MNIST手写数字数据集的读取,基于python3
MNIST 是一个入门级别的计算机视觉数据库,也是机器学习领域最有名的数据集之一。当我们开始学习编程的时候,第一件事往往就是打“Hello world”。而在机器学习中,识别 MNIST 就相当于编程中的“Hello world”。
MNIST 中包含了手写数字0~9的图片以及他们对应的标签。如下图所示:

MNIST 数据集的官网是http://yann.lecun.com/exdb/mnist/,我们可以从这里手动下载数据集。
你可以在官网上下载到下面四个压缩包:
- train-images-idx3-ubyte.gz
- train-labels-idx1-ubyte.gz
- t10k-images-idx3-ubyte.gz
- t10k-labels-idx1-ubyte.gz
解压后得到四个文件:
- 训练集图像:t10k-images.idx3-ubyte
- 训练集标签:t10k-labels.idx1-ubyte
- 测试集图像:train-images.idx3-ubyte
- 测试集标签:train-labels.idx1-ubyte
MNIST数据集文件格式说明
训练集中有60,000个样本,测试集中有5,000个样本。所有图像都被标准化为28*28像素,像素值在0~255之间,0表示背景,255表示前景。
文件格式说明(以训练集为例):
图片文件格式说明:
----------------------------------------
[字节位置] [类型] [值] [描述]
0000 32位整型 2051 幻数
0004 32位整型 60000 图片数
0008 32位整型 28 行数
0012 32位整型 28 列数
0016 无符号字节 ?? 像素
0017 无符号字节 ?? 像素
......
xxxx 无符号字节 ?? 像素
----------------------------------------
标签文件格式说明:
----------------------------------------
[字节位置] [类型] [值] [描述]
0000 32位整型 2049 幻数
0004 32位整型 60000 标签数
0008 无符号字节 ?? 标签
0009 无符号字节 ?? 标签
......
xxxx 无符号字节 ?? 标签
----------------------------------------
注:这里的整形指的都是无符号整型
上述的32位整形遵循 “MSB first”,即高位字节在左边,如十进制8,二进制储存形式为1000。
幻数是一个固定值,它占据文件的前4个字节,实际上表示的是这个文件储存的是图片还是标签,没有具体用处,我们可以忽略它。
图片数与标签数占据文件4~7个字节的位置,在训练集中,它为60,000,表示这个文件有60,000个图片或标签,在测试集中,它为5,000。
行数和列数描述的是每张图片的大小,它们也是固定值,都为28。
每张图片有28*28=784个像素,所以从图片文件第16个字节位置开始,每隔784个字节为一张新图片,其中每个像素的像素值为0~255。
从标签文件的第8个字节位置开始,每个字节都对应着一张图片的数字,标签的值为0~9。
程序实现
我们已将了解了数据集文件的格式,现在我们将实现读取数据集的程序。在这里我使用了Python3来实现它。
我在这里使用了Python内置模块struct中的unpack函数和Numpy库。
import numpy as np
from struct import unpack
然后我以读取图片文件为例:
def read_image(path):
with open(path, 'rb') as f:
magic, num, rows, cols = unpack('>4I', f.read(16))
img = np.fromfile(f, dtype=np.uint8).reshape(num, 784)
return img
内置模块struct可以处理存储在文件中的二进制数据,通过此模块的unpack函数,可以实现对二进制文件的转换。unpack的定义如下:
unpack(fmt, buffer) -> (v1, v2, ...)
返回一个元组,其中包含根据格式字符串fmt解压缩的值。fmt是格式字符串,buffer是被解压缩的字符串或二进制
关于格式字符串的详细信息可以去官网或者专门介绍此模块的博客中查看。
在我们的程序中,’>4I’表示的是以大端的转换4个无符号整型变量(4个字节,非负数)。unpack示意图如下:
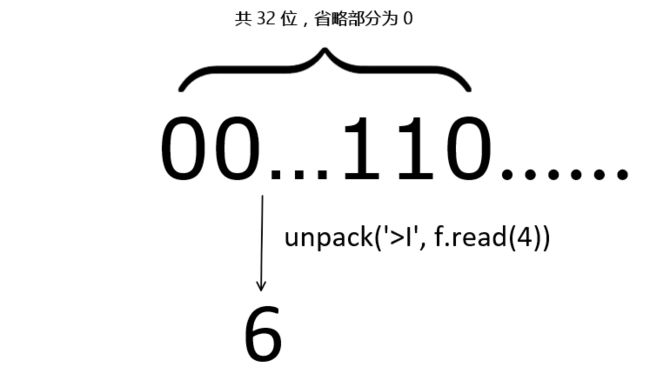
np.fromfile是通过一种使用已知数据类型读取二进制数据的函数,它返回的是一个ndarray类型的数组。我们根据文件的结构,选择了uint8这个数据类型。np.fromfile的定义如下:
numpy.fromfile(file, dtype=float, count=-1, sep='')
根据文本或二进制文件中的数据构造数组。
参数:
file : file或str
打开文件对象或文件名。
dtype : data-type
返回的数组的数据类型。对于二进制文件,它用于确定文件中项目的大小和字节顺序。
count : int
要读取的项目数。-1表示所有项目(即完整文件)。
sep : str
如果文件是文本文件,则在项目之间分隔。空("")分隔符表示该文件应被视为二进制文件。
分隔符中的空格("")匹配零个或多个空格字符。仅包含空格的分隔符必须至少匹配一个空格。
当我们通过np.fromfile读入文件后,会返回一个一维数组,我们现在需要把每张照片都拿出来,所以我使用了reshape这个函数,这个函数返回一个具相同数据但形状不同的数组,可以以一张图来简单演示:
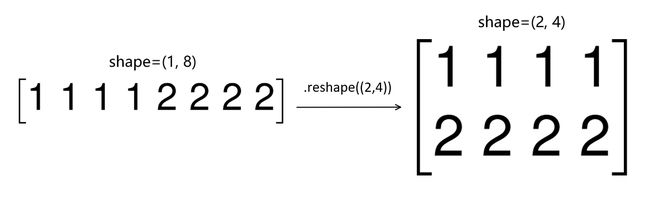
同理,我也可以读取标签文件。代码如下:
def read_label(path):
with open(path, 'rb') as f:
magic, num = unpack('>2I', f.read(8))
lab = np.fromfile(f, dtype=np.uint8)
return lab
读取标签的原理与读入图片的原理相同,就不在重复一遍了。
注:当你没有解压文件,即你的文件后缀名为.gz的时候,可以用以下方法读取:
#其他代码正常
import gzip
with gzip.open('data/train-images-idx3-ubyte.gz', 'rb') as f:
...
MNIST数据处理
我们总是希望数据的格式能符合我们的要求,所以在使用数据之前,我们需要对它进行一些处理。
将图像的像素值正规化为0.0~1.0
def normalize_image(image):
img = image.astype(np.float32) / 255.0
return img
将标签转化为one_hot编码
def one_hot_label(label):
lab = np.zeros((label.size, 10))
for i, row in enumerate(lab):
row[label[i]] = 1
return lab
举例说明one_hot编码:假如一共有4类(数字0~3),0的ont_hot为1000,1的one_hot为0100,2的one_hot为0010,3的one_hot为0001。只有一个位为1,1所在的位置就代表第几类。如下图所示:

MNIST读取函数
以下是全部代码:
import numpy as np
from struct import unpack
def __read_image(path):
with open(path, 'rb') as f:
magic, num, rows, cols = unpack('>4I', f.read(16))
img = np.fromfile(f, dtype=np.uint8).reshape(num, 784)
return img
def __read_label(path):
with open(path, 'rb') as f:
magic, num = unpack('>2I', f.read(8))
lab = np.fromfile(f, dtype=np.uint8)
return lab
def __normalize_image(image):
img = image.astype(np.float32) / 255.0
return img
def __one_hot_label(label):
lab = np.zeros((label.size, 10))
for i, row in enumerate(lab):
row[label[i]] = 1
return lab
def load_mnist(train_image_path, train_label_path, test_image_path, test_label_path, normalize=True, one_hot=True):
'''读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
Returns
----------
(训练图像, 训练标签), (测试图像, 测试标签)
'''
image = {
'train' : __read_image(train_image_path),
'test' : __read_image(test_image_path)
}
label = {
'train' : __read_label(train_label_path),
'test' : __read_label(test_label_path)
}
if normalize:
for key in ('train', 'test'):
image[key] = __normalize_image(image[key])
if one_hot:
for key in ('train', 'test'):
label[key] = __one_hot_label(label[key])
return (image['train'], label['train']), (image['test'], label['test'])
参考文献:
[1] 斋藤康毅.陆宇杰.深度学习入门:基于Python的理论与实现[M].北京:人民邮电出版社,2018.