【小白】基于Resnet+Unet的图像分割模型(by Pytorch)
文章目录
- (一)Unet
- 1.概述
- 2.代码实现
- (二)Resnet
- 1.概述
- 2.代码实现
- (三)Resnet+Unet代码详解
- 1.为什么可以这么做?
- 2.分部代码详解
- 3.整体代码
(一)Unet
1.概述
1.Unet是目前应用最广泛的图像(语义)分割模型。它采用了encode(编码)+decode(解码)的结构,先对图像进行多次conv(+Bn+Relu)+pooling下采样,再进行upsample上采样,crop之前的低层feature map,与上采样后的feature map进行融合,重复上采样+融合过程直到得到与输入图像尺寸相同的分割图。
因结构形似字母U,命名为U-net。

如果仍对Unet网络结构有疑惑,可以看这个大佬的文章,写的很棒!:
https://zhuanlan.zhihu.com/p/31428783
2.代码实现
代码可参照:https://github.com/usuyama/pytorch-unet/blob/master/pytorch_unet.py
以下是我对其的注释,以及部分修改(加了Bn层):
import torch
import torch.nn as nn
def double_conv(in_channels, out_channels): #双层卷积模型,神经网络最基本的框架
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels), #加入Bn层提高网络泛化能力(防止过拟合),加收敛速度
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1), #3指kernel_size,即卷积核3*3
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class UNet(nn.Module):
def __init__(self, n_class):
super().__init__()
self.dconv_down1 = double_conv(3, 64)
self.dconv_down2 = double_conv(64, 128)
self.dconv_down3 = double_conv(128, 256)
self.dconv_down4 = double_conv(256, 512)
self.maxpool = nn.MaxPool2d(2)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.dconv_up3 = double_conv(256 + 512, 256) #torch.cat后输入深度变深
self.dconv_up2 = double_conv(128 + 256, 128)
self.dconv_up1 = double_conv(128 + 64, 64)
self.conv_last = nn.Conv2d(64, n_class, 1)
def forward(self, x):
#encode
conv1 = self.dconv_down1(x)
x = self.maxpool(conv1)
conv2 = self.dconv_down2(x)
x = self.maxpool(conv2)
conv3 = self.dconv_down3(x)
x = self.maxpool(conv3)
x = self.dconv_down4(x)
#decode
x = self.upsample(x)
#因为使用了3*3卷积核和 padding=1 的组合,所以卷积过程图像尺寸不发生改变,所以省去了crop操作!
x = torch.cat([x, conv3], dim=1)
x = self.dconv_up3(x)
x = self.upsample(x)
x = torch.cat([x, conv2], dim=1)
x = self.dconv_up2(x)
x = self.upsample(x)
x = torch.cat([x, conv1], dim=1)
x = self.dconv_up1(x)
out = self.conv_last(x)
return out
(二)Resnet
1.概述
1.1 深度退化问题:
从经验上来看,网络越深可以提取更复杂的特征,所以当模型越深理论上可以得到更好的预测结果,但实验发现深度网络出现了模型退化问题,如图:

这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的
1.2 残差学习:
如果你有一个浅层的网络,想要在此基础上继续训练更深的网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为 X 时其学习到的特征记为 H(X) ,现在我们希望其可以学习到残差 F(X),这样其实原始的学习特征是 F(X)=H(X)-X 。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图4所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)
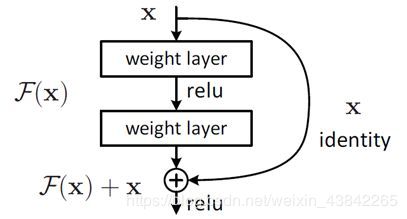
即通俗来讲:
传统学习:我们的神经网络训练对X训练,得出H(X)作为输出
残差学习:对X训练,得到F(X),将H(X)=F(X)+X作为输出
框架如下:
黑色圆弧箭头表示一个残差,虚线箭头表示用步长为2的卷积核进行下采样
相同颜色的残差表示一个‘’块‘’(block)
2.代码实现
代码可参照:https://github.com/weiaicunzai/pytorch-cifar100/blob/master/models/resnet.py
我个人喜欢↑的代码风格,但他写的好像不是个标准的resnet34,他的conv1没采用上图中7×7的卷积核和pool下采样(当然网络没有标准对错,你也可以自己魔改,7×7可以用三个3×3替代,只用一个3×3也许对你的网络效果更好,这没有定论。)
以下是我将该代码修改为标准resnet34:
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
"""Basic Block for resnet 18 and resnet 34
"""
#BasicBlock and BottleNeck block
#have different output size
#we use class attribute expansion
#to distinct
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
#residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
#shortcut
self.shortcut = nn.Sequential()
#the shortcut output dimension is not the same with residual function
#use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
"""Residual block for resnet over 50 layers
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes=100):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size = 7, stride = 2, padding = 3,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
#we use a different inputsize than the original paper
#so conv2_x's stride is 1
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
"""make resnet layers(by layer i didnt mean this 'layer' was the
same as a neuron netowork layer, ex. conv layer), one layer may
contain more than one residual block
Args:
block: block type, basic block or bottle neck block
out_channels: output depth channel number of this layer
num_blocks: how many blocks per layer
stride: the stride of the first block of this layer
Return:
return a resnet layer
"""
# we have num_block blocks per layer, the first block
# could be 1 or 2, other blocks would always be 1
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1(x)
temp=self.maxpool(output)
output = self.conv2_x(temp)
output = self.conv3_x(output)
output = self.conv4_x(output)
output = self.conv5_x(output)
output = self.avg_pool(output)
output = output.view(output.size(0), -1)
output = self.fc(output)
return output
def resnet18():
""" return a ResNet 18 object
"""
return ResNet(BasicBlock, [2, 2, 2, 2])
def resnet34():
""" return a ResNet 34 object
"""
return ResNet(BasicBlock, [3, 4, 6, 3])
def resnet50():
""" return a ResNet 50 object
"""
return ResNet(BottleNeck, [3, 4, 6, 3])
def resnet101():
""" return a ResNet 101 object
"""
return ResNet(BottleNeck, [3, 4, 23, 3])
def resnet152():
""" return a ResNet 152 object
"""
return ResNet(BottleNeck, [3, 8, 36, 3])
(三)Resnet+Unet代码详解
1.为什么可以这么做?
Unet的encode过程实际上是特征提取的过程,如果我们把他的encode过程单独拎出来,会发现其与vgg16高度相似:
vgg16:

unet-encode:

所以我们可以通过改写Unet的encode,将类vgg结构改写为效果更好的resnet,来更好的提取特征
2.分部代码详解
整体代码放最后,这部分给小白(自己)看的:
resnet最基本的结构,self.residual_function相当于上文提到的F(X),即残差
当卷积核步长不为1或深度改变时,需要同时改变X的尺寸和深度,确保F(X)+X不报错
class BasicBlock(nn.Module):
"""Basic Block for resnet 18 and resnet 34
"""
# BasicBlock and BottleNeck block
# have different output size
# we use class attribute expansion
# to distinct
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
# residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
# shortcut
self.shortcut = nn.Sequential()
# the shortcut output dimension is not the same with residual function
# use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
当resnet层数大于34时,改用右边这个模块:

因个人选用resnet34,所以这部分略过
class BottleNeck(nn.Module):
接口函数,我调用resnet34并加载了预训练参数
[3,4,6,3]表示每一层有多少残差块(即Class BasicBlock)
def resnet18():
""" return a ResNet 18 object
"""
return ResNet(BasicBlock, [2, 2, 2, 2])
def resnet34(in_channel,out_channel,pretrain=True):
""" return a ResNet 34 object
"""
model=ResNet(in_channel,out_channel,BasicBlock, [3, 4, 6, 3])
if pretrain:
model.load_pretrained_weights()
return model
def resnet50():
""" return a ResNet 50 object
"""
return ResNet(BottleNeck, [3, 4, 6, 3])
def resnet101():
""" return a ResNet 101 object
"""
return ResNet(BottleNeck, [3, 4, 23, 3])
def resnet152():
""" return a ResNet 152 object
"""
return ResNet(BottleNeck, [3, 8, 36, 3])
Class Resnet下的一个函数,用于导入预训练参数
def load_pretrained_weights(self):
#导入自己模型的参数
model_dict=self.state_dict()
#导入resnet34的参数,会自动下载哒
resnet34_weights = models.resnet34(True).state_dict()
count_res = 0
count_my = 0
reskeys = list(resnet34_weights.keys())
mykeys = list(model_dict.keys())
# print(self) 自己网络的结构
# print(models.resnet34()) resnet34 的结构
# print(reskeys) 看不懂print一下就清楚了
# print(mykeys)
corresp_map = []
while (True): # 后缀相同的放入list
reskey = reskeys[count_res]
mykey = mykeys[count_my]
if "fc" in reskey:
break
while reskey.split(".")[-1] not in mykey:
count_my += 1
mykey = mykeys[count_my]
corresp_map.append([reskey, mykey])
count_res += 1
count_my += 1
for k_res, k_my in corresp_map:
model_dict[k_my]=resnet34_weights[k_res]
try:
self.load_state_dict(model_dict)
print("Loaded resnet34 weights in mynet !")
except:
print("Error resnet34 weights in mynet !")
raise
3.整体代码
import torch
import torch.nn as nn
from torchvision import models
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.ReLU(inplace=True)
)
class BasicBlock(nn.Module):
"""Basic Block for resnet 18 and resnet 34
"""
# BasicBlock and BottleNeck block
# have different output size
# we use class attribute expansion
# to distinct
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
# residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
# shortcut
self.shortcut = nn.Sequential()
# the shortcut output dimension is not the same with residual function
# use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
"""Residual block for resnet over 50 layers
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class ResNet(nn.Module):
def __init__(self,in_channel,out_channel, block, num_block):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, 64, kernel_size = 7, stride = 2, padding = 3,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# we use a different inputsize than the original paper
# so conv2_x's stride is 1
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
# self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
# self.fc = nn.Linear(512 * block.expansion, num_classes)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.dconv_up3 = double_conv(256 + 512, 256)
self.dconv_up2 = double_conv(128 + 256, 128)
self.dconv_up1 = double_conv(128 + 64, 64)
self.dconv_last=nn.Sequential(
nn.Conv2d(128, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
nn.Conv2d(64,out_channel,1)
)
def _make_layer(self, block, out_channels, num_blocks, stride):
"""make resnet layers(by layer i didnt mean this 'layer' was the
same as a neuron netowork layer, ex. conv layer), one layer may
contain more than one residual block
Args:
block: block type, basic block or bottle neck block
out_channels: output depth channel number of this layer
num_blocks: how many blocks per layer
stride: the stride of the first block of this layer
Return:
return a resnet layer
"""
# we have num_block blocks per layer, the first block
# could be 1 or 2, other blocks would always be 1
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
conv1 = self.conv1(x)
temp=self.maxpool(conv1)
conv2 = self.conv2_x(temp)
conv3 = self.conv3_x(conv2)
conv4 = self.conv4_x(conv3)
bottle = self.conv5_x(conv4)
# output = self.avg_pool(output)
# output = output.view(output.size(0), -1)
# output = self.fc(output)
x = self.upsample(bottle)
# print(x.shape)
# print(conv4.shape)
x = torch.cat([x, conv4], dim=1)
x = self.dconv_up3(x)
x = self.upsample(x)
# print(x.shape)
# print(conv3.shape)
x = torch.cat([x, conv3], dim=1)
x = self.dconv_up2(x)
x = self.upsample(x)
# print(x.shape)
# print(conv2.shape)
x = torch.cat([x, conv2], dim=1)
x = self.dconv_up1(x)
x=self.upsample(x)
# print(x.shape)
# print(conv1.shape)
x=torch.cat([x,conv1],dim=1)
out=self.dconv_last(x)
return out
def load_pretrained_weights(self):
model_dict=self.state_dict()
resnet34_weights = models.resnet34(True).state_dict()
count_res = 0
count_my = 0
reskeys = list(resnet34_weights.keys())
mykeys = list(model_dict.keys())
# print(self)
# print(models.resnet34())
# print(reskeys)
# print(mykeys)
corresp_map = []
while (True): # 后缀相同的放入list
reskey = reskeys[count_res]
mykey = mykeys[count_my]
if "fc" in reskey:
break
while reskey.split(".")[-1] not in mykey:
count_my += 1
mykey = mykeys[count_my]
corresp_map.append([reskey, mykey])
count_res += 1
count_my += 1
for k_res, k_my in corresp_map:
model_dict[k_my]=resnet34_weights[k_res]
try:
self.load_state_dict(model_dict)
print("Loaded resnet34 weights in mynet !")
except:
print("Error resnet34 weights in mynet !")
raise
def resnet18():
""" return a ResNet 18 object
"""
return ResNet(BasicBlock, [2, 2, 2, 2])
def resnet34(in_channel,out_channel,pretrain=True):
""" return a ResNet 34 object
"""
model=ResNet(in_channel,out_channel,BasicBlock, [3, 4, 6, 3])
if pretrain:
model.load_pretrained_weights()
return model
def resnet50():
""" return a ResNet 50 object
"""
return ResNet(BottleNeck, [3, 4, 6, 3])
def resnet101():
""" return a ResNet 101 object
"""
return ResNet(BottleNeck, [3, 4, 23, 3])
def resnet152():
""" return a ResNet 152 object
"""
return ResNet(BottleNeck, [3, 8, 36, 3])
if __name__ == '__main__':
net = resnet34(3, 4, True)
print(net)
x = torch.rand((1, 3, 512, 512))
print(net.forward(x).shape)
输出这个说明网络没问题了,因为该网络我用于一个四分类问题,第二维输出为4
可通过修改 resnet34(out_channel=xx)来修改

附手绘框架:
