比赛回顾1|众安保险线下Hackthon 保险续保预测
鄙人参加了一些数据挖掘的竞赛,有运气好抱大腿获奖的,也有被大佬碾压的,但是希望能把这些比赛过程尽量记录下。一方面是记录一下事件本身,另一方面,是希望把自己的方案和想法记录下,同时即使获得了好的成绩,也是有运气成分,还是希望能够找到有进步的空间,以后能做的更好。
比赛开始的时候,是在2018年8月23日抵达的上海,入住了酒店。第二天早上吃了酒店高贵的自助早餐之后就去签到了。正式比赛开始是早上10点开始,一直到第二天的中午12点截止。(有没有觉得很神奇,真的很神奇,线下的预测比赛哦,调参就给了26个小时,中间我们真的没怎么睡,熬出来的)
然后到了25号早上,队友还在玄学调结果,我就只能先默默去把方案ppt给做了,因为我也就做了些特征相关的处理。下午两点答辩。最紧张刺激的是,我们当时在线的榜一直都是第一,在最后截止前一个多小时,被超了,最后就屈居第二。怀着沉重的心情,做着方案ppt。不过最后似乎我们的方案更得评委的心,(其实是我没怎么讲技术实现,然而大家的方法都比较雷同),总分反超获得第一。emmmm ,运气不错叭~
先给大家看些图好啦~纪念下~

凌晨六点的外滩,你见过吗?哈哈哈,那时候真的是身心俱疲,太累啦……

夜晚的外滩也是有不错的风景呢(不过这个是我们结束了之后才去的,放松下身心啦)


最后不要脸的放一下我答辩的照片和我们最后的成果啦~
okok!现在直入正题,讨论下我们的方案!
首先!数据量!真的很少,真的不多,当时我们是猜测,方便我们线下在训练的时候,可以节省些时间。大概总共数据量在一万多条。
主要针对的就是不同的保单,我们可以看到有用户信息,同时这些保单是在什么样的状态下生成的,最后是否续报了(label)。
由于题目给的数据是全脱敏的,也就是说,特征的名称挺多没有的,而且由于对于保险领域的知识的匮乏,很多只能查资料和猜,甚至某些特征对最后的标签是否有影响都无法直接判断。因此我们对于最后的数据结果,主要是以以下的策略去执行的:
放弃无意义的数据,例如那些90%以上都是重复的数据,或者是唯一标识符性质的数据;
挖掘有意义的数据,对其数据进行重新的映射和标记;
从看起来有意义的数据背后挖掘相关的含义,让模型和场景结合的更紧密(其实是为了让答辩有东西可以讲)。
那么接下来就看下我们具体是怎么做特征工程的吧:

先来看下我们对于特征的分析统计信息。我们被给到的特征类型主要有C类型,V类型和Z类型的,大概的理解就是C类型的就是编号类型的,V类型的就是数值类型的,Z类型则是一些字符信息。
当然可以看到,我们根据原有的特征,进行了重组和计算等等,挖掘了他们背后的意义。总共我们的特征数量是24条。我们总共获取的特征数量是在原有数量的四分之一左右,所以可以看到其中还是有不少特征是无用,(或者是我们没有挖掘到深层信息的特征)。

现在来看看我们针对保险表单挖掘的信息,其中一些标为native的特征就是直接从原表中复制过来的。然后就让我来解释一下其中我们经过处理的特征,或是我们猜测其背后含义的数据吧。
C02是我们重新定义的一维数据,其中的内容就是为了判断这份保单是否是用户为自己购买的,这个信息可以从表单的对应的人数中看的出来,因为每一张保单对应的角色一共有三个,投保人、被保人和受益人,一般只有都是同一个人,和有两个人的情况(至少我们在比赛的过程中没有出现有三个不同的人充当单个角色)。
C09是我们认为一维比较强的特征,因为它可能代表的是保单的类型。猜测的原因也是因为在保险表单里面对应的分类较少的一维特征了。同时我们猜测到这一维特征是保单的类型,由此推测,保单的类型可能会大概率影响后续的续保行为,有可能保单的保险金额比较高,或者是比较容易报销,或者是收益比较好,等等,都是有可能的。
V00,V01,V03这三维数据是比较有意思的,当时发现原表单里面是有三列特征有加减关系的,意思就是列A+列B=列C,很直观的就从销售角度考虑到折扣的问题了,我们就将他们两个合并成了V03这个单一特征了。同时V00这个特征是保留了保单的保额,也是会影响到最后的保单延续的情况。
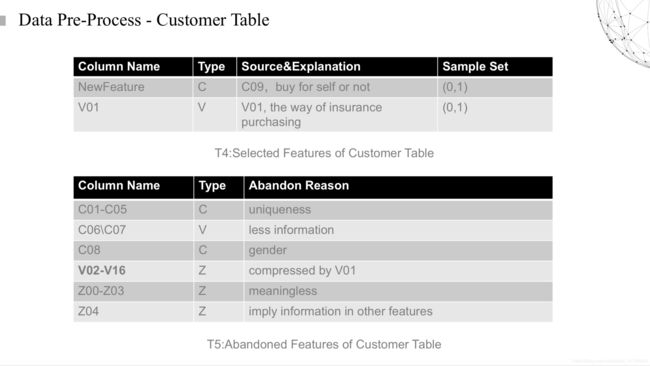
在保单关于用户信息的一栏里面,最有趣的一栏是我们当时现场逼问出题人这个含义到底是什么意思。当时有很多无用数据,缺失率大概在80%以上,我们当时都放弃了,但是他们说给我们的数据都是有用的,于是他们就告诉我们在不同平台上的数据记录行为会有所区别。这就提示了我们,可能在不同平台上产生的保单,会有不同的信息记录形式,这也就可以从另一个角度告诉我们,这些用户是在不同平台上进行保险的购买,同时我也查找了相关的文献,在官方平台上产生的购买行为,复购率比第三方平台上的复购率高很多。于是我们就把这一维特征表达成了是否在官方平台上产生购买行为的bool型特征。
T5中展示的是我们在表中丢掉的一些特征,其中可能会又人很奇怪,为什么会丢掉性别特征,好,来看下一张图表,我们可以很明确的证明我们的猜想。

这个是我们在公司官网上扒下来的信息,对于不同年龄段的用户可能会产生不同的保费,但是其中并没有性别的选项,因此我们将性别信息排除在外。同时我们也对其进行猜测,可能在产生重大疾病或重大赔付的人群中,男女比例差别并不大。
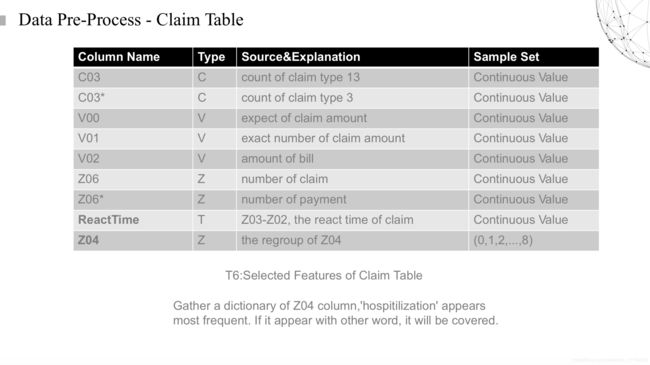
最后一张表是保险赔付的表单,其中主要是用户产生了赔付行为,其中一些赔付款项,实际赔款,以及我们经过特殊处理的反应时间。在赔付行为和赔付的反应服务上,可能也会对用户的最后续保行为产生影响。
我们特征工程差不多就是这么多。算法的用的就是数据挖掘竞赛常用的xgboost算法,美其名曰其理论非常的优美。
最后的结果是以F1-score来测评的,这个赛题的结果并没有那么好,而且大家的方案结果都很接近,我们最终是在0.67左右的结果。
那么为了让整个“表演”更加的完整,我们还讨论了一下什么特征是对于我们最后的预测是最有帮助的——保费金额和保险状态。
Meanwhile呢,我们也讨论了下这个赛题的意义,无外乎就是吹捧了一下评委多棒啊,公司多牛逼,对,就是这样了。
那么最后肯定都是要讨论一下 future work的啦~对不对!自然就是说如何再提升F1-score啦,比如引入更多的特征,等等。
复盘到这里,其实觉得这次比赛真的做的非常一般,都没有pandas分析一下数据的分布和标签的关联性(队友们我错了,我一定加强我的数据分析能力),甚至最基础的特征交叉也没尝试过,只是做了简单的特征合并。不过整个比赛过程还是很享受的,每一步大家pace都很一致,所以整个比赛还是很愉快的。
不过最后的最后,我个人有一点小感想,包括做的别的比赛。在真实数据下的真实场景的数据挖掘竞赛,一定要深度理解场景背后的数据意义,不然这个数据就算用经验处理出来最后的结果,也不会有太好的表达性。但是,如果一味的挖掘背后的真实意义,有时候反而会忽略一些小的细节点,这些是可以用传统的暴力的特征交叉的方法做到的。
所以,这个小的总结写了不少,是本人在数据挖掘竞赛上的第一次比赛啦,也希望之后和队友们能越走越远,获得更好的成绩。欢迎大家留言交流。
以上。