深入理解读写锁ReentrantReadWriteLock和并发容器CopyOnWriteArrayList
1.读写锁的介绍
在并发场景中用于解决线程安全的问题,我们几乎会高频率的使用到独占式锁,通常使用jvm提供的关键字synchronized或者juc中实现了Lock接口的ReentrantLock。它们都是独占式获取锁,也就是在同一时刻只有一个线程能够获取锁。而在一些业务场景中,大部分只是读数据,写数据很少,如果仅仅是读数据的话并不会影响数据正确性(出现脏读),而如果在这种业务场景下,依然使用独占锁的话,很显然这将是出现性能瓶颈的地方。针对这种读多写少的情况,java还提供了另外一个实现Lock接口的ReentrantReadWriteLock(读写锁)。读写所允许同一时刻被多个读线程访问,但是在写线程访问时,所有的读线程和其他的写线程都会被阻塞。在分析WirteLock和ReadLock的互斥性时可以按照WriteLock与WriteLock之间,WriteLock与ReadLock之间以及ReadLock与ReadLock之间进行分析。这里简要做一个归纳总结:
- 公平性选择:支持非公平性(默认)和公平的锁获取方式,吞吐量还是非公平优于公平;
- 重入性:支持重入,读锁获取后能再次获取,写锁获取之后能够再次获取写锁,同时也能够获取读锁;
- 锁降级:遵循获取写锁,获取读锁再释放写锁的次序,写锁能够降级成为读锁
要想能够彻底的理解读写锁必须能够理解这样几个问题:1. 读写锁是怎样实现分别记录读写状态的?2. 写锁是怎样获取和释放的?3.读锁是怎样获取和释放的?我们带着这样的三个问题,再去了解下读写锁。
2.写锁详解
2.1.写锁的获取
同步组件的实现聚合了同步器(AQS),并通过重写同步器(AQS)中的方法实现同步组件的同步语义。因此,写锁的实现依然也是采用这种方式。在同一时刻写锁是不能被多个线程所获取,很显然写锁是独占式锁,而实现写锁的同步语义是通过重写AQS中的tryAcquire方法实现的。源码为:
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
Thread current = Thread.currentThread();
// 1. 获取写锁当前的同步状态
int c = getState();
// 2. 获取写锁获取的次数
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
// 3.1 当读锁已被读线程获取或者当前线程不是已经获取写锁的线程的话
// 当前线程获取写锁失败
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
// 3.2 当前线程获取写锁,支持可重复加锁
setState(c + acquires);
return true;
}
// 3.3 写锁未被任何线程获取,当前线程可获取写锁
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}
这段代码的逻辑请看注释,这里有一个地方需要重点关注,exclusiveCount( c )方法,该方法源码为:
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
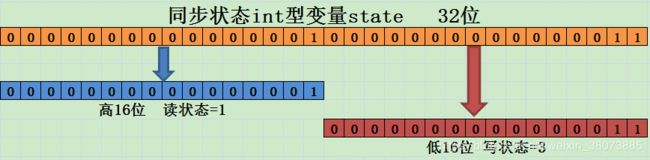
其中EXCLUSIVE_MASK为: static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1; EXCLUSIVE _MASK为1左移16位然后减1,即为0x0000FFFF。而exclusiveCount方法是将同步状态(state为int类型)与0x0000FFFF相与,即取同步状态的低16位。那么低16位代表什么呢?根据exclusiveCount方法的注释为独占式获取的次数即写锁被获取的次数,现在就可以得出来一个结论同步状态的低16位用来表示写锁的获取次数。同时还有一个方法值得我们注意:
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
该方法是获取读锁被获取的次数,是将同步状态(int c)右移16次,即取同步状态的高16位,现在我们可以得出另外一个结论同步状态的高16位用来表示读锁被获取的次数。现在还记得我们开篇说的需要弄懂的第一个问题吗?读写锁是怎样实现分别记录读锁和写锁的状态的,现在这个问题的答案就已经被我们弄清楚了,其示意图如下图所示:
2.2.写锁的释放
写锁释放通过重写AQS的tryRelease方法,源码为:
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
//1. 同步状态减去写状态
int nextc = getState() - releases;
//2. 当前写状态是否为0,为0则释放写锁
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
//3. 不为0则更新同步状态
setState(nextc);
return free;
}
源码的实现逻辑请看注释,不难理解与ReentrantLock基本一致,这里需要注意的是,减少写状态 int nextc = getState() - releases;只需要用当前同步状态直接减去写状态的原因正是我们刚才所说的写状态是由同步状态的低16位表示的。
3.读锁详解
3.1.读锁的获取
看完了写锁,现在来看看读锁,读锁不是独占式锁,即同一时刻该锁可以被多个读线程获取也就是一种共享式锁。按照之前对AQS介绍,实现共享式同步组件的同步语义需要通过重写AQS的tryAcquireShared方法和tryReleaseShared方法。读锁的获取实现方法为:
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
Thread current = Thread.currentThread();
int c = getState();
//1. 如果写锁已经被获取并且获取写锁的线程不是当前线程的话,当前
// 线程获取读锁失败返回-1
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
//2. 当前线程获取读锁
compareAndSetState(c, c + SHARED_UNIT)) {
//3. 下面的代码主要是新增的一些功能,比如getReadHoldCount()方法
//返回当前获取读锁的次数
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
//4. 处理在第二步中CAS操作失败的自旋已经实现重入性
return fullTryAcquireShared(current);
}
代码的逻辑请看注释,需要注意的是 当写锁被其他线程获取后,读锁获取失败,否则获取成功利用CAS更新同步状态。另外,当前同步状态需要加上SHARED_UNIT((1 << SHARED_SHIFT)即0x00010000)的原因这是我们在上面所说的同步状态的高16位用来表示读锁被获取的次数。如果CAS失败或者已经获取读锁的线程再次获取读锁时,是靠fullTryAcquireShared方法实现的,这段代码就不展开说了,有兴趣可以看看。
3.2.读锁的释放
读锁释放的实现主要通过方法tryReleaseShared,源码如下,主要逻辑请看注释:
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
// 前面还是为了实现getReadHoldCount等新功能
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1)
firstReader = null;
else
firstReaderHoldCount--;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
--rh.count;
}
for (;;) {
int c = getState();
// 读锁释放 将同步状态减去读状态即可
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}
4.锁降级
读写锁支持锁降级,遵循按照获取写锁,获取读锁再释放写锁的次序,写锁能够降级成为读锁,不支持锁升级,关于锁降级下面的示例代码摘自ReentrantWriteReadLock源码中:
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// Must release read lock before acquiring write lock
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// Recheck state because another thread might have
// acquired write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// Downgrade by acquiring read lock before releasing write lock
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock(); // Unlock write, still hold read
}
}
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}
5. CopyOnWriteArrayList的简介
java学习者都清楚ArrayList并不是线程安全的,在读线程在读取ArrayList的时候如果有写线程在写数据的时候,基于fast-fail机制,会抛出ConcurrentModificationException异常,也就是说ArrayList并不是一个线程安全的容器,当然您可以用Vector,或者使用Collections的静态方法将ArrayList包装成一个线程安全的类,但是这些方式都是采用java关键字synchronzied对方法进行修饰,利用独占式锁来保证线程安全的。但是,由于独占式锁在同一时刻只有一个线程能够获取到对象监视器,很显然这种方式效率并不是太高。
回到业务场景中,有很多业务往往是读多写少的,比如系统配置的信息,除了在初始进行系统配置的时候需要写入数据,其他大部分时刻其他模块之后对系统信息只需要进行读取,又比如白名单,黑名单等配置,只需要读取名单配置然后检测当前用户是否在该配置范围以内。类似的还有很多业务场景,它们都是属于读多写少的场景。如果在这种情况用到上述的方法,使用Vector,Collections转换的这些方式是不合理的,因为尽管多个读线程从同一个数据容器中读取数据,但是读线程对数据容器的数据并不会发生发生修改。联系上文我们讲过的读写锁ReenTrantReadWriteLock,通过读写分离的思想,使得读读之间不会阻塞,无疑如果一个list能够做到被多个读线程读取的话,性能会大大提升不少。但是,如果仅仅是将list通过读写锁(ReentrantReadWriteLock)进行再一次封装的话,由于读写锁的特性,当写锁被写线程获取后,读写线程都会被阻塞。如果仅仅使用读写锁对list进行封装的话,这里仍然存在读线程在写数据的时候被阻塞的情况,如果想list的读效率更高的话,这里就是我们的突破口,如果我们保证读线程无论什么时候都不被阻塞,效率岂不是会更高?
思考如果简单的使用读写锁的话,在写锁被获取之后,读写线程被阻塞,只有当写锁被释放后读线程才有机会获取到锁从而读到最新的数据,站在读线程的角度来看,即读线程任何时候都是获取到最新的数据,满足数据实时性。既然我们说到要进行优化,必然有trade-off,我们就可以牺牲数据实时性满足数据的最终一致性即可。而CopyOnWriteArrayList就是通过Copy-On-Write(COW),即写时复制的思想来通过延时更新的策略来实现数据的最终一致性,并且能够保证读线程间不阻塞。
COW通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。对CopyOnWrite容器进行并发的读的时候,不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,延时更新的策略是通过在写的时候针对的是不同的数据容器来实现的,放弃数据实时性达到数据的最终一致性。
6. CopyOnWriteArrayList的实现原理
现在我们来通过看源码的方式来理解CopyOnWriteArrayList,实际上CopyOnWriteArrayList内部维护的就是一个数组
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
并且该数组引用是被volatile修饰,注意这里仅仅是修饰的是数组引用,其中另有玄机,稍后揭晓。关于volatile很重要的一条性质是它能够够保证可见性。对list来说,我们自然而然最关心的就是读写的时候,分别为get和add方法的实现。
6.1 get方法实现原理
get方法的源码为:
public E get(int index) {
return get(getArray(), index);
}
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
可以看出来get方法实现非常简单,几乎就是一个“单线程”程序,没有对多线程添加任何的线程安全控制,也没有加锁也没有CAS操作等等,原因是,所有的读线程只是会读取数据容器中的数据,并不会进行修改。
6.2 add方法实现原理
再来看下如何进行添加数据的?add方法的源码为:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
//1. 使用Lock,保证写线程在同一时刻只有一个
lock.lock();
try {
//2. 获取旧数组引用
Object[] elements = getArray();
int len = elements.length;
//3. 创建新的数组,并将旧数组的数据复制到新数组中
Object[] newElements = Arrays.copyOf(elements, len + 1);
//4. 往新数组中添加新的数据
newElements[len] = e;
//5. 将旧数组引用指向新的数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
add方法的逻辑也比较容易理解,请看上面的注释。需要注意这么几点:
- 采用ReentrantLock,保证同一时刻只有一个写线程正在进行数组的复制,否则的话内存中会有多份被复制的数据;
- 前面说过数组引用是volatile修饰的,因此将旧的数组引用指向新的数组,根据volatile的happens-before规则,写线程对数组引用的修改对读线程是可见的。
- 由于在写数据的时候,是在新的数组中插入数据的,从而保证读写实在两个不同的数据容器中进行操作。
7. 总结
我们知道COW和读写锁都是通过读写分离的思想实现的,但两者还是有些不同,可以进行比较:
COW vs 读写锁
相同点:1. 两者都是通过读写分离的思想实现;2.读线程间是互不阻塞的
不同点:对读线程而言,为了实现数据实时性,在写锁被获取后,读线程会等待或者当读锁被获取后,写线程会等待,从而解决“脏读”等问题。也就是说如果使用读写锁依然会出现读线程阻塞等待的情况。而COW则完全放开了牺牲数据实时性而保证数据最终一致性,即读线程对数据的更新是延时感知的,因此读线程不会存在等待的情况。
前面我们对比读写锁 说明了CopyOnWrite的优点,当然他也有自己的缺点:即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
- 内存占用问题:因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对 象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对 象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比 如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的minor GC和major GC。
- 数据一致性问题:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。