Netty-ByteBuf
ByteBuf
由于NIO编程的复杂性,ByteBuffer也有其局限性,主要缺点如下:
- ByteBuffer长度固定,一旦分配成功,容量无法动态扩展或者伸缩,当需要编码的POJO对象大于ByteBuffer容量,会出现越界
- ByteBuffer只有一个标识位置的指针position,读写的时候需要不断地手工调用flip()和rewind()等,否则很容易导致程序失败
- ByteBuffer的API功能不够齐全
ByteBuf的工作原理
ByteBuf依然是Byte数组的缓冲区,Netty中ByteBuf的实现有两种策略:
- 参考JDK的ByteBuffer的实现,增加额外的功能
- 聚合JDK的ByteBuffer,痛过Facade模式对其进行包装,减少自身代码量,降低实现成本
缓冲区的优化
ByteBuffer只有一个位置指针用于处理读写操作,而ByteBuf通过两个位置指针来协助缓冲区的读写操作,读操作用readerIndex,写操作用writeIndex。
readerIndex和writerIndex的取值一开始都是0,随着数的写入writerIndex会增加,读取数据会使readerIndex增加,但是它不会超过writerIndex。在读取之后,0~readerIndex的就被视为discard,调用discardReadBytes方法,可以释放着部分空间,相当于ByteBuffer的compact方法。readerIndex和writerIndex之间的数据是可读的,相等于ByteBuffer的position和limit之间的数据。writerIndex和capacity之间的空间是可写的,相当于ByteBuffer的limit和capacity之间的可用空间。
由于写操作不修改readerIndex指针,读操作不修改writerIndex指针,因此读写之间不再需要调整位置指针,极大地简化了缓冲区的读写操作

ps:0到readerIndex之间是已经读取过的缓冲区,可用调用discardReadBytes操作来重用这一部分,以节约内存,防止ByteBuf的动态扩张
动态扩展
通常情况下,当我们对ByteBuffer进行put操作,如果缓冲区剩余可写空间不够,就会发生BufferOverflowException。ByteBuf对write操作进行了封装,由ByteBuf的write操作辅助进行剩余空间的检验,如果可用缓冲区(也就是writerIndex之后的空间)不足,ByteBuf会自动进行动态扩展。
public int writeBytes(InputStream in, int length) throws IOException {
//判断剩余空间
this.ensureWritable(length);
int writtenBytes = this.setBytes(this.writerIndex, in, length);
if (writtenBytes > 0) {
this.writerIndex += writtenBytes;
}
return writtenBytes;
}
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format("minWritableBytes: %d (expected: >= 0)", minWritableBytes));
} else if (minWritableBytes <= this.writableBytes()) {
return this;
} else if (minWritableBytes > this.maxCapacity - this.writerIndex) {
throw new IndexOutOfBoundsException(String.format("writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s", this.writerIndex, minWritableBytes, this.maxCapacity, this));
} else {
int newCapacity = this.calculateNewCapacity(this.writerIndex + minWritableBytes);
this.capacity(newCapacity);
return this;
}
}
常用操作
Discardable bytes
相比于其他Java对象,缓冲区的分配和释放是个耗时的操作,我们应该尽量重用它们。由于缓冲区的动态扩张需要进行字节数组的复制,是个耗时操作,为了提高性能,我们需要尽可能提升缓冲区的重用率。
假如缓冲区包含了N个整包消息,每个消息的长度为L,消息的可写字节数为R。当读取M个整包消息后,如果不对ByteBuf做压缩或者discardReadBytes操作,则可写的缓冲区长度依然为R。如果调用discardReadBytes操作,则可写的字节数会变为R = (R + M * L),之前已经读取的M个整包的空间会被重用。
ByteBuf的discardReadBytes操作之前:

操作之后:

Clear
Clear操作不会清空缓冲区内容本身,主要用来操作位置指针,如readerIndex和writerIndex,将它们还原为初始值。
Clear操作之前:

操作之后:

Mark和Rest
当对缓冲区进行读操作时,可能需要对之前的操作进行回滚。读操作不会改变缓冲区的内容,回滚操作主要是为了重新设置索引信息
对于JDK中的ByteBuffer,调用mark操作会将当前位置指针备份到mark变量中,当调用rest操作后,重新将指针的当前位置恢复为mark中的值。
Netty的ByteBuf也有类似的rest和mark接口,因为ByteBuf有读索引和写索引,对应此操作就有四种方法
- markReaderIndex
- restReaderIndex
- markWriterIndex
- restWriterIndex
public ByteBuf markReaderIndex() {
this.markedReaderIndex = this.readerIndex;
return this;
}
public ByteBuf resetReaderIndex() {
this.readerIndex(this.markedReaderIndex);
return this;
}
public ByteBuf markWriterIndex() {
this.markedWriterIndex = this.writerIndex;
return this;
}
public ByteBuf resetWriterIndex() {
this.writerIndex = this.markedWriterIndex;
return this;
}
Derived buffers
类似数据库的视图,ByteBuf提供多个接口用于创建某个ByteBuf的视图或者复制ByteBuf
- duplicate:返回当前ByteBuf的复制对象,复制后返回的ByteBuf与操作的ByteBuf共享缓冲区的内容,但是维护自己独立的索引。当修改复制后的ByteBuf的内容之后,之前原ByteBuf的内容也随之改变。
- copy:复制一个新的ByteBuf对象,它的内容和索引都是独立的,复制操作不修改原ByteBuf的读写索引
- copy(int index,int length)
- slice:返回当前ByteBuf的可读子缓冲区,起始位置从readerIndex到writerIndex,返回的ByteBuf与原ByteBuf共享内容,但是读写索引独立维护。该操作不修改原ByteBuf的索引位置
- slice(int index,int length)
*如何将ByteBuf转换成ByteBuffer
- ByteBuffer.nioBuffer():将当前ByteBuf可读的缓冲区转换成ByteBuffer,两者共享同一个缓冲区内容引用,对ByteBuffer的读写操作不会修改原ByteBuf的读写索引,返回后的ByteBuffer无法感知原ByteBuf的动态扩展操作
- ByteBuffer.nioBuffer(int index,int length)
ByteBuf源码分析
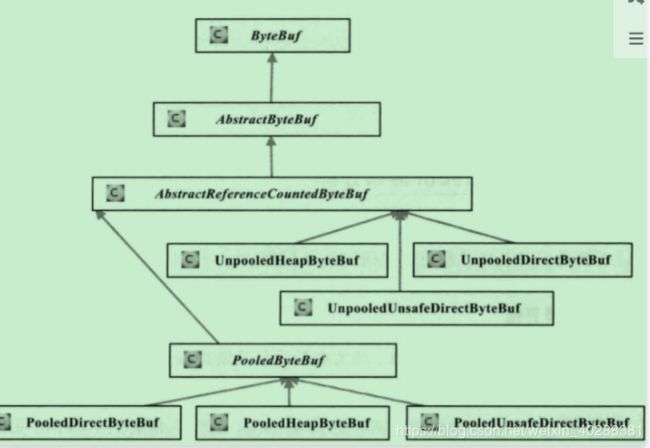
1.从内存分配的角度来看,ByteBuf可以分为两类:
- 堆内存字节缓冲区:特点是内存的分配和回收速度快,可以被JVM自动回收,缺点就是如果进行Socket的IO读写,需要额外做一次内存复制,将堆内存的缓冲区复制到内核Channel中,性能会有一定程度的下降。(ps:解释下为什么需要内存复制:堆是用户空间的一部分,系统为了数据的安全,当内核需要数据时,往往不是直接调用用户空间的数据,而是先让用户空间内的数据复制一份,内核再去新数据的地址读取)
- 直接内存字节缓冲区:在堆外进行内存分配,相比于堆内存,分配和回收的速度会慢一点,但是写入或者读取Channle时会更快
经验表明:ByteBuf的最佳实践是在IO通信的线程的读写缓冲区使用直接内存,后端业务消息的编解码模块使用堆内存
2.从回收的角度看,ByteBuf也可以分为两类:
- 基于对象池的ByteBuf:可以重用ByteBuf对象,维护内存池,可以循环利用创建的ByteBuf
- 普通ByteBuf
3.从Unsafe和非Unsafe分类
AbstractByteBuf源码分析
主要成员变量
//leakDetector被定义为static,意味着所有的ByteBuf实例共享一个ResourceLeakDetector对象,这个对象用于检测对象是否内存泄漏
static final ResourceLeakDetector<ByteBuf> leakDetector = new ResourceLeakDetector(ByteBuf.class);
读操作簇
public ByteBuf readBytes(ByteBuf dst, int dstIndex, int length) {
this.checkReadableBytes(length);//读之前,首先对缓冲区的可用空间进行校验
this.getBytes(this.readerIndex, dst, dstIndex, length);//校验通过,调用getBytes方法,从当前读索引开始,复制length个字节到目标byte数组中
this.readerIndex += length;//维护读索引
return this;
}
protected final void checkReadableBytes(int minimumReadableBytes) {
this.ensureAccessible();
if (minimumReadableBytes < 0) {//如果读取的长度小于0,则抛出异常
throw new IllegalArgumentException("minimumReadableBytes: " + minimumReadableBytes + " (expected: >= 0)");
} else if (this.readerIndex > this.writerIndex - minimumReadableBytes) {//如果可读的字节数小于需要读取的长度,则抛出异常
throw new IndexOutOfBoundsException(String.format("readerIndex(%d) + length(%d) exceeds writerIndex(%d): %s", this.readerIndex, minimumReadableBytes, this.writerIndex, this));
}
}
写操作簇
public ByteBuf writeBytes(ByteBuf src, int srcIndex, int length) {
this.ensureWritable(length);//计算动态扩张的容量
this.setBytes(this.writerIndex, src, srcIndex, length);//重新创建缓冲区
this.writerIndex += length;//维护写索引
return this;
}
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format("minWritableBytes: %d (expected: >= 0)", minWritableBytes));
} else if (minWritableBytes <= this.writableBytes()) {
return this;
} else if (minWritableBytes > this.maxCapacity - this.writerIndex) {//如果写入的字节数组长度大于可以动态扩展的最大可写字节数,则抛出异常
throw new IndexOutOfBoundsException(String.format("writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s", this.writerIndex, minWritableBytes, this.maxCapacity, this));
} else {//如果当前写入的字节数组虽然大于目前的ByteBuf的可写字节数,但是可以通过动态扩展满足,则进行动态扩展
int newCapacity = this.calculateNewCapacity(this.writerIndex + minWritableBytes);//计算新的容量
this.capacity(newCapacity);
return this;
}
}
/**
* 首先设置门限阈值为4M(用于倍增和步进的分界值),当需要的新容量正好等于门限阈值,则使用阈值作为新的缓冲区容量。
* 如果新申请的内存空间大于阈值,不能采用倍增的方式(防止内存膨胀和浪费)扩张内存,采用每次
* 步进4M的方式进行内存扩张。扩张的时候需要对扩张后的内存和最大内存(maxCapacity)比较,如果
* 大于缓冲区的最大长度,则使用maxCapacity作为扩容后的缓冲区容量
* 如果扩容后的新容量小于阈值,则以64为计数进行倍增,直到倍增后的结果大于或等于需要的容量值
*
* 采用倍增或者步进算法的原因如下:如果仅仅以minNewCapaciy作为目标容量,则本次扩容后的可写
* 字节刚好够本次写入使用。写入完成后,它的可写字节数会变为0,下次做写入操作时,需要再次动态
* 扩张,而频繁的内存复制会导致性能下降
* 采用先倍增后步进的原因如下:当内存比较小的时候,倍增操作并不会带来太多内存浪费,例如64字
* 节-128节字-156字节。但是,当内存增长到一定阈值后,再进行倍增就可能会带来额外的内存浪费,
* 如10M-20M-40M。因此达到某个阈值后就需要以步进的方式对内存进行平滑地扩张
*/
private int calculateNewCapacity(int minNewCapacity) {
int maxCapacity = this.maxCapacity;
int threshold = 4194304;
if (minNewCapacity == 4194304) {
return 4194304;
} else {
int newCapacity;
if (minNewCapacity > 4194304) {
newCapacity = minNewCapacity / 4194304 * 4194304;
if (newCapacity > maxCapacity - 4194304) {//如果newCapacity大于maxCapacity - 4M。说明超出增大的长度了,最大只能maxCapacity
newCapacity = maxCapacity;
} else {
newCapacity += 4194304;
}
return newCapacity;
} else {
for(newCapacity = 64; newCapacity < minNewCapacity; newCapacity <<= 1) {
}
return Math.min(newCapacity, maxCapacity);
}
}
}
重用缓冲区
public ByteBuf discardReadBytes() {
this.ensureAccessible();
if (this.readerIndex == 0) {//首先对读索引进行判断,如果为0则说明没有可重用的缓冲区,直接返回
return this;
} else {
/*
* 说明缓冲区中既有已经读取过的被废弃的缓冲区,也有尚未读取的缓冲区
* 调用setBytes()方法进行字节数组复制,将尚未读取的字节数组复制到缓冲区的起始位置,然后
* 重新设置读写索引,读索引设置为0,写索引设置为值之前的写索引长度减去读索引(重用的缓
* 冲区长度)
*/
if (this.readerIndex != this.writerIndex) {
this.setBytes(0, this, this.readerIndex, this.writerIndex - this.readerIndex);
this.writerIndex -= this.readerIndex;
/**
*设置读写索引的同时,需要同时调整markedReaderIndex和markedWriterIndex
*
*/
this.adjustMarkers(this.readerIndex);
this.readerIndex = 0;
} else {
this.adjustMarkers(this.readerIndex);
this.writerIndex = this.readerIndex = 0;
}
return this;
}
}
/**
*首先对备份的markedReaderIndex、markedWriterIndex、和需要减少的decrement进行判断,如果小
*于需要减少的值,则置为0;否则新值为旧值减去decrement之后的值
*
*/
protected final void adjustMarkers(int decrement) {
int markedReaderIndex = this.markedReaderIndex;
if (markedReaderIndex <= decrement) {
this.markedReaderIndex = 0;
int markedWriterIndex = this.markedWriterIndex;
if (markedWriterIndex <= decrement) {
this.markedWriterIndex = 0;
} else {
this.markedWriterIndex = markedWriterIndex - decrement;
}
} else {
this.markedReaderIndex = markedReaderIndex - decrement;
this.markedWriterIndex -= decrement;
}
}
AbstractReferenceCountedByteBuf源码分析
从类的名字就可以看出该类主要是对引用进行计数,类似于JVM内存回收的对象引用计数器,用于跟踪对象的分配和销毁,做自动内存回收。
成员变量
//refCntUpater是AtomicIntegerFieldUpdater类型变量,通过原子的方式对成员变量进行更新等操作,实现线程安全
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> refCntUpdater = AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
//用于标识refCnt字段在AbstractReferenceCountedByteBuf中的内存地址
private static final long REFCNT_FIELD_OFFSET;
//跟踪对象的引用次数
private volatile int refCnt = 1;
对象引用计数器
//CAS操作
public ByteBuf retain() {
int refCnt;
do {
refCnt = this.refCnt;
if (refCnt == 0) {
throw new IllegalReferenceCountException(0, 1);
}
if (refCnt == 2147483647) {
throw new IllegalReferenceCountException(2147483647, 1);
}
} while(!refCntUpdater.compareAndSet(this, refCnt, refCnt + 1));
return this;
}
释放引用计数器
public final boolean release() {
int refCnt;
do {
refCnt = this.refCnt;
if (refCnt == 0) {
throw new IllegalReferenceCountException(0, -1);
}
} while(!refCntUpdater.compareAndSet(this, refCnt, refCnt - 1));
if (refCnt == 1) {//等于1意味着申请和释放相等,说明对象引用已经不可达,需要被释放
this.deallocate();
return true;
} else {
return false;
}
}
内存池相关
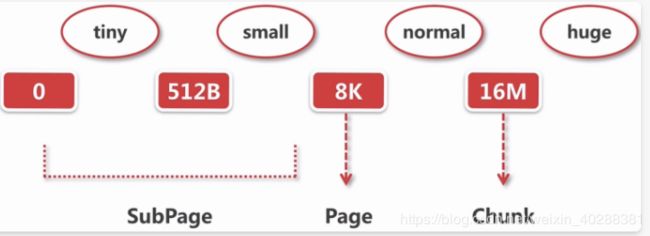
PoolArea
Arena本身是指一块区域,在内存管理中,Memory Arena是指内存中的一大块连续的区域,PoolArena就是Netty的内存池实现类。
Netty的PoolArea是由多个Chunk组成的大块内存区域,而每个Chunk则由一个或者多个Page组成,因此对内存的组织和管理主要集中在如何管理和组织Chunk和Page了
PoolChunk
Chunk主要用来组织和管理多个Page的内存分配和释放,在Netty中,Chunk中的Page被构建成一棵二叉树。
假设一个Chunk由16个Page组成,这些Page会按照下图的形式组织起来:
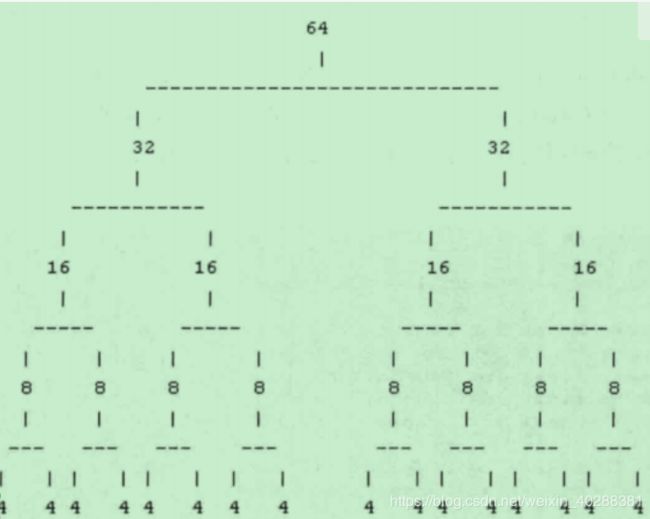
Page的大小是4个字节,Chunk的大小是64个字节(4 * 16)。整棵树有5层,第1层(也就是叶子节点所在的层)用来分配所有Page的内存,第4层用来分配2个Pager的内存。
每个节点都记录了自己在整个Memory Arena中的偏移地址,当一个节点代表的内存区域被分配出去之后,这个节点就会被标记为已分配,自这个节点以下的所有节点在后面的内存分配请求都会被忽略。
PoolSubPage
对于小于一个Page的内存,Netty在Page中完成分配。每个Page都会被切分成大小相等的多个存储块,存储块的大小是由第一次申请的内存块大小决定的。例如一个Page是8个字节,如果第一次申请的块是4个字节,那么这个Page就包含2个存储块;如果第一次申请的是8个字节,那么这个Page就被分配成1个存储块。
Page中存储区域的使用状态通过一个long数组维护,数组中的每一位表示每块存储区域的占用情况:0表示未占用,1表示已占用。
内存回收策略
无论是Chunk还是Page,都通过状态位来标识内存是否可用,不同之处在于Chunk通过二叉树对节点进行标识实现,Page是通过维护块的使用状态来标识实现。
内存分配器ByteBufAllocator
ByteBufAllocator是字节缓冲区分配器,按照Netty的缓冲区的实现不同,共有两种不同的分配器:
- 基于内存池的字节缓冲区分配器
- 普通的字节缓冲区分配器

public interface ByteBufAllocator {
ByteBuf buffer(); //分配一个字节缓冲区,缓冲区的类型由ByteBufAllocator的实现类决定
ByteBuf buffer(int var1);//初始容量
ByteBuf buffer(int var1, int var2);//初始容量,最大容量
ByteBuf ioBuffer();//分配一个内存缓冲区,更希望是直接内存,因为直接内存的IO操作性更高
ByteBuf ioBuffer(int var1);
ByteBuf ioBuffer(int var1, int var2);
ByteBuf heapBuffer();//分配堆内存缓冲区
ByteBuf heapBuffer(int var1);
ByteBuf heapBuffer(int var1, int var2);
ByteBuf directBuffer();//分配直接内存缓冲区
ByteBuf directBuffer(int var1);
ByteBuf directBuffer(int var1, int var2);
CompositeByteBuf compositeBuffer();
CompositeByteBuf compositeBuffer(int var1);
CompositeByteBuf compositeHeapBuffer();
CompositeByteBuf compositeHeapBuffer(int var1);
CompositeByteBuf compositeDirectBuffer();
CompositeByteBuf compositeDirectBuffer(int var1);
boolean isDirectBufferPooled();//是否使用了直接内存内存池
}
UnpooledByteBufAllocator
AbstractByteBufAllocator已经实现了大部分的代码,具体关于heap和direct以及unsafe和非unsafe的实现,需要由继承AbstractByteBufAllocator的子类实现。
/**
* 关于unsafe和非unsafe的内存分配自行判断是否为unsafe对象
*
*/
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
return new UnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
protected UnpooledHeapByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
this(alloc, new byte[initialCapacity], 0, 0, maxCapacity);//heap内存是直接new byte[]的
}
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
Object buf;
if (PlatformDependent.hasUnsafe()) {//判断是否为unsafe对象
buf = new UnpooledUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer((ByteBuf)buf);
}
PooledByteBufAllocator源码分析
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = (PoolThreadCache)this.threadCache.get();//拿到线程局部缓存
PoolArena<byte[]> heapArena = cache.heapArena;//在线程局部缓存的Area进行堆内存分配
Object buf;
if (heapArena != null) {
buf = heapArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = new UnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer((ByteBuf)buf);
}
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = (PoolThreadCache)this.threadCache.get();//拿到线程局部缓存
PoolArena<ByteBuffer> directArena = cache.directArena;//在线程局部缓存的Area进行直接内存分配
Object buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else if (PlatformDependent.hasUnsafe()) {
buf = new UnpooledUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer((ByteBuf)buf);
}