hadoop集群的搭建,详细过程
- 概念
HDFS分布式文件系统会将用户提交的文件存储在一个服务器集群中

HDFS中有两种重要的服务器软件角色:
- datanode --》负责存储用户文件的块
- namenode--》负责记录用户存储的文件的虚拟路径,及文件每一个块的具体位置(哪一块在哪一台datanode服务器上)
- 安装一个HDFS集群
- 准备工作:
规划:要有一台机器安装namenode
要有N台datanode服务器
准备4台虚拟机:
在vmware中创建一个虚拟机
安装linux系统
安装jdk
主机名、ip地址、hosts映射
安装ssh工具
关闭防火墙
关闭配置好的这一台虚拟,克隆出另外3台
克隆出来的机器需要:
- 修改主机名
- 修改ip地址
- 修改物理网卡删掉eth0,改eth1为eth0,
2)安装HDFS软件
Hdfs/YARN是两个分布式服务系统,mapreduce是运算程序,这些软件通通包含在HADOOP安装包中。那么,我们在安装时,其实对每一台机器都是安装一个整体的HADOOP软件,只是将来会在不同的机器上启动不同的程序。
1/ 上传一个hadoop安装压缩包到hdp26-01上,解压到/root/apps/
2/ 认识hadoop软件的目录结构
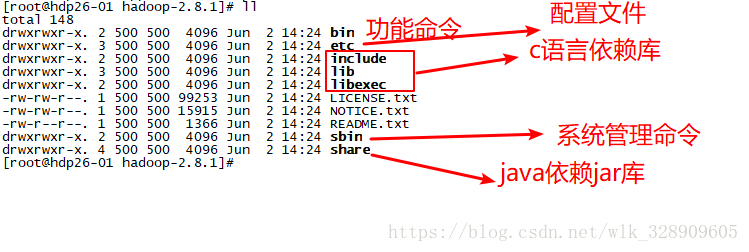
2/ 修改配置文件
hadoop-env.sh:
配置一个JAVA_HOME目录即可
| export JAVA_HOME=/root/apps/jdk1.8.0_60 |
core-site.xml
最核心配置:HDFS的URI
参数名: fs.defaultFS
参数值: hdfs://hdp26-01:9000/
| |
|
知 识 补 充 |
URI:全球统一资源定位,用于描述一个“资源”(一个网页/一个文件/一个服务)的访问地址; 举例:我有一个数据库,别人想访问,可以这样指定: jdbc:mysql://192.168.33.44:3306/db1 jdbc:mysql: 资源的类型或者通信协议 192.168.33.44:3306 服务提供者的主机名和端口号 /db1 资源体系中的某一个具体资源(库)
我有一个web系统,别人想访问,可以这样指定: http://www.ganhoo.top:80/index.php http: 资源的访问协议 www.ganhoo.top:80 服务提供者的主机名和端口号 /index.php 资源体系中的某一个具体资源(页面)
我要访问本地磁盘文件系统中的文件 file://d:/aa/bb/cls.avi file:///root/apps/..
|
hdfs-site.xml
核心配置:
- datanode服务软件在存储文件块时,放在服务器的磁盘的哪个目录
参数名:dfs.datanode.data.dir
参数值:/root/hdp-data/data/
- namenode 服务软件在记录文件位置信息数据时,放在服务器的哪个磁盘目录
参数名:dfs.namenode.name.dir
参数值:/root/hdp-data/name/
|
|
3/ 拷贝安装包到其他机器
在hdp26-01上:
scp -r /root/apps/hadoop-2.8.1 hdp26-02:/root/apps/
scp -r /root/apps/hadoop-2.8.1 hdp26-03:/root/apps/
scp -r /root/apps/hadoop-2.8.1 hdp26-04:/root/apps/
4/ 手动启动HDFS系统
|
知 识 补 充 |
为了能够在任意地方执行hadoop的脚本程序,可以将hadoop的安装目录及脚本所在目录配置到环境变量中:
在之前的配置文件中添加如下内容: vi /etc/profile export HADOOP_HOME=/root/apps/hadoop-2.8.1 export PATH= $PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后 source /etc/profile |
格式化namenode
首先,需要给namenode机器生成一个初始化的元数据存储目录
hadoop namenode -format
启动namenode
在哪里启动namenode:
在你配的fs.defaultFS=hdfs://hdp26-01:9000中的主机上启namenode
启动命令:
hadoop-daemon.sh start namenode
启动完后检查:
[liunx#] jps
2112 NameNode
使用浏览器访问hdp26-01的50070端口,能打开一个namenode状态信息的网页
启动datanode
在哪里启动datanode:
在你想让它成为datanode服务器的机器上启:
(hdp26-01,hdp26-02,hdp26-03,hdp26-04)
启动命令:
hadoop-daemon.sh start datanode
启动完后检查:
[liunx#] jps
2112 DataNode
<使用浏览器访问hdp26-01的50075端口,能打开一个datanode状态信息的网页>
刷新namenode的网页,看看是否识别出这一台datanode
DATANODE的存储目录不需要事先初始化,datanode软件在启动时如果发现这个存储目录不存在,则会自动创建
启完之后,浏览namenode页面,会发现namenode已经认出4个datanode服务器

5/ 脚本自动启动HDFS系统
|
知 识 补 充 |
ssh不仅可以远程登录一个linux服务器进行shell会话,还可以远程发送一条指令到目标机器上执行 ssh hdp26-04 “mkdir /root/test”
ssh hdp26-04 “source /etc/profile; hadoop-daemon.sh start datanode”
但是,远程发送指令执行需要经过ssh的安全验证: 验证分为两种方式:
需要在hdp26-01上生成一对密钥: ssh-keygen
然后将公钥发送到目标机器上: ssh-copy-id hdp26-01 ssh-copy-id hdp26-02 ssh-copy-id hdp26-03 ssh-copy-id hdp26-04 |
接着修改 hadoop安装目录/etc/hadoop/slaves文件,列入想成为datanode服务器的主机:
hdp26-01
hdp26-02
hdp26-03
hdp26-04
然后,就可以:
用start-dfs.sh 自动启动整个集群;
用stop-dfs.sh 自动停止整个集群;
| 集 群 常 见 错 误 |
不恰当的format:导致namenode上新生成了clusterid,跟datanode上记录的原clusterid不一致,导致datanode无法向namenode注册!
不恰当的复制(把某台datanode的数据目录复制给了另一台),导致两台datanode上记录的datanodeUUID重复冲突;左右只能有一台datanode能向namenode注册成功
忘记关防火墙,导致namenode无法从外界访问,也会导致datanode无法跟namenode通信
主机名忘了改! 配置文件写错! jdk都没安装好! |