Python 爬取学校课程表和成绩
本文仅用于学习交流爬虫技术,不用于商业,转载请说明出处!
最近在自学 Python 网络爬虫,想实际练练手,于是选择了学校的教务管理系统,获取课表、成绩、排名和绩点。
我用的 Python 版本是 3.6,全部使用标准库,用到的库如下:
urllib.requesturllib.parsehttp.cookiejartimere
urllib.request 和 urllib.parse 用来发送网络请求,http.cookiejar 用来保存 cookie,time 用来生成 Unix 时间戳,re 通过正则表达式从网页中获取网络请求需要的一个参数。
代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
import http.cookiejar
import time
import re
url = "http://sso.jwc.whut.edu.cn/Certification//login.do"
user = input("Username: ")
password = input("Password: ")
# 表单参数
params = {
'systemId': '',
'xmlmsg': '',
'userName': user,
'password': password,
'type': 'xs',
'imageField.x': '60',
'imageField.y': '19'
}
# 处理 Cookie
cookie = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
opener.addheaders = [
('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0'),
('Host', 'sso.jwc.whut.edu.cn'),
('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'),
('Referer', 'http://sso.jwc.whut.edu.cn/Certification/toLogin.do'),
('Connection', 'keep=alive')
]
data = urllib.parse.urlencode(params).encode()
# 打开教务处首页
response_index = opener.open(url, data)
# 打开成绩首页
response_score_index = opener.open("http://202.114.90.180/Score/")
text_score_index = response_score_index.read().decode()
# 正则表达式从成绩首页的 HTML 中获取 snkey 字段
# (这个字段很重要,如果省略掉会提示非法查询)
snkey = re.findall(r'snkey=([0-9a-z]{8}-(?:[0-9a-z]{4}-){3}[0-9a-z]{12})',
text_score_index, re.I)[0]
# 打开历史成绩页面
response_score_history = opener.open("http://202.114.90.180/Score/lscjList.do?snkey={snkey}&_={ts}"
.format(snkey=snkey, ts=int(round(time.time() * 1000))))
# 显示 200 条记录
params_score = {
'pageNum': '1', # 当前页码
'numPerPage': '200', # 每页显示记录条数
'xh': user, # 学号
'xn': '', # 学年
'xnxq': '', # 学年学期
'nj': '',
'xydm': '',
'zydm': '',
'bjmc': '',
'kcmc': '',
'kcdm': '',
'xslb': '',
'kcxz': '',
'jsxm': '',
'snkey': snkey
}
show_200 = opener.open("http://202.114.90.180/Score/lscjList.do",
urllib.parse.urlencode(params_score).encode())
show_200_html = show_200.read().decode()
print(show_200_html)
# 学分、绩点、排名
credit_and_gpa = opener.open("http://202.114.90.180/Score/xftjList.do?_={ts}"
.format(ts=int(round(time.time() * 1000))))
print(credit_and_gpa.read().decode())获取的是 HTML,可以用正则表达式或者 BeautifulSoup 来解析。
分析思路
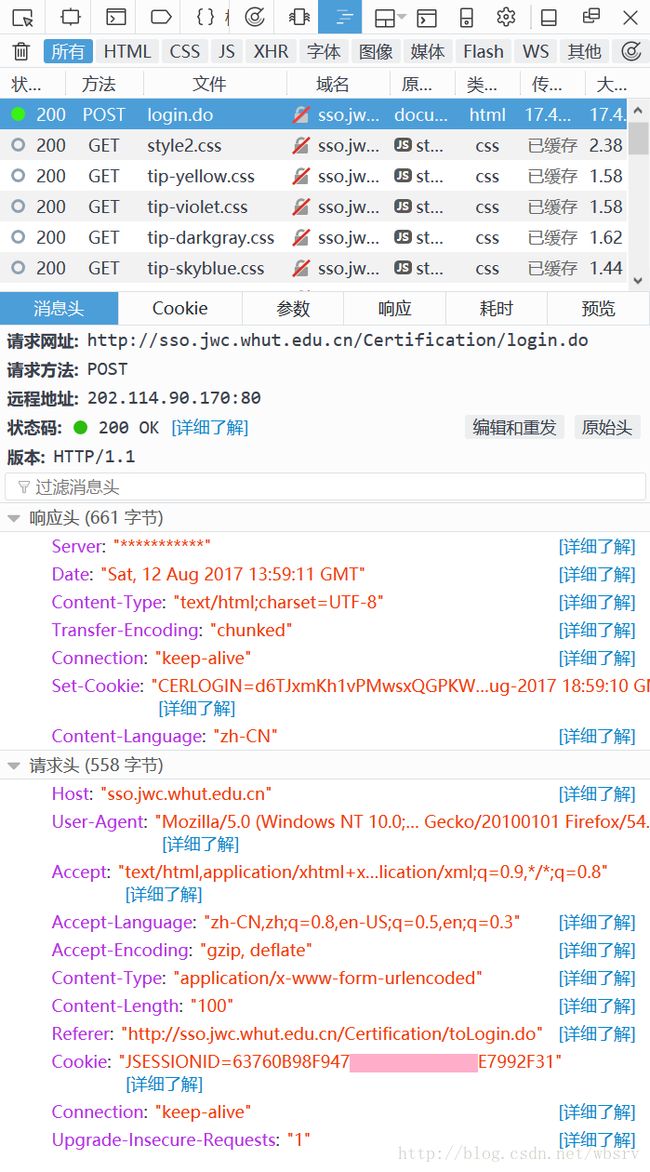
使用 Firefox 浏览器进入教务系统首页,按 Ctrl + Shift + Q 打开网络监视器(也可以按 F12 然后选择“网络”),输入用户名和密码登录,可以捕获到登录的 POST 请求:
切换到“参数”标签,可以看到 POST 的参数:
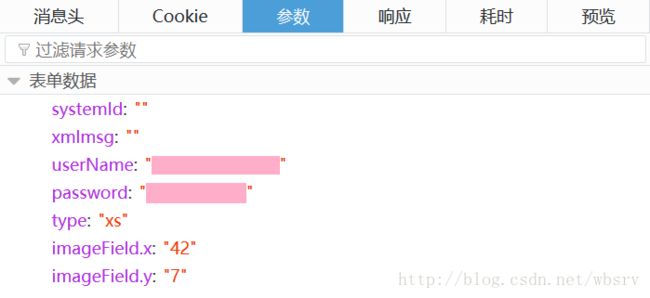
显然,表单数据中,userName 为用户名,而 password 为密码。
有了请求头和参数,我们就可以用 Python 发送一个 POST 请求,得到教务系统首页的 HTML 源码。但是因为浏览成绩、课表是要保持登录状态,因此需要处理 cookie,可以用 http.cookiejar 模块。
cookie = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))接下来,进入“成绩查询”页面。右击链接,选择“查看元素”,可以看到成绩查询页面的 URL:
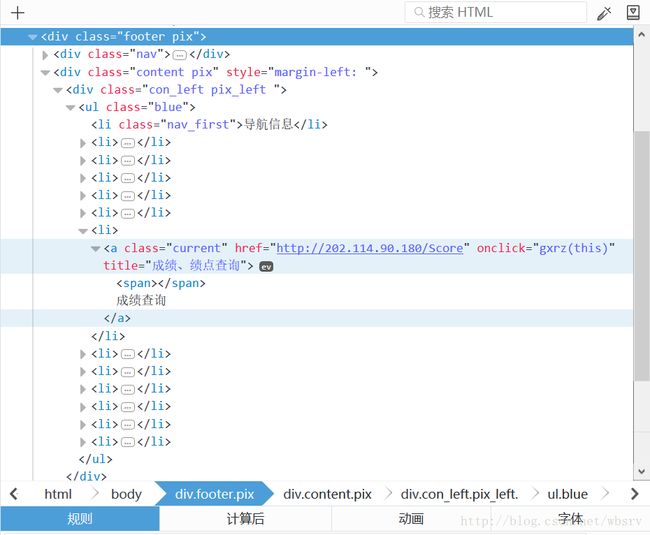
于是,通过这个 URL 进入成绩查询首页,并获取 HTML 源码:
response_score_index = opener.open("http://202.114.90.180/Score/")
text_score_index = response_score_index.read().decode()点击左侧功能模块中的“成绩查询”,显示成绩表,可以看到发送了一个 GET 请求:
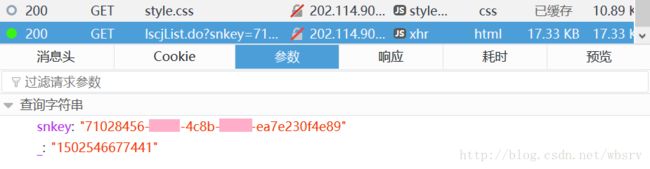
请求的参数有两个,一个是 snkey,8-4-4-4-12 格式的 GUID;还有一个是 _,13 位 Unix 时间戳。
snkey 字段在成绩查询首页的 HTML 中可以提取,使用正则表达式即可:
snkey = re.findall(r'snkey=([0-9a-z]{8}-(?:[0-9a-z]{4}-){3}[0-9a-z]{12})',
text_score_index, re.I)[0]_ 字段可以使用 Python 的 time 模块获取当前时间戳。由于 time.time() 默认获取的是个浮点数,要想取得 13 位时间戳,需要做如下计算:
ts = int(round(time.time() * 1000))得到了这两个参数的值之后,就可以发送 GET 请求了,获得的恰好是成绩页面的 HTML:
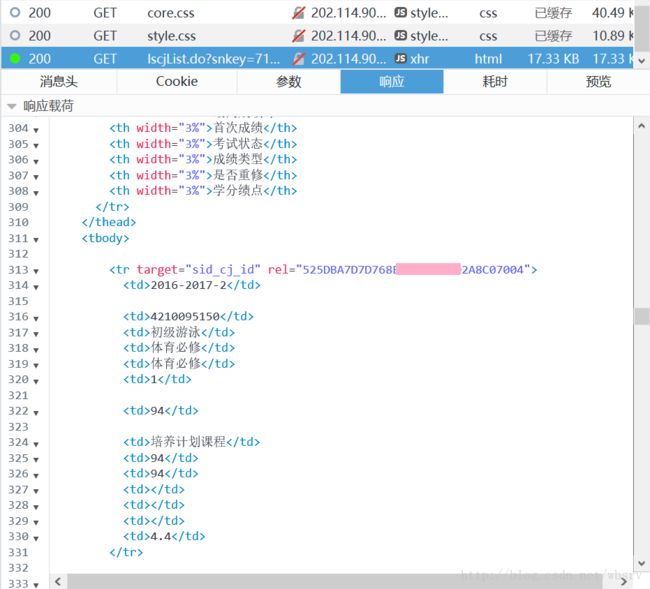
注:省略 _ 参数仍然可以获取数据,但是省略 snkey 参数会提示“非法查询”。
武汉理工大学教务系统默认显示最近的 20 条记录,但是这个值可以修改,通过 Firefox 可以发现,发送一个 POST 请求即可。参数如下:
params_score = {
'pageNum': '1', # 当前页码
'numPerPage': '200', # 每页显示记录条数
'xh': user, # 学号
'xn': '', # 学年
'xnxq': '', # 学年学期
'nj': '',
'xydm': '',
'zydm': '',
'bjmc': '',
'kcmc': '',
'kcdm': '',
'xslb': '',
'kcxz': '',
'jsxm': '',
'snkey': snkey # 这个 snkey 就是之前从 HTML 中抓取的 snkey
}获取排名和绩点也很简单,通过 Firefox 网络监视器可以看到请求的地址和参数。