https://docs.bonsai.io/article/123-capacity-planning
Capacity Planning
Capacity planning is the process of estimating the resources you’ll need over short and medium term timeframes. The result is used to size a cluster and avoid the pitfalls of inadequate resources (which cause performance, stability and reliability problems), and overprovisioning, which is a waste of money. The goal is to have just enough overhead to support the cluster’s growth at least 3-6 months into the future.
This document discusses how to estimate the resources you will need to get up and running on Elasticsearch. The process is roughly as follows:
- Estimating Shard Requirements
- Estimating Disk Requirements
- Planning for Memory
- Planning for Traffic
We have included a section with some sample calculations to help tie all of the information together.
Estimating Shard Requirements
Determining the number of shards that your cluster will need is one of the first steps towards estimating how many resources you will need. Every index in Elasticsearch is comprised of one or more shards. There are two types of shards: primary and replica, and how many total shards you need will depend not only on how many indices you have, but how those indices are sharded.
If you’re unfamiliar with the concept of shards, then you should read the brief, illustrated Shard Primer section first.
Why Is This Important?
Each shard in Elasticsearch is a Lucene instance, which often creates a large number of file descriptors. The number of open file descriptors on a node grows exponentially with shard counts. Left unchecked, this can lead to a number of serious problems.
Beware of High Shard Counts
There are a fixed number of file descriptors that can be opened per process; essentially, a large number of shards can crash Elasticsearch if this limit is reached, leading to data loss and service interruptions. This limit can be increased on a server, but there are implications for memory usage. There are a few strategies for managing these types of clusters, but that discussion is out of scope for preliminary capacity planning.
Some clusters can be designed to specifically accommodate a large number of shards, but that’s something of a specialized case. If you have an application that generates lots of shards, you will want your nodes to have plenty of buffer cache. For most users, simply being conscientious of how and when shards are created will suffice.
Full Text Search
The main question for this part of the planning process is how you plan to organize data. Commonly, users are indexing a database to get access to Elasticsearch’s full text search capabilities. They may have a Postgres or MySQL database with products, user records, blog posts, etc, and this data is meant to be indexed by Elasticsearch. In this use case, there is a fixed number of indices and the cluster will look something like this:
GET /_cat/indices
green open products 1 1 0 0 100b 100b green open users 1 2 0 0 100b 100b green open posts 3 2 0 0 100b 100b
In this case, the total number of shards is calculated by adding up all the shards used for all indices. The number of shards an index uses is the number of primary shards, p, times one the number of replica shards, r. Expressed mathematically, the total number of shards for an index is calculated as:
shards = p * (1 + r)
In the sample cluster above, the products index will need 1x(1+1)=2 shards, the users index will require 1x(1+2)=3 shards, and the posts index will require 3x(1+2)=9 shards. The total shards in the cluster is then 2+3+9=14 shards. If you need help deciding how many shards you will need for an index, check out the blog article The Ideal Elasticsearch Index, specifically the section called “Benchmarking is key” for some general guidelines.
Time Series Applications
Another common use case is to index time-series data. An example might be log entries of some kind. The application will create an index per hour/day/week/etc to hold these records. These use cases require a steadily-growing number of indices, and might look something like this:
GET /_cat/indices
green open events-20180101 1 1 0 0 100b 100b green open events-20180102 1 1 0 0 100b 100b green open events-20180103 1 1 0 0 100b 100b
With this use case, each index will likely have the same number of shards, but new indices will be added at regular intervals. With most time series applications, data is not stored indefinitely. A retention policy is used to remove data after a fixed period of time.
In this case, the number of shards needed is equal to the number of shards per index times the number of indices per time unit, times the retention policy. In other words, if an application is creating 1 index, with 1 primary and 1 replica shard, per day, and has a 30 day retention policy, then the cluster would need to support 60 shards:
1x(1+1) shards/index * 1 index/day * 30 days = 60 shards
Estimating Disk Requirements
The next characteristic to estimate is disk space. This is the amount of space on disk that your cluster will need to hold the data. If you’re a customer of Bonsai, this is the only type of disk usage you will be concerned with. If you’re doing capacity planning for another host (or self-hosting), you’ll want to take into account the fact that the operating system will need additional disk space for software, logs, configuration files, etc. You’ll need to factor in a much larger margin of safety if planning to run your own nodes.
Benchmarking for Baselines
The best way to establish a baseline estimate for the amount of disk space you’ll need is to perform some benchmarking. This does not need to be a complicated process. It simply involves indexing some sample data into an Elasticsearch cluster. This can even be done locally. The idea is to collect some information on:
- How many indices are needed?
- How many shards are needed?
- What is the average document size per index?
Database Size is a Bad Heuristic
Sometimes users will estimate their disk needs by looking at the size of a database (Postgres, MySQL, etc). This is not an accurate way to estimate Elasticsearch’s data footprint. ACID-compliant data stores are meant to be durable, and come with far more overhead than data in Lucene (what Elasticsearch is based on). There is a ton of overhead that will never make it into your Elasticsearch cluster. A 5GB Postgres database may only require a few MB in Elasticsearch. Benchmarking some sample data is a far greater tool for estimation.
Attachments Are Also a Bad Heuristic
Some applications are indexing rich text files, like DOC/DOCX, PPT, and PDFs. Users may look at the average file size (maybe a few MB) and multiply this by the total number of files to be indexed to estimate disk needs. This is also not accurate. Rich text files are packed with metadata, images, formatting rules and so on, bits that will never be indexed into Elasticsearch. A 10MB PDF may only take up a few KB of space once indexed. Again, benchmarking a random sample of your data will be far more accurate in estimating total disk needs.
Suppose you have a development instance of the application running locally, a local instance of Elasticsearch, and a local copy of your production data (or a reasonable corpus of test data). After indexing 10% of the production data into Elasticsearch, a call to /_cat/indices shows the following:
curl localhost:9200/_cat/indices health status index pri rep docs.count docs.deleted store.size pri.store.size green open users-production 1 1 500 0 2.4mb 1.2mb green open posts-production 1 1 1500 0 62.4mb 31.2mb green open notes-production 1 1 300 0 11.6mb 5.8mb
In this example, there are 3 indices. Each index has one primary shard and one replica shard, for a total of 2 shards per index.
We can also see that users-production has 1.2MB of primary data occupied by 500 documents. This means one of these documents is 2.4KB on average. Similarly, posts-production documents average 20.8KB and notes-production documents average 19.3KB.
We can also estimate the disk footprint for each index populated with 100% of its data. users-production will require ~12MB, posts-production will require around 312MB and notes-production will require ~58MB. Thus, the baseline estimate is ~382MB for 100% of the production data.
The last piece of information to determine is the impact of replica shards. A replica shard is a copy of the primary data, hosted on another node to ensure high availabilty. The total footprint of the cluster data is equal to the primary data footprint times (1 + number_of_replicas).
So if you have a replication factor of 1, as in the example above, the baseline disk footprint would be 382MB x (1 + 1) = 764MB. If you wanted an additional replica, to keep a copy of the primary data on all 3 nodes, the footprint requirement would be 382MB x (1 + 2) = 1.1GB. (Note: if this is confusing, check out the Shard Primer page).
Last, it is a good idea to add a margin of safety to these estimates to account for larger documents, tweaks to mappings, and to provide some “cushion” for the operating system. Roughly 20% is a good amount; in the example above, this would give a baseline estimate of about 920MB disk space.
Medium-term Projections
The next step is to determine how quickly you’re adding data to each index. If your database creates timestamps when records are created, this information can be used to estimate the monthly growth in the number of records in each table. Suppose this analysis was performed on the sample application, and the following monthly growth rates were found:
users-production: +5%/mo posts-production: +12%/mo notes-production: +7%/mo
In a 6 month period, we would expect users-production to grow ~34% from its baseline, posts-production to grow ~97% from its baseline, and notes-production to grow ~50% from its baseline. Based on this, we can guess that in 6 months, the data will look like this:
GET /_cat/indices
health status index pri rep docs.count docs.deleted store.size pri.store.size green open users-production 1 1 6700 0 32.0mb 16.0mb green open posts-production 1 1 29607 0 1.23gb 615mb green open notes-production 1 1 4502 0 174mb 86.9mb
Based on this, the cluster should need at least 1.44GB. Add the 20% margin of safety for an estimate of ~1.75GB.
These calculations for the sample cluster show that we should plan on having at least 1.75GB of disk space available just for the cluster data. This amount will suffice for the initial indexing of the data, and should comfortably support the cluster as it grows over the next 6 months. At the end of that interval, resource usage can be re-evalutated, and resources added (or removed) if necessary.
Time Series Data
Some use cases involve time-series data, in which new indices are created on a regular basis. For example, log data may be partitioned into daily or hourly indices. In this case, the process of estimating disk needs is roughly the same, but instead of looking at document sizes, it’s better to look at the average index footprint.
Consider this sample cluster:
GET /_cat/indices
health status index pri rep docs.count docs.deleted store.size pri.store.size green open logs_20180101 1 1 27954 0 194mb 97.0mb green open logs_20180102 1 1 29607 0 207mb 103mb green open logs_20180103 1 1 28764 0 201mb 100.7mb
One could estimate that the average daily index requires 200MB of disk space. In six months, that would lead to around 36.7GB disk usage. With the margin of safety, a cluster with 45GB of disk allocated to the cluster is needed.
There are two caveats to add: first, time series data usually does not have a six month retention policy. A more accurate estimate would be to multiply the average daily index size by the number of days in the retention policy. If this application had a 30 day retention policy, the disk need would be closer to 7.2GB.
The second caveat is too many shards can be a problem (see Estimating Shard Usage for some discussion of why). Creating two shards every day for 6 months would lead to around 365 shards in the cluster, each with a lot of overhead in terms of open file descriptors. This could lead to crashes, data loss and serious service interruptions if the OS limits are too low, and memory problems if those limits are too high.
In any case, if the retention policy creates a demand for large numbers of open shards, the cluster needs to be sized not just to support the data, but the file descriptors as well. On Bonsai, this is not something users need to worry about, as these details are handled for you automatically.
Planning for Memory
Memory is an important component of a high-performing cluster. Efficient use of this resource helps to reduce the CPU cycles needed for a given search in several ways. First, matches that have been computed for a query can be cached in memory so that subsequent queries do not need to be computed again. And servers that have been sized with enough RAM can avoid the CPU overhead of working in virtual and swap memory. Saving CPU cycles with memory optimizations reduces request latency and increases the throughput of a cluster.
However, memory is a complicated subject. Optimizing system memory, cache invalidation and garbage collection are frequent subjects of Ph.D. theses in computer science. Fortunately, Bonsai handles server sizing and memory management for you. Our plans are sized to accommodate a vast majority of Elasticsearch users.
“I want enough RAM to hold all of my data!”
This is a common request, and it makes sense in principal. RAM and disk (usually SSD on modern servers) are both physical storage media, but RAM is several orders of magnitude faster at reading and writing than high-end SSD units. If all of the Elasticsearch data could fit into RAM, then we would expect an order of magnitude improvement in latency, right?
This tends to be reasonable for smaller clusters, but becomes less practical as a cluster scales. System RAM availability offers diminishing returns on performance improvements. Beyond a certain point, only a very specific set of use cases will benefit and the costs will necessarily be much higher.
Furthermore, Elasticsearch creates a significant number of in-memory data structures to improve search speeds, some of which can be fairly large (see the documentation on fielddata for an example). So if your plan is to base the memory size on disk footprint, you will need to not only need to measure that footprint, but also add enough for the OS, JVM, and in-memory data structures.
For all the breadth and depth of the subject, 95% of users can get away with using a simple heuristic: estimate needing 10-30% of the total data size for memory. 50% is enough for >99% of users. Note that because Bonsai manages the deployment and configuration of servers, this heuristic does not include memory available to the OS and JVM. Bonsai customers do not need to worry about these latter details.
So where does that heuristic break down? When do you really need to worry about memory footprint? If your application makes heavy use of any of the following, then memory usage will likely be a factor:
- Highlighting
- Aggregations (a.k.a faceting)
- Dynamic scripting
- Geospatial search
- Deep pagination. This is when you have hundreds or thousands of pages of results; accessing results 9900 to 10000 requires substantially more overhead than results 1-100.
- Sorting large numbers of documents. This is similar to, but distinct from, deep pagination. See Efficient sorting of geo distances in Elasticsearch for a real world example.
- Frequent cache evictions (ex: caching timestamps by second or minute, instead of hourly or daily)
If your application is using one or more of these features, plan on needing more memory. If you would like to see the exact types of memory that Bonsai meters against, check out the Metering on Bonsai article.
Planning for Traffic
Capacity planning for traffic requirements can be tricky. Most applications do not have consistent traffic demands over the course of a day or week. Traffic patterns are often “spiky,” which complicates the estimation process. Generally, the greater the variance in throughput (as measured in requests per second, rps), the more capacity is needed to safely handle load.
Estimating Traffic Capacity
Users frequently base their estimate on some average number of requests: “Well, my application needs to serve 1M requests per day, which averages to 11-12 requests per second, so that’s what I’ll need.” This is a reasonable basis if your traffic is consistent (with a very low variance). But it is considerably inaccurate if your variance is more than ~10% of the average.
Consider the following simplified examples of weekly traffic patterns for two applications. The plots show the instantaneous throughput over the course of 7 days:
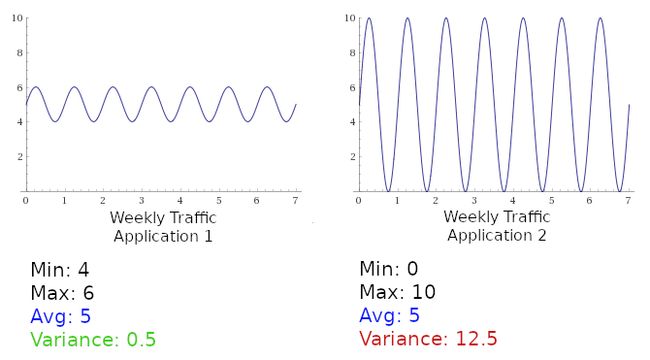 In each of these examples, the average throughput is the same, but the variance is markedly different. If they both plan on needing capacity for 5 requests per second, Application 1 will probably be fine because of Bonsai’s connection queueing, while Application 2 will be dramatically underprovisioned. Application 2 will be consistently demanding 1.5-2x more traffic than what it was designed to handle.
In each of these examples, the average throughput is the same, but the variance is markedly different. If they both plan on needing capacity for 5 requests per second, Application 1 will probably be fine because of Bonsai’s connection queueing, while Application 2 will be dramatically underprovisioned. Application 2 will be consistently demanding 1.5-2x more traffic than what it was designed to handle.
You’ll need to estimate your traffic based on the upper bounds of demand rather than the average. Some analysis will be necessary to determine the “spikyness” of your application’s search demands.
Traffic Volume and Request Latencies
There is a complex economic relationship between IO (as measured by CPU load, memory usage and network bandwidth) and maximum throughput. A given cluster of nodes has only a finite supply of resources to respond to the application’s demands for search. If requests come in faster than the nodes can respond to them, the requests can pile up and overwhelm the nodes. Everything slows down and eventually the nodes crash.
Simply: complex requests that perform a lot of calculations, require a lot of memory to complete, and consume a lot of bandwidth will lead to a much lower maximum throughput than simpler requests. If the nodes are not sized to handle peak loads, they can crash, restart and perform worse overall.
With multitenant class clusters, resources are shared among users and ensuring a fair allocation of resources is paramount. Bonsai addresses this complexity with the metric of concurrent connections. There is an entire section devoted to this in Metering on Bonsai. But essentially, all clusters have some allowance for the maximum number of simultaneous activeconnections.
Under this scheme, applications with low-IO requests can service a much higher throughput than applications with high-IO requests, thereby ensuring fair, stable performance for all users.
Estimating Your Concurrency Needs
A reasonable way to estimate your needs is using statistics gleaned from small scale benchmarking. If you are able to determine a p95 or p99 time for production requests during peak expected load, you can calculate the maximum throughput per connection.
For example, if your benchmarking shows that under load, 99% of all requests have a round-trip time of 50ms or less, then your application could reasonably service 20 requests per second, per connection. If you have also determined that you need to be able to service a peak of 120 rps, then you could estimate the number of concurrent connections needed by dividing: 120 rps / 20rps/connection = 6 connections.
In other words, a Bonsai plan with a search concurrency allowance of at least 6 will be enough to handle traffic at peak load. A few connections over this baseline should be able to account for random fluctuations and offer some headroom for growth.
Beware the Local Benchmarking
Users will occasionally set up a local instance of Elasticseach and perform a load test on their application to determine how many requests per second it can sustain. This is a problem because it neglects network effects.
Requests to a local Elasticsearch cluster do not have the overhead of negotiating an SSL connection over the Internet and transmitting payloads over this connection. These steps introduce a non-trivial latency to all requests, increasing round trip times and reducing throughput ceilings.
It’s better to set up a remote cluster, perform a small scale load test, and use the statistics to estimate the upper latency bounds at scale.
Another possibility with Bonsai is to select a plan with far more resources than needed, launch in production, measure performance, and then scale down as necessary. Billing is prorated, so the cost of this approach is sometimes justified by the time savings of not setting up performing and validating small-scale benchmarking.
Sample Calculations
Suppose the developer of online store decides to switch the application’s search function from ActiveRecord to Elasticsearch. She spends an afternoon collecting information:
- She wants to index three tables: users, orders and products
- There are 12,123 user records, which are growing by 500 a month
- There are 8,040 order records, which are growing by 1,100 a month
- There are 101,500 product records, which are growing by 2% month over month
- According to the application logs, users are averaging 10K searches per day, with a peak of 20 rps
Estimating Shard Needs
She reads The Ideal Elasticsearch Index and decides that she will be fine with a 1x1 sharding scheme for the users and ordersindices, but will want a 3x2 scheme for the products index, based on its size, growth, and importance to the application’s revenue.
This configuration means she will need 1x(1+1)=2 shards for the users index, 1x(1+1)=2 shards for the orders index, and 3x(1+2)=9 shards for the products index. This is a total of 13 shards, although she may eventually want to increase replication on the users and orders indices. She plans for 13-15 shards for her application.
Estimating Disk Needs
She sets up a local Elasticsearch cluster and indexes 5000 random records from each table. Her cluster looks like this:
GET /_cat/indices
green open users 1 1 5000 0 28m 14m green open orders 1 1 5000 0 24m 12m green open products 3 2 5000 0 540m 60m
Based on this, she determines:
- The
usersindex occupies 14MB / 5000 docs = 2.8KB per document. - The
ordersindex occupies 12MB / 5000 docs = 2.4KB per document. - The
productsindex occupies 60MB / 5000 docs = 12KB per document.
She uses this information to calculate a baseline:
- She will need 2.8KB/doc x 12,123 docs x 2 copies = 68MB of disk for the
usersdata - She will need 2.4KB/doc x 8,040 docs x 2 copies = 39MB of disk for the
ordersdata - She will need 12KB/doc x 101,500 docs x 3 copies = 3654MB of disk for the
productsdata - The total disk needed for the existing data is 68MB + 39MB + 3654MB = ~3.8GB.
She then uses the growth measurements to estimate how much space will be needed within 6 months:
- The
usersindex will have ~15,123 records. At 2.8KB/doc and a 1x1 shard scheme, this is 85MB. - The
ordersindex will have ~14,640 records. At 2.4KB/doc and a 1x1 shard scheme, this is 70MB. - The
productsindex will have ~114,300 records. At 12KB/doc and a 3x2 shard scheme, this is 4115MB. - The total disk needed in 6 months will be around 4.27GB.
Adding some overhead to account for unexpected changes in growth and mappings, she estimates that 5GB of disk should suffice for current needs and foreseeable future.
She also uses this to estimate her memory needs, and decides to estimate a memory footprint of up to 20% of the primary data, give or take. She estimates that 1.0GB should be sufficient for memory.
Estimating Traffic Needs
She knows from the application logs that her users hit the site with a peak of 20 requests per second. She creates a free Bonsai.io cluster, indexes some sample production data to it, and performs a small scale load test to determine what kinds of request latencies she can expect her application to experience while handling user searches with a cloud service.
She finds that 99.9% of all search traffic completes the round trip in less than 80ms. This gives her a conservative estimate of 12-13 requests per second per connection (1000ms per second / 80ms per request = 12.5 rps). With a search concurrency allowance of 2, she would be able to safely service around 25 connections, which is a little more than her current need for 20 rps.
Conclusion
Based on her tests and analysis, she decides that she will need a cluster with:
- Capacity for at least 13-15 shards
- A search concurrency of at least 2
- 1 GB allocated for memory
- 5 GB of disk to support the growth in data over the next 3-6 months
She goes to https://app.bonsai.io/pricing and finds a plan. She decides that at this stage, a multitenant class cluster offers the best deal, and finds that the $50/plan meets all of these criteria (and then some), so that’s what she picks.