整洁面向对象分层架构 (Clean Object-Oriented and Layered Architecture)
All problems in computer science can be solved by another level of indirection .
-- David Wheeler
计算机科学中的任何问题,都可以通过加上一层逻辑层来解决。
-- David Wheeler
为什么要分层呢?
在计算机领域,“分层” 概念无处不在。比如 web 开发时的 MVC ,网络编程时的 OSI 参考模型和 TCP/IP 协议族。
但是为什么要进行分层呢?
分层的好处
《图解TCP/IP》:
在这一模型中,每个分层都接收它下一层所提供的特定服务,并且负责为自己的上一层提供特定的服务。上下层之间进行交互时所遵循的约定叫做“接口”。
而Marting Fowler《企业应用架构模式》开篇第 1 章是这样说的:
在分解复杂的软件系统时,软件设计者用得最多的技术之一就是分层。
在第 1 章后面,又举了一个表现层,领域层,数据源层的例子。
Eric Evans的《领域驱动设计》(DDD):将业务语义显现化,把原先晦涩难懂的业务算法逻辑,通过领域对象(Domain Object),统一语言(Ubiquitous Language)将领域概念清晰的显性化表达出来。
相信我,这种表达带来的代码可读性的提升,会让接手你代码的人对你心怀感恩的。借用Abelson的一句话是
Programs must be written for people to read, and only incidentally for machines to execute.
(所以强烈谴责那些不顾他人感受的编码行为)
分层为什么会带来好处?
对于为什么要分层,大多数文章说的只是它带来的好处。比如下层修改实现,不影响上层使用;分离关注点等。但是为什么会带来这些好处?
当用分层的观点来考虑系统时,可以将各个子系统想像成按照“多层蛋糕”的形式来组织,每一层都依托在其下层之上。在这种组织方式下,上层使用了下层定义的各种服务,而下层对上层一无所知。另外,每一层对自己的上层隐藏其下层的细节。
Grady Booch / Robert A.Maksimchuk / Michael W.Engle / Bobbi J.Young 《面向对象分析与设计》:
开发软件本身是一件很复杂的事情(必须认识到这一点)。而我们人类大脑的能力是有限的,不可能同时处理太多的复杂性。我们可以通过将复杂性分解、抽象、分层,一次只需要处理一个部分复杂性,而不是所有。
所以,“分层”并不能让复杂性消失,而是让我们的大脑在能力范围内处理相对重要的层面的复杂性,而忽略那些不那么重要的细节。
比如, 开发一个HR系统,你的大脑应集中精力放在业务逻辑上,而不是操作系统如何与硬件打交道(并不是说操作系统原理不重要,只是在HR系统上不重要)。

软件开发所面对的复杂性超出了我们人类大脑一次性能处理的范围,而分层是一种手段,帮助我们人类只需要处理相对重要的层面的复杂性,而忽略相对不重要层面的复杂性。进而使我们以更低的成本达到目的。而好处只是副产品。
接下来的问题,如何进行分层呢?
分层好坏的标准是什么?
留给大家思考。
分层模式是最通用的架构,也被叫做N层架构模式(n-tier architecture pattern).这也是Java EE应用经常采用的标准模式.基本上都知道它.这种架构模式非常适合传统的IT通信和组织结构,很自然地成为大部分应用的第一架构选择。
软件架构模式之分层模式
一、模式分析
分层架构模式里的组件被分成几个平行的层次,每一层都代表了应用的一个功能(展示逻辑或者业务逻辑)。尽管分层架构没有规定自身要分成几层几种,大多数的结构都分成四个层次:表现层,业务层,持久层,和数据库层。如图一,有时候,业务层和持久层会合并成单独的一个业务层,尤其是持久层的逻辑绑定在业务层的组件当中,形成。因此,有一些小的应用可能只有3层,一些有着更复杂的业务的大应用可能有5层或者更多的分层。
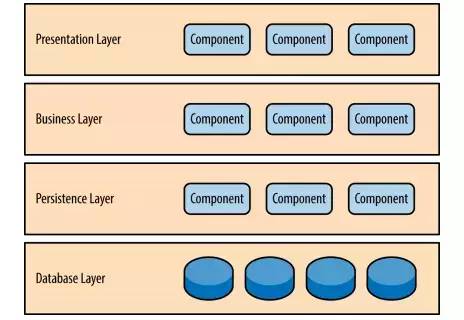
架构里的层次是具体工作的高度抽象,它们每一层都有特定的角色和职能,都是为了实现某种特定的业务请求。比如说展示层并不需要关心怎样得到用户数据,它只需在屏幕上以特定的格式展示信息。业务层并不关心要展示在屏幕上的用户数据格式,也不关心这些用户数据从哪里来。它只需要从持久层得到数据,执行与数据有关的相应业务逻辑,然后把这些信息传递给展示层。各层实现的功能如下:
| 层 | 功能 |
|---|---|
| 表现层(presentation) | 用户界面,负责视觉和用户互动 |
| 业务层(business) | 实现业务逻辑 |
| 持久层(persistence) | 提供数据,SQL 语句就放在这一层 |
| 数据库(database) | 持久化数据 |
二、关键概念——层隔离
上面图一中,每一层都是封闭的。这是分层架构中非常重要的特点。这意味request必须一层一层的传递。举个例子,从展示层传递来的请求首先会传递到业务层,然后传递到持久层,最后才传递到数据层。
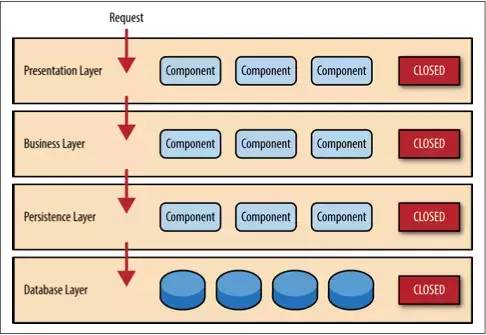
如果只是获得以及读取数据,展示层直接访问数据层,比穿过一层一层来得到数据来的快多了,那么为什么不允许展示层直接访问数据层?
这涉及到一个概念:层隔离。
层隔离是说架构中的某一层的改变不会影响到其他层:这些变化的影响范围限于当前层次。如果展示层能够直接访问持久层了,假如持久层中的SQL变化了,这对业务层和展示层都有一定的影响。这只会让应用变得紧耦合,组件之间互相依赖。这种架构会非常的难以维护。分层隔离使得层与层之间都是相互独立的,架构中的每一层的互相了解都很少。
然而封闭的架构层次也有不便之处,有时候也应该开放某一层。如果想往包含了一些由业务层的组件调用的普通服务组件的架构中添加一个分享服务层。在这个例子里,新建一个服务层通常是一个好主意,因为从架构上来说,它限制了分享服务访问业务层(也不允许访问展示层)。如果没有隔离层,就没有任何架构来限制展示层访问普通服务,难以进行权限管理。
例如下面的例子,新的服务层是处于业务层之下的,展示层不能直接访问这个服务层中的组件。但是现在业务层还要通过服务层才能访问到持久层,这一点也不合理。这是分层架构中的老问题了,解决的办法是开放某些层。如图三所示,服务层现在是开放的了。请求可以绕过这一层,直接访问这一层下面的层。既然服务层是开放的,业务层可以绕过服务层,直接访问数据持久层。这样就非常合理。
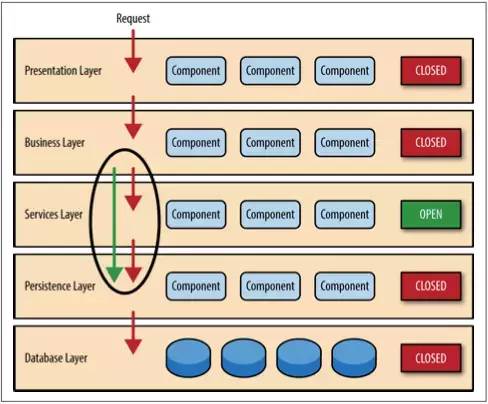
开放和封闭层的概念确定了架构层和请求流之间的关系,并且给设计师和开发人员提供了必要的信息理解架构里各种层之间的访问限制。如果随意的开放或者封闭架构里的层,整个项目可能都是紧耦合,一团糟的。以后也难以测试,维护和部署。
三、分层架构场景示例
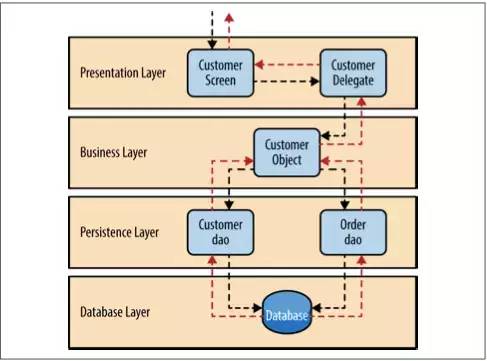
为了演示分层架构是如何工作的,想象一个场景,如图四,用户发出了一个请求要获得客户的信息。黑色的箭头是从数据库中获得用户数据的请求流,红色箭头显示用户数据的返回流的方向。在这个例子中,用户信息由客户数据和订单数组组成(客户下的订单)。
用户界面只管接受请求以及显示客户信息。它不管怎么得到数据的,或者说得到这些数据要用到哪些数据表。如果用户界面接到了一个查询客户信息的请求,它就会转发这个请求给用户委托(Customer Delegate)模块。这个模块能找到业务层里对应的模块处理对应数据(约束关系)。业务层里的customer object聚合了业务请求需要的所有信息(在这个例子里获取客户信息)。这个模块调用持久层中的 customer dao 来得到客户信息,调用order dao来得到订单信息。这些模块会执行SQL语句,然后返回相应的数据给业务层。当 customer object收到数据以后,它就会聚合这些数据然后传递给 customer delegate,然后传递这些数据到customer screen 展示在用户面前。
四、分层架构的优缺点
优点
1、开发人员可以只关注整个结构中的其中某一层;
2、可以很容易的用新的实现来替换原有层次的实现;
3、可以降低层与层之间的依赖;
4、有利于标准化;
5、利于各层逻辑的复用。
6、结构更加的明确
7、在后期维护的时候,极大地降低了维护成本和维护时间
缺点
1、降低了系统的性能。这是不言而喻的。如果不采用分层式结构,很多业务可以直接造访数据库,以此获取相应的数据,如今却必须通过中间层来完成。
2、有时会导致级联的修改。这种修改尤其体现在自上而下的方向。如果在表示层中需要增加一个功能,为保证其设计符合分层式结构,可能需要在相应的业务逻辑层和数据访问层中都增加相应的代码。
3、增加了开发成本。
COLA 架构是什么?

COLA作为架构,组要是制定了一套指导和约束,并将这套规范沉淀成Archetype。以便通过Archetype可以快速的生成符合COLA规范的应用。满足COLA的应用是一个有清晰的依赖关系的分层架构,如下图所示:
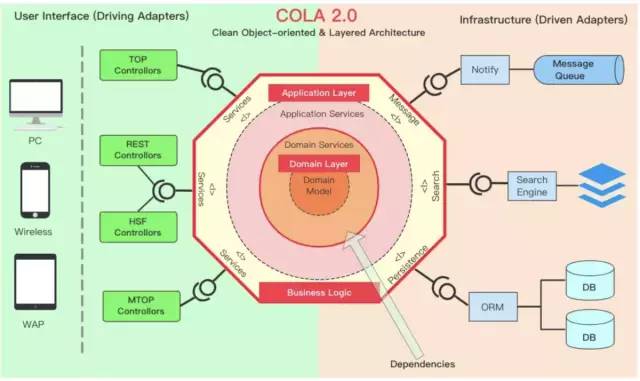
项目实战
COLA 脚手架提供了两个Archetype,分别是cola-archetype-service和cola-archetype-web
cola-archetype-service
用来生成纯后端应用(没有Controller),生成应用的命令为:
mvn archetype:generate -DgroupId=com.alibaba.demo -DartifactId=demo -Dversion=1.0.0-SNAPSHOT -Dpackage=com.alibaba.demo -DarchetypeArtifactId=cola-framework-archetype-service -DarchetypeGroupId=com.alibaba.cola -DarchetypeVersion=2.0.0
cola-archetype-web
用来生成Web后端应用(有Controller),生成应用的命令为:
mvn archetype:generate -DgroupId=com.alibaba.demo -DartifactId=demo -Dversion=1.0.0-SNAPSHOT -Dpackage=com.alibaba.demo -DarchetypeArtifactId=cola-framework-archetype-web -DarchetypeGroupId=com.alibaba.cola -DarchetypeVersion=2.0.0
如何使用COLA
第一步:生成COLA应用
1、使用Archetype生成应用:
直接运行上面提供的Archetype命令就可以生成应用,如果你的Remote Maven Repository里面没有Archetype的Jar包,也可以自己下载Archetype到本地,然后本地运行 mvn install安装。
2、 检查应用里的模块和组件:
如果命令执行成功的话,我们可以看到如下的代码结构,它们就是COLA应用架构。

第二步:运行Demo
1、进入在第一步中生成的应用目录。
2、启动SpringBoot:
首先在demo目录下运行mvn install(如果不想运行测试,可以加上-DskipTests参数)。然后进入start目录,执行mvn spring-boot:run。运行成功的话,可以看到SpringBoot启动成功的界面。
3、 执行测试:
生成的应用中,已经实现了一个简单的Rest请求,可以在浏览器中输入 http://localhost:8080/customer?name=World 进行测试。
4、查看运行日志:
请求执行成功的话,可以在浏览器中的返回值中看到:"customerName":"Hello, World"。同时观察启动SpringBoot的控制台,可以看到LoggerInterceptor打印出来的日志。
Kotlin 开发者社区

国内第一Kotlin 开发者社区公众号,主要分享、交流 Kotlin 编程语言、Spring Boot、Android、React.js/Node.js、函数式编程、编程思想等相关主题。
越是喧嚣的世界,越需要宁静的思考。