【Machine Learning, Coursera】机器学习Week9 推荐系统笔记
ML: Recommender Systems
1. Content-based recommendations
思考:已有用户对部分电影的评价(1-5星),且已知电影的内容构成,如何预测用户对没看过的电影的评价并作出推荐?
1.1 Problem formulation
首先给出一些notations:
n u = n u m b e r o f u s e r s n_u=number\ of\ users\quad nu=number of users 用户数量
n m = n u m b e r o f m o v i e s n_m=number\ of\ movies\quad nm=number of movies 电影数量
r ( i , j ) = 1 i f u s e r j h a s r a t e d m o v i e i r(i,j)=1\ if\ user\ j\ has\ rated\ movie\ i\quad r(i,j)=1 if user j has rated movie i 用户 j j j是否评价了电影 i i i
y ( i , j ) = r a t i n g g i v e n b y u s e r j t o m o v i e i y^{(i,j)}=rating\ given\ by\ user\ j\ to\ movie\ i\quad y(i,j)=rating given by user j to movie i 用户 j j j对电影 i i i的评分,只有当 r ( i , j ) = 1 r(i,j)=1 r(i,j)=1时有定义
x ( i ) = f e a t u r e v e c t o r f o r m o v i e i x^{(i)}=feature\ vector\ for\ movie\ i\quad x(i)=feature vector for movie i
电影 i i i的特征向量,如 x 1 x_1 x1表示其爱情成分比重, x 2 x_2 x2表示其动作成分比重。 x 0 x_0 x0为偏置项,值为1.
θ ( j ) = p a r a m e t e r v e c t o r f o r u s e r j \theta^{(j)}=parameter\ vector\ for\ user\ j\quad θ(j)=parameter vector for user j
用户 j j j的参数,如 θ 1 \theta_1 θ1表示其对爱情片的喜好程度, θ 2 \theta_2 θ2表示其对动作片的喜好程度。 θ 0 \theta_0 θ0为偏置项,值为1.
对于用户 j j j和电影 i i i,预测其评价为 ( θ ( j ) ) T x ( i ) (\theta^{(j)})^Tx^{(i)} (θ(j))Tx(i)
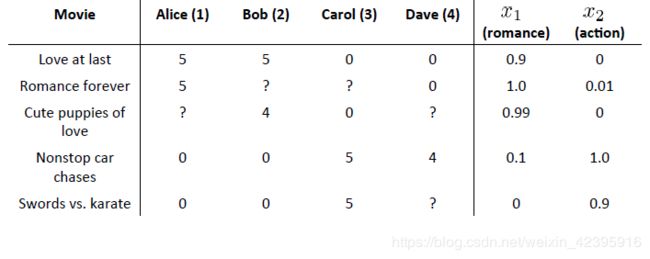
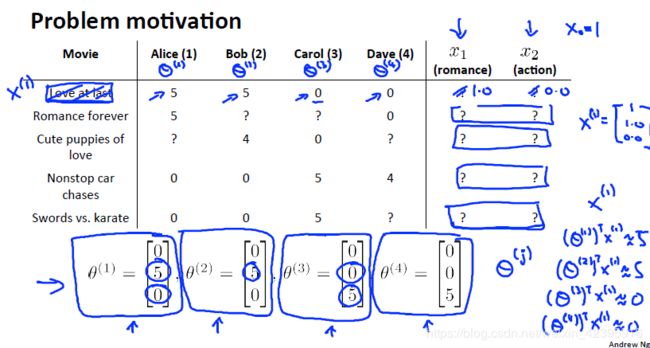
如下图中, n u = 4 n_u=4 nu=4, n m = 5 n_m=5 nm=5,右侧两栏是各个电影的特征。
可以看出电影1、2、3属于爱情类电影,4、5属于动作类。
观众3(Carol)对电影4和5评价很高,而对电影1和3评价很低,由此可以推断 ( θ ( 3 ) ) T = [ 0 , 0 , 5 ] (\theta^{(3)})^T=[0,0,5] (θ(3))T=[0,0,5]的可能性较高。
因此,观众3对电影2的打分可能为 ( θ ( 3 ) ) T x ( 2 ) = [ 0 , 0 , 5 ] × ( [ 1 , 1 , 0.01 ] ) T = 0.05 (\theta^{(3)})^Tx^{(2)}=[0,0,5]\times([1,1,0.01])^T=0.05 (θ(3))Tx(2)=[0,0,5]×([1,1,0.01])T=0.05
1.2 Optimization objective
求某个用户的参数 θ ( j ) \theta^{(j)} θ(j)其实是一个基本的线性回归问题:
m i n θ ( j ) 1 2 m ( j ) ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) 2 + λ 2 m ( j ) ∑ k = 1 n ( θ k ( j ) ) 2 min_{\theta^{(j)}}\quad \frac{1}{2m^{(j)}}\sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})^2+\frac{\lambda}{2m^{(j)}}\sum_{k=1}^{n}(\theta_k^{(j)})^2 minθ(j)2m(j)1i:r(i,j)=1∑((θ(j))Tx(i)−y(i.j))2+2m(j)λk=1∑n(θk(j))2
其中 m ( j ) m^{(j)} m(j)为用户 j j j评价过的电影数目。注意k从1开始,偏置项无需正则化。
\quad
在设计推荐系统的实践过程中,简单起见,我们会去掉 m ( j ) m^{(j)} m(j)这一项,于是上式变为:
m i n θ ( j ) 1 2 ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) 2 + λ 2 ∑ k = 1 n ( θ k ( j ) ) 2 min_{\theta^{(j)}}\quad \frac{1}{2}\sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})^2+\frac{\lambda}{2}\sum_{k=1}^{n}(\theta_k^{(j)})^2 minθ(j)21i:r(i,j)=1∑((θ(j))Tx(i)−y(i.j))2+2λk=1∑n(θk(j))2
\quad
更一般地,如果要学习所有用户的参数 θ ( 1 ) , θ ( 2 ) , . . . . , θ ( n u ) \theta^{(1)},\theta^{(2)},....,\theta^{(n_u)} θ(1),θ(2),....,θ(nu),只需把 n u n_u nu个线性回归相加:
m i n θ ( 1 ) , . . . , θ ( n u ) 1 2 ∑ j = 1 n u ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k ( j ) ) 2 min_{\theta^{(1)},...,\theta^{(n_u)}}\quad \frac{1}{2}\sum_{j=1}^{n_u}\sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^{n}(\theta_k^{(j)})^2 minθ(1),...,θ(nu)21j=1∑nui:r(i,j)=1∑((θ(j))Tx(i)−y(i.j))2+2λj=1∑nuk=1∑n(θk(j))2
\quad
1.3 Optimization algorithm
m i n θ ( 1 ) , . . . , θ ( n u ) 1 2 ∑ j = 1 n u ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k ( j ) ) 2 min_{\theta^{(1)},...,\theta^{(n_u)}}\quad \frac{1}{2}\sum_{j=1}^{n_u}\sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^{n}(\theta_k^{(j)})^2 minθ(1),...,θ(nu)21j=1∑nui:r(i,j)=1∑((θ(j))Tx(i)−y(i.j))2+2λj=1∑nuk=1∑n(θk(j))2
依然用梯度下降的方法求最小值,每步的更新值为:
θ k ( j ) : = θ k ( j ) − α ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) x k ( i ) ( f o r k = 0 ) \theta_k^{(j)}:=\theta_k^{(j)}-\alpha\sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})x_k^{(i)}\ (for\ k=0) θk(j):=θk(j)−αi:r(i,j)=1∑((θ(j))Tx(i)−y(i.j))xk(i) (for k=0)
θ k ( j ) : = θ k ( j ) − α ( ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) x k ( i ) + λ θ k ( j ) ) ( f o r k ≠ 0 ) \theta_k^{(j)}:=\theta_k^{(j)}-\alpha(\sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})x_k^{(i)}+\lambda \theta_k^{(j)})\ (for\ k≠0) θk(j):=θk(j)−α(i:r(i,j)=1∑((θ(j))Tx(i)−y(i.j))xk(i)+λθk(j)) (for k̸=0)
\quad
2. Collaborative Filtering
2.1 Introduction
思考:已有用户对部分电影的评价(1-5星),且已知用户的参数 θ ( 1 ) , θ ( 2 ) , . . . . , θ ( n u ) \theta^{(1)},\theta^{(2)},....,\theta^{(n_u)} θ(1),θ(2),....,θ(nu),是不是也能反过来求 x ( i ) x^{(i)} x(i)呢?
根据第一部分的分析,很容易得到由 θ ( 1 ) , θ ( 2 ) , . . . . , θ ( n u ) \theta^{(1)},\theta^{(2)},....,\theta^{(n_u)} θ(1),θ(2),....,θ(nu),求 x ( 1 ) , x ( 2 ) , . . . , x ( n m ) x^{(1)},x^{(2)},...,x^{(n_m)} x(1),x(2),...,x(nm)的目标函数:
m i n x ( 1 ) , x ( 2 ) , . . . , x ( n m ) 1 2 ∑ i = 1 n m ∑ j : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) 2 + λ 2 ∑ i = 1 n m ∑ k = 1 n ( x k ( i ) ) 2 min_{x^{(1)},x^{(2)},...,x^{(n_m)}}\quad \frac{1}{2}\sum_{i=1}^{n_m}\sum_{j :r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})^2+\frac{\lambda}{2}\sum_{i=1}^{n_m}\sum_{k=1}^{n}(x_k^{(i)})^2 minx(1),x(2),...,x(nm)21i=1∑nmj:r(i,j)=1∑((θ(j))Tx(i)−y(i.j))2+2λi=1∑nmk=1∑n(xk(i))2
也就是说,我们知道 θ \theta θ就能学习 x x x,知道 x x x也能学习 θ \theta θ.
因此,我们可以先随机初始化一组 θ \theta θ,学习出 x x x,并根据已有的一些电影的原始特征,优化出更好的 θ \theta θ。重复 θ → x → θ → x → θ → x \theta→x→\theta→x→\theta→x θ→x→θ→x→θ→x的过程,最终算法将会收敛到合理的 θ \theta θ和 x x x。这一过程,我们称之为协同过滤(collaborative filtering)。
\quad
2.2 Collaborative filtering algorithm
同时最小化 θ ( 1 ) , θ ( 2 ) , . . . . , θ ( n u ) \theta^{(1)},\theta^{(2)},....,\theta^{(n_u)} θ(1),θ(2),....,θ(nu)和 x ( 1 ) , x ( 2 ) , . . . , x ( n m ) x^{(1)},x^{(2)},...,x^{(n_m)} x(1),x(2),...,x(nm):
J = 1 2 ∑ ( i , j ) : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i . j ) ) 2 + λ 2 ∑ i = 1 n m ∑ k = 1 n ( x k ( i ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k ( j ) ) 2 J = \frac{1}{2}\sum_{(i,j):r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i.j)})^2+\frac{\lambda}{2}\sum_{i=1}^{n_m}\sum_{k=1}^{n}(x_k^{(i)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^{n}(\theta_k^{(j)})^2 J=21(i,j):r(i,j)=1∑((θ(j))Tx(i)−y(i.j))2+2λi=1∑nmk=1∑n(xk(i))2+2λj=1∑nuk=1∑n(θk(j))2
m i n θ ( 1 ) , . . . . , θ ( n u ) , x ( 1 ) , . . . , x ( n m ) J ( θ ( 1 ) , . . . . , θ ( n u ) , x ( 1 ) , . . . , x ( n m ) ) min_{\theta^{(1)},....,\theta^{(n_u)},x^{(1)},...,x^{(n_m)}}\quad J(\theta^{(1)},....,\theta^{(n_u)},x^{(1)},...,x^{(n_m)}) minθ(1),....,θ(nu),x(1),...,x(nm)J(θ(1),....,θ(nu),x(1),...,x(nm))
