医疗图像处理与深度学习(二)
卷积神经网络基础(CNN)
为了理解CNN的基础,首先我们需要了解什么是卷积 convolution。
什么是卷积convolution ?
维基百科将卷积定义为“对两个函数(f和g)的数学运算; 它产生第三个函数,通常被视为原始函数之一的修改版本,给出两个函数的逐点乘法的积分作为原始函数之一的转换量的函数。 可以将其简单理解为应用于矩阵的滑动窗口函数。
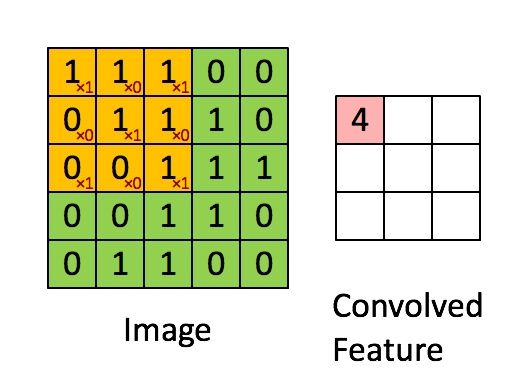
Convolution with 3×3 Filter. Source: deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
上图显示了以绿色应用于矩阵的滑动窗口,其中滑动窗口矩阵为红色。 输出是卷积特征矩阵。 下图显示了两个方形脉冲(蓝色和红色)的卷积和结果。
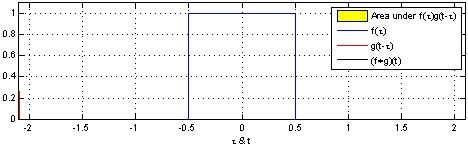
Source: Wikipedia.
Jeremy Howard在他的MOOC中使用excel表解释了卷积,这是理解基本原理的好方法。 考虑2个矩阵f和g。 f和g的卷积输出是由2个矩阵的点积给出的第三个矩阵“Conv层1”。 2个矩阵的点积是标量,如下所示。 这里可以找到一个很好的数学函数源。
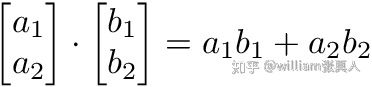
Dot product of 2 matrices.
按照Jeremy的建议,使用excel,我们的输入矩阵是函数f(),滑动窗口矩阵是滤波函数g()。 点积是excel中2个矩阵的和积,如下所示。
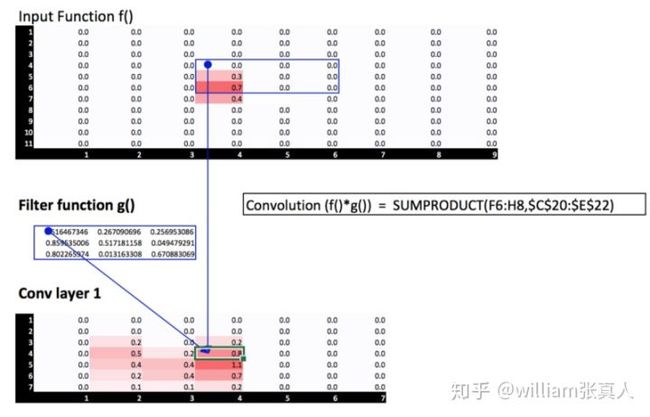
Convolution of 2 matrices.
让我们将其扩展为字母“A”的图像。 我们知道任何图像都是由像素组成的。 所以我们的输入矩阵f是“A”。 我们选择滑动窗函数为随机矩阵g。 然后,该矩阵的点积的回旋输出如下所示。

什么是卷积神经网络CNN?
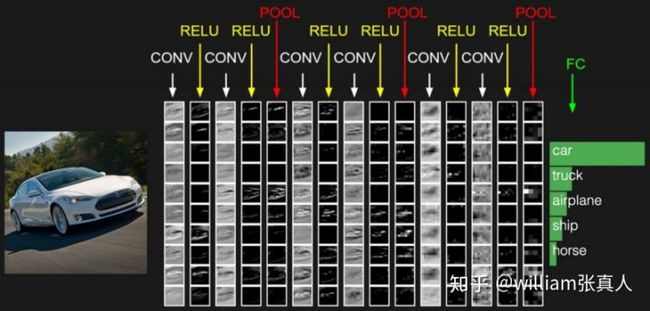
Source: cs231n.github.io/convolutional-networks/
在我看来,简单的卷积神经网络(CNN)是一系列层。 每一层都有一些特定的功能。 每个卷积层都是3维的,因此我们使用volume作为度量。 此外,CNN的每一层通过可微分函数将一个体积的激活转换为另一个体积。 这种功能称为激活或传递功能。
CNN的不同类型的实体是:输入,过滤器(或内核),卷积层,激活层,池化层和批量标准化层。 这些层以不同的排列组合,当然有些规则为我们提供了不同的深度学习架构。
输入层:CNN的常用输入是n维数组。 对于图像,我们输入了3个维度 - 长度,宽度和深度(这是颜色通道)
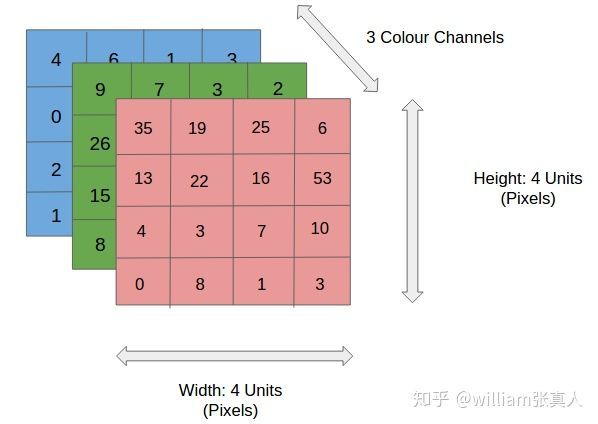
Source: http://xrds.acm.org/blog/2016/06/convolutional-neural-networks-cnns-illustrated-explanation/
过滤器或内核:如下图l所示,过滤器或内核滑动到图像的每个位置,并计算一个新像素作为这些像素的加权和。 在我们上面的excel示例中,我们的滤波器是g,在输入矩阵f上移动。
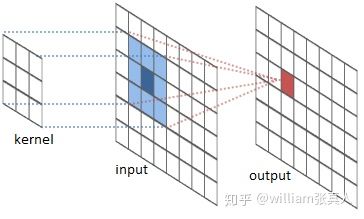
source: intellabs.github.io/RiverTrail/tutorial/
卷积层:输入矩阵和内核的点积产生一个新的矩阵,称为卷积矩阵或层。
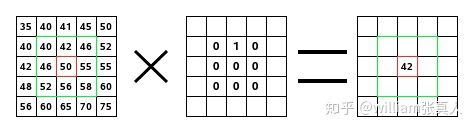
Source: https://docs.gimp.org/en/plug-in-convmatrix.html
可以在下面找到一个非常好的视觉图表,了解如何填充,跨步和转置。
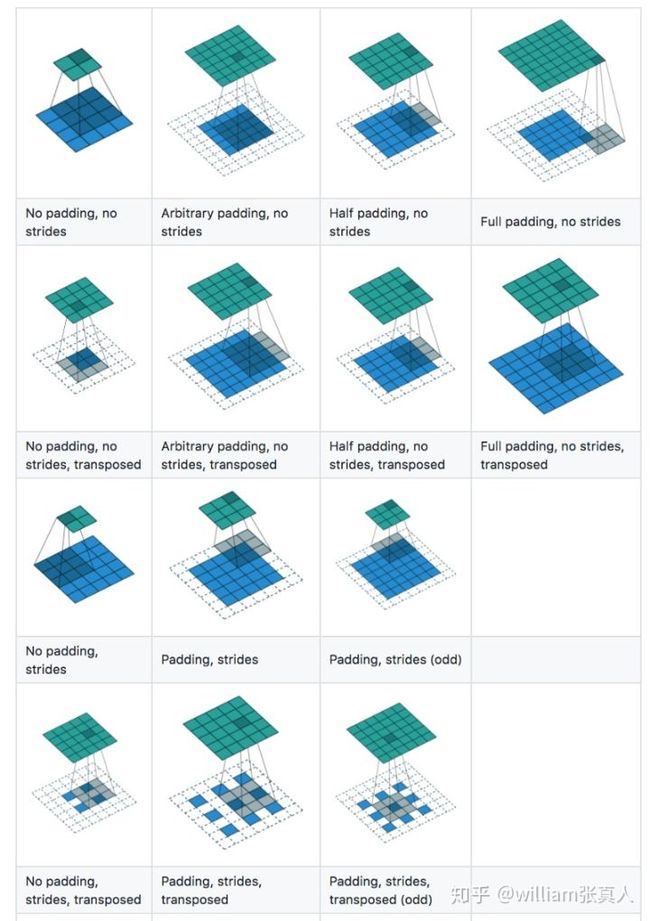
Source: https://github.com/vdumoulin/conv_arithmetic
激活层:激活功能可以分为两类 - 饱和和不饱和。
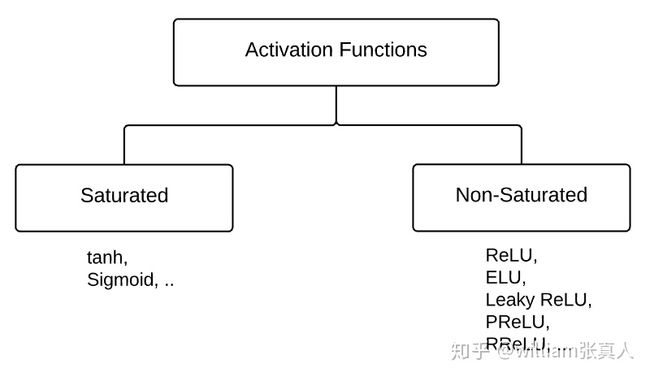
饱和激活函数有sigmoid和tanh,而非饱和激活函数是ReLU及其变体。使用非饱和激活函数的优点在于两个方面:
首先是解决所谓的“爆炸/消失梯度”。
第二是加快收敛速度。
Sigmoid:获取实值输入并将其压缩到[0,1]之间的范围
σ(x)= 1 /(1 + exp(-x))
tanh:获取实值输入并将其压缩到范围[-1,1]
tanh(x)=2σ(2x) - 1
RELU
ReLU全程叫整流线性单元。它是输入为x的最大函数(x,0),例如来自卷积图像的矩阵。然后,ReLU将矩阵x中的所有负值设置为零,并且所有其他值保持不变.ReLU在卷积之后计算,因此是非线性激活函数,如tanh或sigmoid。这是Geoff Hinton在他的nature报纸中首次讨论的。
ELUs
指数线性单位试图使平均激活接近于零,加速学习速度。 ELU同样通过正值的标识避免消失的梯度。从下图可以看出,ELU比ReLU获得更高的分类精度。
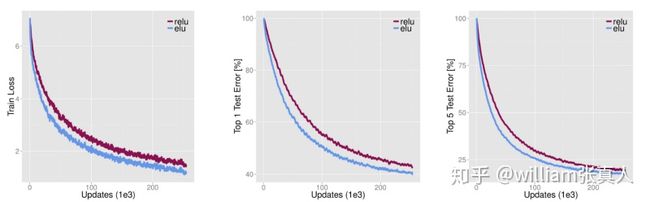
Source: http://image-net.org/challenges/posters/JKU_EN_RGB_Schwarz_poster.pdf [15 layer CNN with stacks of (1×96×6, 3×512×3, 5×768×3, 3×1024×3, 2×4096×FC, 1×1000×FC) layers×units×receptive fields or fully-connected (FC). 2×2 max-pooling with a stride of 2 after each stack, spatia
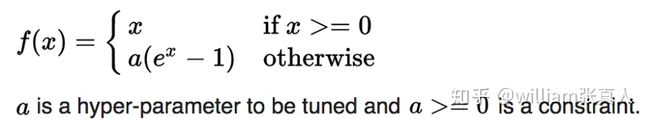
Source: Wikipedia.
Leaky ReLUs
与ReLU相反,relu完全舍掉负数部分,leaky ReLU则为其指定非零斜率。 泄漏整流线性激活首先在声学模型中引入(Maas等,2013)。 在数学上,我们有:
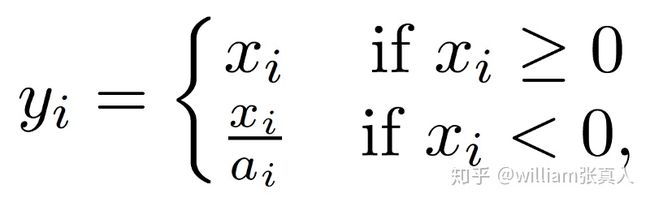
Source: Empirical Evaluation of Rectified Activations in Convolution Network.
其中ai是范围内的固定参数(1,+无穷大)。
参数整流线性单元(PReLU)
PReLU可以被视为Leaky ReLU的变种。 在PReLU中,负面部分的斜率是从数据中学习而不是预定义的。 作者声称,PReLU是超越ImageNet分类(Russakovsky等,2015)任务的人类表现的关键因素。 除了ai是通过反向传播在训练中学习,PReLU与ReLU相同。
随机泄漏整流线性单元(RReLU)
随机整流线性单元(RReLU)也是Leaky ReLU的变体。 在RReLU中,负部分的斜率在训练中的给定范围内随机化,然后在测试中固定。 RReLU的亮点在于,在训练过程中,aji是从均匀分布U(l,u)中采样的随机数。 在形式上:
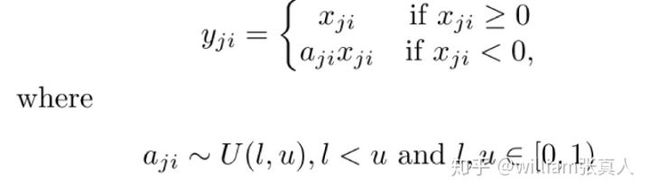
ReLU,Leaky ReLU,PReLU和RReLU之间的比较如下所示。
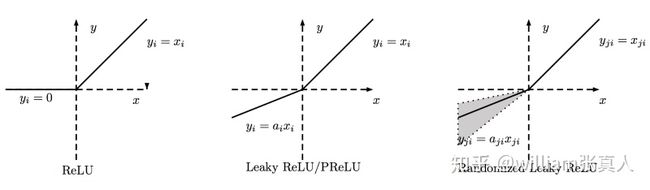
Source :https://arxiv.org/pdf/1505.00853.pdf ReLU, Leaky ReLU, PReLU and RReLU. For PReLU, ai is learned and for Leaky ReLU ai is fixed. For RReLU, aji is a random variable keeps sampling in a given range, and remains fixed in testing.
噪声激活函数
这些激活函数,扩展到包括高斯噪声。 在这里可以找到关于噪声如何帮助的良好理解。
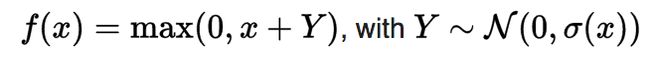
Source: Wikipedia.
池化层(Pooling layer)
池化层的目标是逐渐减小矩阵的空间大小,以减少网络中的参数和计算量,从而也控制过度拟合。 Pooling Layer在输入的每个深度切片上独立运行,并使用MAX或Average操作在空间上调整其大小。 最常见的形式是一个池化层,其过滤器大小为2*2,步长为2,沿着宽,高,输入为2,对每个深度切片进行降低采样,丢弃75%的激活。 在这种情况下,每个MAX操作将采用最多超过4个数字(在某个深度切片中的小2x2区域)。 深度维度保持不变。 简单来说,池化层:
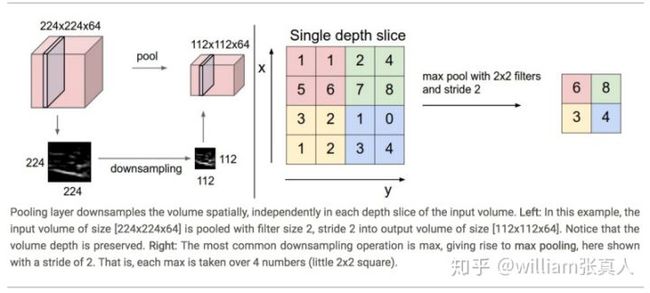
Source: http://cs231n.github.io/convolutional-networks/#pool
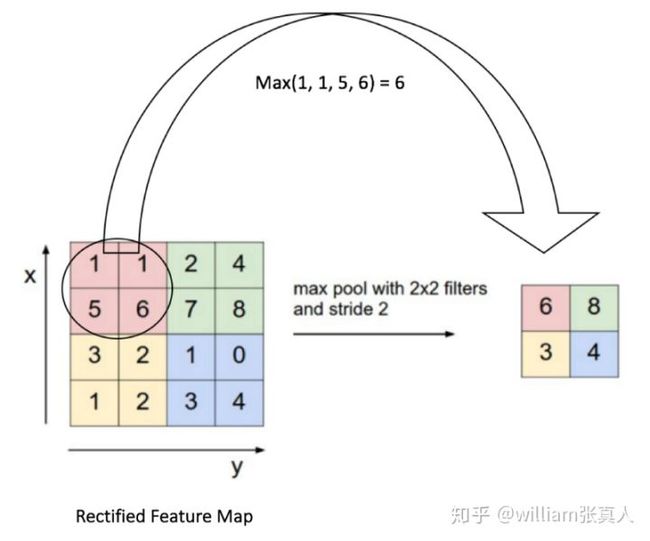
Source: https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
注意:这里我们以步长为2,滑动2*2的窗口并且去该区域最大值。
批量标准化层 Batch Normalization layer:
批量标准化是标准化每个中间层的有效方式,包括权重和激活函数。 batchnorm有两个主要的好处:
将batchnorm添加到模型中可以使训练速度提高10倍或更多
由于归一化极大地降低了少量外围输入过度影响训练的能力,因此也倾向于减少过度拟合。
全连接层 fully connected layer
完全连接层是传统的多层感知器,在输出层使用softmax激活函数。 术语“完全连接”意味着前一层中的每个神经元都连接到下一层的每个神经元。 softmax函数是泛华函数的推广,其将任意实数值的K维向量“压缩”到范围(0,1)中的实数值的K维向量,其加起来为1。
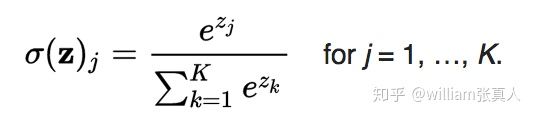
Source: Wikipedia
Softmax激活通常用于最终的完全连接层,以获得概率,它的值为0到1之间。
现在,我们了解CNN中的不同层。 有了这些知识,我们将在下一篇文章中使用Keras开发肺癌检测所需的深度学习架构。
参考:
- Jeremy Howard’s MOOC (course.fast.ai)
- http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
- https://medium.com/towards-data-science/linear-algebra-cheat-sheet-for-deep-learning-cd67aba4526c
- https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
- https://medium.com/technologymadeeasy/the-best-explanation-of-convolutional-neural-networks-on-the-internet-fbb8b1ad5df8
- http://image-net.org/challenges/posters/JKU_EN_RGB_Schwarz_poster.pdf