Python数据挖掘之逻辑回归算法
逻辑回归算法
逻辑回归算法:虽然名字中带有回归两个字,但它却不是回归算法,它是一个经典的二分类算法。

目录
- 逻辑回归算法
- Logistic函数
- Logistic回归建模步骤
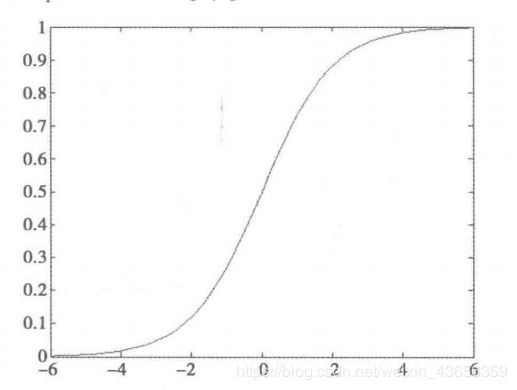
Logistic函数
Logistic回归模型中的因变量只有1和0(发生于不发生)两种。假设在p个独立自变量x1,x2…xp作用下,y取1的概率是p = P(y = 1|X)取0的概率是1-p,取1和取0的概率之比为
p 1 − p \frac{p}{1-p} 1−pp
称为事件的优势比(odds),对odds取自然对数得Logistic变换
L o g i t ( p ) = l n ( p 1 − p ) 称 为 ① Logit(p) = ln(\frac{p}{1-p}) 称为① Logit(p)=ln(1−pp)称为①
令①=z,则
p = 1 1 + e z p = \frac{1}{1+e^{z}} p=1+ez1
称为Logistic函数
如图:
Logistic回归建模步骤
a、根据分析目的设置指标变量(因变量和自变量),然后收集数据,根据收集到的数据,对特征再次进行筛选
b、y取1的概率是p= P(y= 1|X), 取0概率是1-p。用
l n ( p 1 − p ) ln(\frac{p}{1-p}) ln(1−pp)
和自变量列出线性回归方程,估计出模型中的回归系数
c、进行模型检验。模型有效性的检验指标有很多,最基本的有正确率,其次有混淆矩阵、ROC曲线、KS值等。
d、模型应用:输入自变量的取值,就可以得到预测变量的值,或者根据预测变量的值去控制自变量的取值。
实例:
| 年龄 | 教育 | 工龄 | 地址 | 收入 | 负债率 | 信用卡负债 | 其他负债 | 违约 |
|---|---|---|---|---|---|---|---|---|
| 41 | 3 | 17 | 12 | 176.00 | 9.30 | 11.36 | 5.01 | 1 |
| 27 | 1 | 10 | 6 | 31.00 | 17.30 | 1.36 | 4.00 | 0 |
需要数据集请私聊我
利用Scikit-Learn对这个数据进行逻辑回归分析。首先进行特征筛选,特征筛选的方法有很多,主要包含在Scikit_Learn 的feature_ selection 库中,比较简单的有通过F检验(f_ regression)来给出各个特征的F值和p值,从而可以筛选变量(选择F值大的或者p值小的特征)。其次有递归特征消除( Recursive Feature Elimination, RFE)和稳定性选择(StabilitySelection)等比较新的方法。这里使用了稳定性选择方法中的随机逻辑回归进行特征筛选,然后利用筛选后的特征建立逻辑回归模型,输出平均正确率。
逻辑回归代码
# -*- coding: utf-8 -*-
# 逻辑回归 自动建模
import pandas as pd
# 参数初始化
filename = '../data/bankloan.xls'
data = pd.read_excel(filename)
x = data.iloc[:, :8].as_matrix()
y = data.iloc[:, 8].as_matrix()
from sklearn.linear_model import LogisticRegression as LR
from stability_selection.randomized_lasso import RandomizedLogisticRegression as RLR
rlr = RLR() # 建立随机逻辑回归模型,筛选变量
rlr.fit(x, y) # 训练模型
rlr.get_support() # 获取特征筛选结果,也可以通过.scores_方法获取各个特征的分数
print(u'通过随机逻辑回归模型筛选特征结束。')
print(u'有效特征为:%s' % ','.join(data.columns[rlr.get_support()]))
x = data[data.columns[rlr.get_support()]].as_matrix() # 筛选好特征
lr = LR() # 建立逻辑货柜模型
lr.fit(x, y) # 用筛选后的特征数据来训练模型
print(u'逻辑回归模型训练结束。')
print(u'模型的平均正确率为:%s' % lr.score(x, y)) # 给出模型的平均正确率,本例为81.4%
结果:
通过随机逻辑回归模型筛选特征结束。
有效特征为:工龄,地址,负债率,信用卡负债
逻辑回归模型训练结束。
模型的平均正确率为:0.814285714286