in a high density region, then
 and
and  are the same.
are the same. - Cluster and then Label
- 待补充:deep auto encoder - 用来让cluster时各种类别差异更明显
- Graph-based Approach(谱聚类) - represented the data points as a graph - 如果两个点之间有相连就是一类
- Graph Construction:
- 首先要定义两个数据点的相似度(similarity) -

- Add edge
- k Nearest Neighbor(kNN)
- e-Neighborhood: 每个点只有跟它相似度超过某个threshold的才算
- Edge weight is proportional to
- Gaussian Radial Basis Function (RBF):

- Gaussian Radial Basis Function (RBF):
- 首先要定义两个数据点的相似度(similarity) -
- Graph Construction:
- 数据点要够多,否则有可能会传不过去
- 定量的使用方式 - 定义一个smoothness of the labels - labels有多符合假设,每个相邻data之间都用线连起来,每条线都赋予一个权重(weight),然后smoothness表示为:
 for all data, no matter labelled or not. 算出来的smoothness越小越好
for all data, no matter labelled or not. 算出来的smoothness越小越好
- 另一种表示方法

- 同理,可以在原先只考虑labelled data的loss function里再加上smoothness这一项,然后gradient descent:
 , 后面这项也相当于regularization.
, 后面这项也相当于regularization.
- Assumption: "similar" x has the same
12. Unsupervised Learning - Linear Methods (线性降维)
- Clustering & Dimension Reduction (化繁为简) - only have function input; Generation(无中生有) - only have function output
- Clustering
- K means
- Hierarchical Agglomerative Clustering (HAC) - 凝聚层次聚类: 分多少类取决于threshold切在哪里
- K means
- Distributed Representation - 不把object定为某一类,而写成每一类百分之几
- 如果一开始某个data是很高维的,现在表示成distributed representation,就相当于降维了,dimension reduction.
- Dimension Reduction - linear methods
- Feature Selection - 观察样本的数据,将没有用的dimension直接拿掉
- Principle Component Analysis (PCA) - 主成分分析 - z=Wx
- 重要前提(假设):

- 希望降维之后得到的z的variance越大越好,这样可以保持data point之间的奇异度 - 才能看出区别。
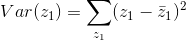 , 这里的
, 这里的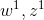 表示第一维
表示第一维 - 假设还想要第二维,第二维要满足
 且
且  , 即第二维跟第一维垂直:
, 即第二维跟第一维垂直: 
- 依次算出所需维数的z,则总的权重矩阵为各个维按顺序排列而成,且这个W是一个orthogonal matrix (因为每个row都互相垂直)
- PCA的推导
- SVD - 待补充
- PCA looks like a neural network with one hidden layer (linear activation function) - autoencoder
- PCA involves adding up and subtracting some components(images) - 如人脸的PCA是很多类似个别人脸的图像。-本质是SVD分解出来的两个matrix的值可正可负。
- 如果非要让做出来的PCA的eigen image为可拼接笔画(或组成部分),要用non-negative matrix factorization (NMF): 1. forcing a1, a2, ... be non-negative (can only use add when making a image by eigen images); 2. forcing w1, w2, ... be non-negative(more like "part of digits")
- weakness of PCA
- 由于是unsupervised的learning,有可能第一个主成分分的就刚好在两个类的boundary上,导致所有data point在这上面的投影都混在一起,无法分开。
- 无法做non-linear dimension reduction
- 重要前提(假设):
- Matrix Factorization (常用于推荐系统)
- K: 潜在因素 - latent factor

- 如果matrix中有一些missing data,就用gradient descent的方法做: minimizing
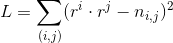 only considering the defined value. - Find
only considering the defined value. - Find  and
and 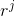 by gradient descent.
by gradient descent. - 算出和之后,就可以用来预测矩阵中缺少的值。
- 用在文本上就叫做潜在语义分析(latent semantic analysis - LSA)
- Number in table: term frequency(weighted by inverse document frequency)


13. Unsupervised Learning: Word Embedding (词嵌入)
- 即用在文字上的dimension reduction
- word embedding - 表示词汇关系的vector - machine learns the meaning of words from reading a lot of documents without supervision.
- 1-of-N encoding: 一个很大的vector,只有一个词汇本身对应的element是1其他都是0. 缺点:词汇间关系无法从vector中表现出来
- word class - 主动将词汇分成很多类并直接用类表示
- word embedding: 每一个词汇都用一个continuous的vector来描述,这个vector的每个dimension都可以代表某种含义(比如会动不会动,生物非生物etc..)。
- 根据词汇context的上下文找vector
- Count based: If two words
 and
and 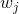 frequently co-occur,
frequently co-occur,  and
and  would be close to each other. 两个V的inner product正相关与两个w在同个文本中相似语义出现的次数
would be close to each other. 两个V的inner product正相关与两个w在同个文本中相似语义出现的次数 - Prediction-based: predict接下来要出现的词汇是哪一个词汇
- 不需要deep,一层的线性模型就可以。 太多层反而不容易计算
- Count based: If two words
- Bag of word - 一对词汇放到一个bag里面当作一个整体
- Beyond bag of word: To understand the meaning of a word sequence, the order of the words can not be ignored.
14. Unsupervised Learning: Neighbor Embedding
- Manifold Learning (流型学习)
- 如果在将维的过程中可以将曲面展开的话,就可以用欧几里得距离 - suitable for clustering or following supervised learning.
- Locally Linear Embedding (LLE)
- 先找出一组w使得下图式子最小,然后再根据这个w找出降维后的空间,使得第二个式子也最小。


Reference:
1. https://www.bilibili.com/video/av10590361?from=search&seid=18363492564668253415