《动手学深度学习》之微调(热狗识别)
参考微调(fine tuning)

下面以热狗识别为例
我们将基于一个小数据集对在ImageNet数据集上训练好的ResNet模型进行微调。该小数据集含有数千张包含热狗和不包含热狗的图像。我们将使用微调得到的模型来识别一张图像中是否包含热狗。
一.导入包或模块
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision import models
import os
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
二.获取数据集
下载->热狗数据集
含有1400张包含热狗的正类图像,和同样多包含其他食品的负类图像。
各类的1000张图像被用于训练,其余则用于测试
将下载好的zip文件解压到代码所在文件夹下
解压得到两个文件夹hotdog/train和hotdog/test。
这两个文件夹下面均有hotdog和not-hotdog两个类别文件夹,每个类别文件夹里面是图像文件。
data_dir = 'hotdog'
os.listdir(os.path.join(data_dir, "hotdog")) # ['train', 'test']
创建两个ImageFolder实例来分别读取训练数据集和测试数据集中的所有图像文件
train_imgs = ImageFolder(os.path.join(data_dir, 'hotdog/train'))
test_imgs = ImageFolder(os.path.join(data_dir, 'hotdog/test'))
下面画出前8张正类图像和最后8张负类图像。
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i-1][0] for i in range(8)] #not_hotdogs文件夹里从后面读回来
print(train_imgs[1]) #'tuple' object
print(train_imgs[1][0]) #'Image' object
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)

在训练时,我们先从图像中裁剪出随机大小和随机高宽比的一块随机区域,
然后将该区域缩放为高和宽均为224像素的输入。
测试时,我们将图像的高和宽均缩放为256像素,
然后从中裁剪出高和宽均为224像素的中心区域作为输入。
此外,我们对RGB(红、绿、蓝)三个颜色通道的数值做标准化:
每个数值减去该通道所有数值的平均值,再除以该通道所有数值的标准差作为输出。
# 指定RGB三个通道的均值和方差来将图像通道归一化
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #默认的值
train_augs = transforms.Compose([
transforms.RandomResizedCrop(size=224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
test_augs = transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
normalize
])
三.定义和初始化模型
使用在ImageNet数据集上预训练的ResNet-18作为源模型
下载并加载预训练的模型参数
Downloading: “https://download.pytorch.org/models/resnet18-5c106cde.pth”,直接打开这个链接下载到本代码所在文件夹下
pretrained_net = models.resnet18(pretrained=False)
print(pretrained_net.fc) #最后的输出个数等于目标数据集的类别数1000
此时pretrained_net最后的输出个数等于目标数据集的类别数1000。所以我们应该将最后的fc成修改我们需要的输出类别数:
pretrained_net.fc = nn.Linear(512, 2)
print(pretrained_net.fc)
pretrained_net的fc层就被随机初始化了,但是其他层依然保存着预训练得到的参数。
由于是在很大的ImageNet数据集上预训练的,所以参数已经足够好,
因此一般只需使用较小的学习率来微调这些参数,
而fc中的随机初始化参数一般需要更大的学习率从头训练。
PyTorch可以方便的对模型的不同部分设置不同的学习参数,
我们在下面代码中将fc的学习率设为已经预训练过的部分的10倍。
# map函数配合匿名函数使用
# x = list(map(lambda a:a*10,range(0,10))) # 序列中的每个元素乘以10
output_params = list(map(id, pretrained_net.fc.parameters())) #id()函数用于获取对象的内存地址
feature_params = filter(lambda p: id(p) not in output_params, pretrained_net.parameters()) #从可迭代元素中过滤不想要的数据
lr = 0.01
optimizer = optim.SGD([{'params': feature_params},
{'params': pretrained_net.fc.parameters(), 'lr': lr * 10}],
lr=lr, weight_decay=0.001)
四.微调模型
def train_fine_tuning(net, optimizer, batch_size=20, num_epochs=5):
train_iter = DataLoader(ImageFolder(os.path.join(data_dir, 'hotdog/train'), transform=train_augs),
batch_size, shuffle=True)
test_iter = DataLoader(ImageFolder(os.path.join(data_dir, 'hotdog/test'), transform=test_augs),
batch_size)
loss = torch.nn.CrossEntropyLoss()
d2l.train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
train_fine_tuning(pretrained_net, optimizer)
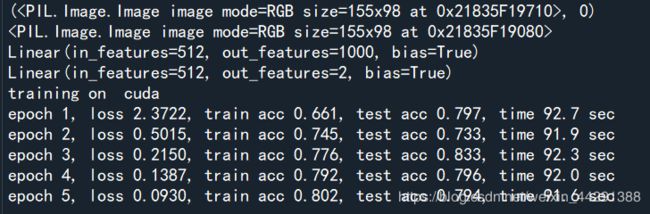
五.比较
定义一个相同的模型,但将它的所有模型参数都初始化为随机值。由于整个模型都需要从头训练,我们可以使用较大的学习率
scratch_net = models.resnet18(pretrained=False, num_classes=2)
lr = 0.1
optimizer = optim.SGD(scratch_net.parameters(), lr=lr, weight_decay=0.001)
train_fine_tuning(scratch_net, optimizer)
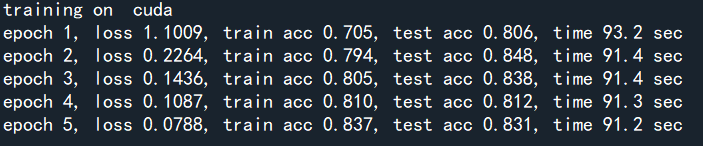
这里看到下面的效果更好一点
不过按照原来作者给出的结果是上面的会好一点,可能是batch_size的问题,作者的batch_size= 128,我的为20,调大一点会好很多,但是还是得看内存
d2lzh_pytorch
完整代码如下
# -*- coding: utf-8 -*-
"""
Created on Sun Feb 9 10:47:16 2020
@author: 吴
"""
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision import models
import os
import sys
sys.path.append("d2lzh_pytorch.py")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
data_dir = 'hotdog'
os.listdir(os.path.join(data_dir, "hotdog")) # ['train', 'test']
train_imgs = ImageFolder(os.path.join(data_dir, 'hotdog/train'))
test_imgs = ImageFolder(os.path.join(data_dir, 'hotdog/test'))
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i-1][0] for i in range(8)] #not_hotdogs文件夹里从后面读回来
print(train_imgs[1]) #'tuple' object
print(train_imgs[1][0]) #'Image' object
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)
# 指定RGB三个通道的均值和方差来将图像通道归一化
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #默认的值
train_augs = transforms.Compose([
transforms.RandomResizedCrop(size=224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
test_augs = transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
normalize
])
# 定义和初始化模型---------------------------------------
# 使用在ImageNet数据集上预训练的ResNet-18作为源模型。
# 这里指定pretrained=True来自动下载并加载预训练的模型参数。
# 在第一次使用时需要联网下载模型参数。
# Downloading: "https://download.pytorch.org/models/resnet18-5c106cde.pth",直接打开这个链接下载到本代码所在文件夹下
pretrained_net = models.resnet18(pretrained=False)
print(pretrained_net.fc) #最后的输出个数等于目标数据集的类别数1000
pretrained_net.fc = nn.Linear(512, 2)
print(pretrained_net.fc)
# map函数配合匿名函数使用
# x = list(map(lambda a:a*10,range(0,10))) # 序列中的每个元素乘以10
output_params = list(map(id, pretrained_net.fc.parameters())) #id()函数用于获取对象的内存地址
feature_params = filter(lambda p: id(p) not in output_params, pretrained_net.parameters()) #从可迭代元素中过滤不想要的数据
lr = 0.01
optimizer = optim.SGD([{'params': feature_params},
{'params': pretrained_net.fc.parameters(), 'lr': lr * 10}],
lr=lr, weight_decay=0.001)
#batch_size 可以继续调大,得看自己电脑CUDA 内存
def train_fine_tuning(net, optimizer, batch_size=20, num_epochs=5):
train_iter = DataLoader(ImageFolder(os.path.join(data_dir, 'hotdog/train'), transform=train_augs),
batch_size, shuffle=True)
test_iter = DataLoader(ImageFolder(os.path.join(data_dir, 'hotdog/test'), transform=test_augs),
batch_size)
loss = torch.nn.CrossEntropyLoss()
d2l.train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
# train_fine_tuning(pretrained_net, optimizer)
scratch_net = models.resnet18(pretrained=False, num_classes=2)
lr = 0.1
optimizer = optim.SGD(scratch_net.parameters(), lr=lr, weight_decay=0.001)
train_fine_tuning(scratch_net, optimizer)