Elasticsearch对数字检索——ngram
数字可能信息不全,需要对数字进行切分,所以选用 ngram 分词器进行分词
测试
POST _analyze
{
"tokenizer": "ngram",
"text":"123456"
}
{
"tokens" : [
{
"token" : "1",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "12",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "2",
"start_offset" : 1,
"end_offset" : 2,
"type" : "word",
"position" : 2
},
{
"token" : "23",
"start_offset" : 1,
"end_offset" : 3,
"type" : "word",
"position" : 3
},
{
"token" : "3",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 4
},
{
"token" : "34",
"start_offset" : 2,
"end_offset" : 4,
"type" : "word",
"position" : 5
},
{
"token" : "4",
"start_offset" : 3,
"end_offset" : 4,
"type" : "word",
"position" : 6
},
{
"token" : "45",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 7
},
{
"token" : "5",
"start_offset" : 4,
"end_offset" : 5,
"type" : "word",
"position" : 8
},
{
"token" : "56",
"start_offset" : 4,
"end_offset" : 6,
"type" : "word",
"position" : 9
},
{
"token" : "6",
"start_offset" : 5,
"end_offset" : 6,
"type" : "word",
"position" : 10
}
]
}
创建mapping
PUT test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 4,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
, "mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
POST test/_analyze
{
"analyzer": "my_analyzer",
"text":"渝A253DC"
}
{
"tokens" : [
{
"token" : "渝A2",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "渝A25",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 1
},
{
"token" : "A25",
"start_offset" : 1,
"end_offset" : 4,
"type" : "word",
"position" : 2
},
{
"token" : "A253",
"start_offset" : 1,
"end_offset" : 5,
"type" : "word",
"position" : 3
},
{
"token" : "253",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "253D",
"start_offset" : 2,
"end_offset" : 6,
"type" : "word",
"position" : 5
},
{
"token" : "53D",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 6
},
{
"token" : "53DC",
"start_offset" : 3,
"end_offset" : 7,
"type" : "word",
"position" : 7
},
{
"token" : "3DC",
"start_offset" : 4,
"end_offset" : 7,
"type" : "word",
"position" : 8
}
]
}
POST test/_analyze
{
"analyzer": "my_analyzer",
"text":"123456"
}
{
"tokens" : [
{
"token" : "123",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "1234",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 1
},
{
"token" : "234",
"start_offset" : 1,
"end_offset" : 4,
"type" : "word",
"position" : 2
},
{
"token" : "2345",
"start_offset" : 1,
"end_offset" : 5,
"type" : "word",
"position" : 3
},
{
"token" : "345",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "3456",
"start_offset" : 2,
"end_offset" : 6,
"type" : "word",
"position" : 5
},
{
"token" : "456",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 6
}
]
}
错误提示:
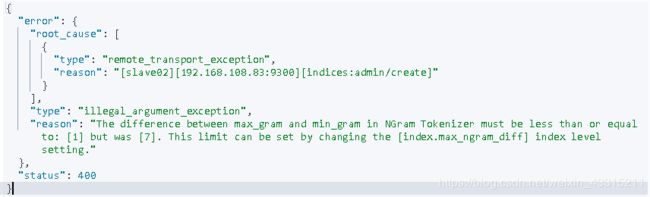
The difference between max_gram and min_gram in NGram Tokenizer must be less than or equal to: [1] but was [7]. This limit can be set by changing the [index.max_ngram_diff] index level setting。
从ES 7.0 以上,需要从新对 index.max_ngram_diff 进行设置
重构mapping
PUT test
{
"settings": {
"index.max_ngram_diff":8,
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 8,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
, "mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
POST test/_analyze
{
"analyzer": "my_analyzer",
"text":"123456"
}
{
"tokens" : [
{
"token" : "1",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "12",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "123",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "1234",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 3
},
{
"token" : "12345",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "123456",
"start_offset" : 0,
"end_offset" : 6,
"type" : "word",
"position" : 5
},
{
"token" : "2",
"start_offset" : 1,
"end_offset" : 2,
"type" : "word",
"position" : 6
},
{
"token" : "23",
"start_offset" : 1,
"end_offset" : 3,
"type" : "word",
"position" : 7
},
{
"token" : "234",
"start_offset" : 1,
"end_offset" : 4,
"type" : "word",
"position" : 8
},
{
"token" : "2345",
"start_offset" : 1,
"end_offset" : 5,
"type" : "word",
"position" : 9
},
{
"token" : "23456",
"start_offset" : 1,
"end_offset" : 6,
"type" : "word",
"position" : 10
},
{
"token" : "3",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 11
},
{
"token" : "34",
"start_offset" : 2,
"end_offset" : 4,
"type" : "word",
"position" : 12
},
{
"token" : "345",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 13
},
{
"token" : "3456",
"start_offset" : 2,
"end_offset" : 6,
"type" : "word",
"position" : 14
},
{
"token" : "4",
"start_offset" : 3,
"end_offset" : 4,
"type" : "word",
"position" : 15
},
{
"token" : "45",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 16
},
{
"token" : "456",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 17
},
{
"token" : "5",
"start_offset" : 4,
"end_offset" : 5,
"type" : "word",
"position" : 18
},
{
"token" : "56",
"start_offset" : 4,
"end_offset" : 6,
"type" : "word",
"position" : 19
},
{
"token" : "6",
"start_offset" : 5,
"end_offset" : 6,
"type" : "word",
"position" : 20
}
]
}
延伸:edgeNGram
ngram 的简化版,单个分词,以首字母为起始位置,进行分词
效果如下
PUT test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "edgeNGram",
"min_gram": 1,
"max_gram": 8,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
, "mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
POST test/_analyze
{
"analyzer": "my_analyzer",
"text":"123456"
}
{
"tokens" : [
{
"token" : "1",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "12",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "123",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "1234",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 3
},
{
"token" : "12345",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "123456",
"start_offset" : 0,
"end_offset" : 6,
"type" : "word",
"position" : 5
}
]
}